潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
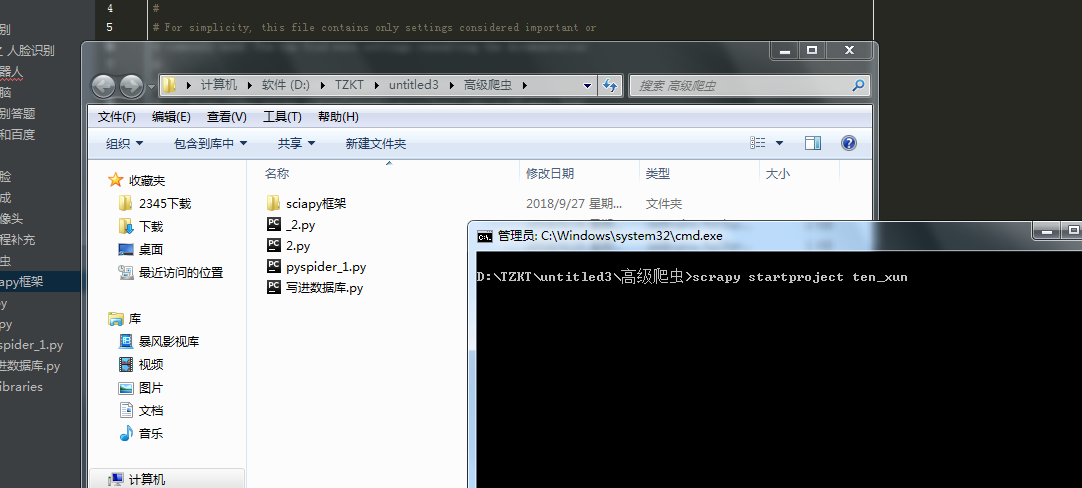
到指定目录下,创建个项目
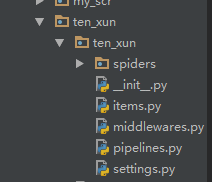
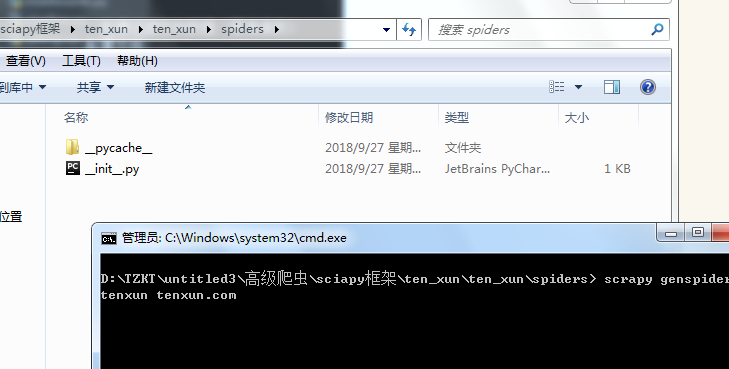
进到 spiders 目录 创建执行文件,并命名
运行调试
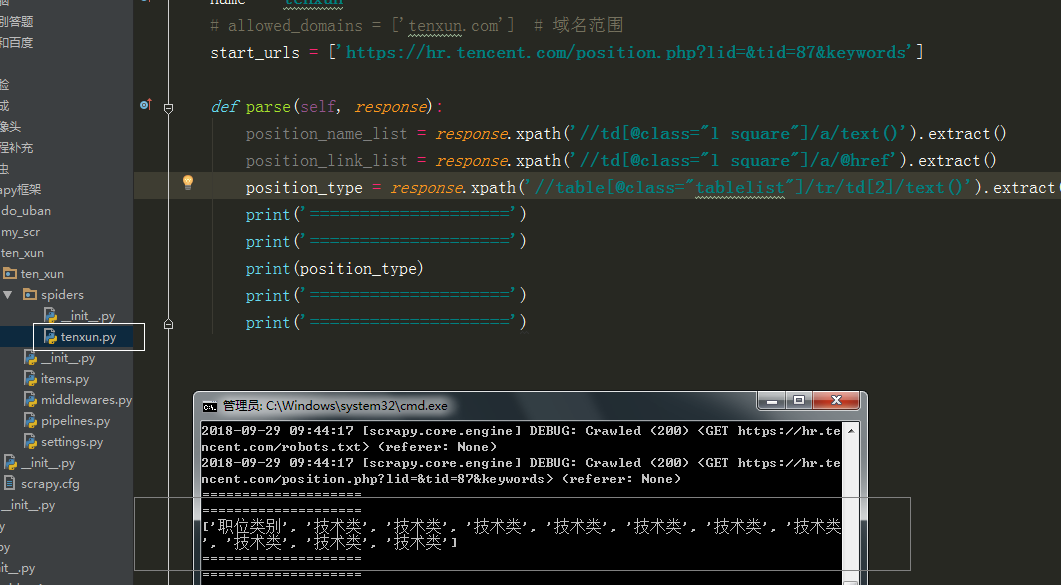
执行代码,:
# -*- coding: utf-8 -*-
import scrapy
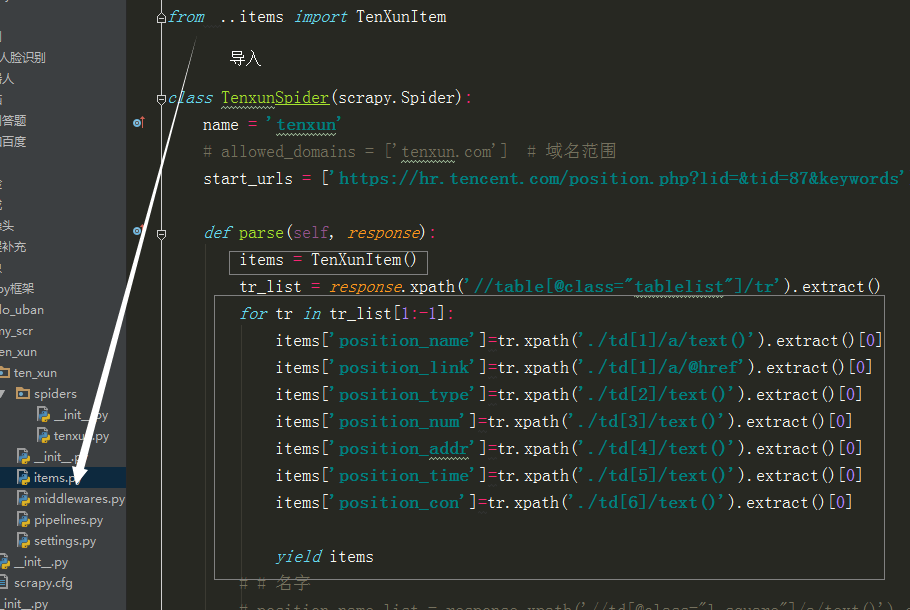
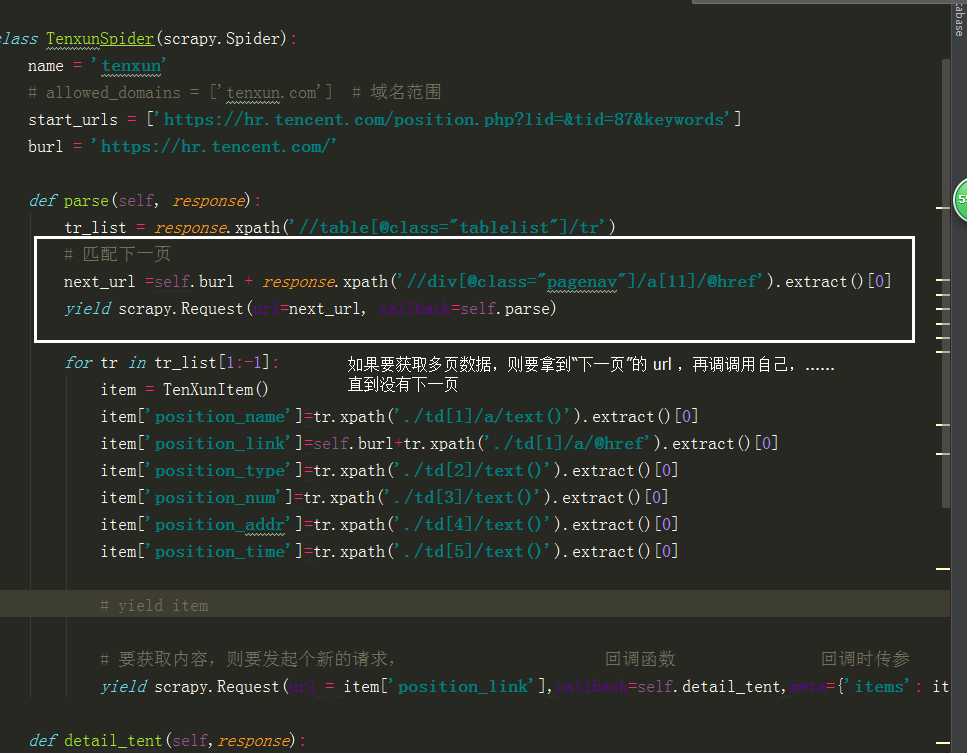
from ..items import TenXunItem class TenxunSpider(scrapy.Spider):
name = 'tenxun'
# allowed_domains = ['tenxun.com'] # 域名范围
start_urls = ['https://hr.tencent.com/position.php?lid=&tid=87&keywords']
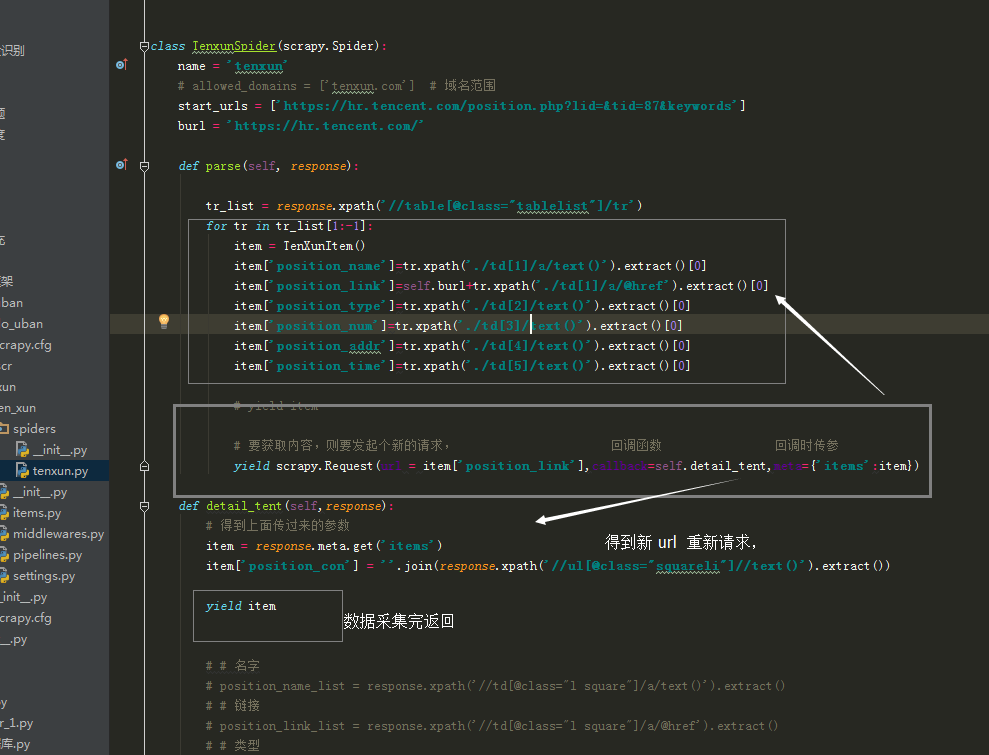
burl = 'https://hr.tencent.com/' def parse(self, response):
tr_list = response.xpath('//table[@class="tablelist"]/tr')
for tr in tr_list[1:-1]:
item = TenXunItem()
item['position_name']=tr.xpath('./td[1]/a/text()').extract()[0]
item['position_link']=self.burl+tr.xpath('./td[1]/a/@href').extract()[0]
item['position_type']=tr.xpath('./td[2]/text()').extract()[0]
item['position_num']=tr.xpath('./td[3]/text()').extract()[0]
item['position_addr']=tr.xpath('./td[4]/text()').extract()[0]
item['position_time']=tr.xpath('./td[5]/text()').extract()[0] # yield item # 匹配下一页
next_url =self.burl + response.xpath('//div[@class="pagenav"]/a[11]/@href').extract()[0]
yield scrapy.Request(url=next_url, callback=self.parse) # 要获取内容,则要发起个新的请求, 回调函数 回调时传参
yield scrapy.Request(url = item['position_link'],callback=self.detail_tent,meta={'items': item}) def detail_tent(self,response):
# 得到上面传过来的参数
item = response.meta.get('items')
item['position_con'] = ''.join(response.xpath('//ul[@class="squareli"]//text()').extract()) yield item # # 名字
# position_name_list = response.xpath('//td[@class="l square"]/a/text()').extract()
# # 链接
# position_link_list = response.xpath('//td[@class="l square"]/a/@href').extract()
# # 类型
# position_type_list = response.xpath('//table[@class="tablelist"]/tr/td[2]/text()').extract()
# # 人数
# position_num_list = response.xpath('//table[@class="tablelist"]/tr/td[3]/text()').extract()
# print('====================')
# print('====================')
# print(self.burl + tr_list[2].xpath('./td[1]/a/@href').extract()[0])
# print('====================')
# print('====================')
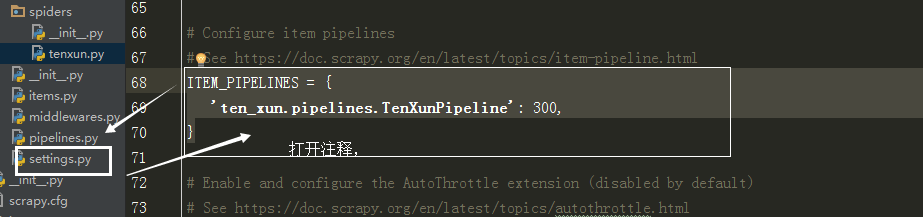
pipelines.py
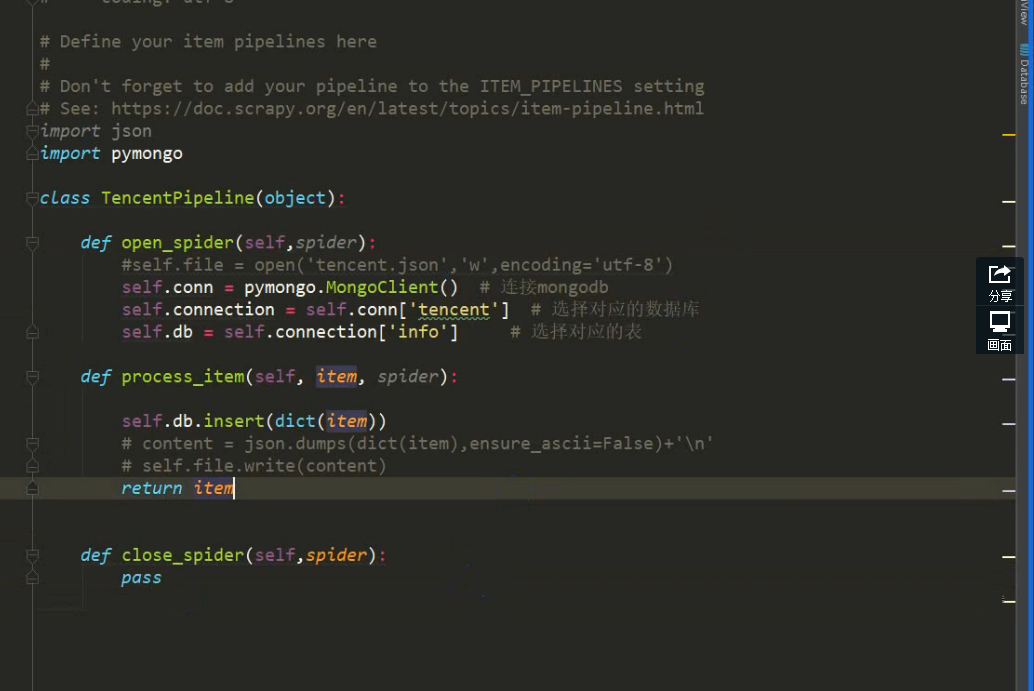
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
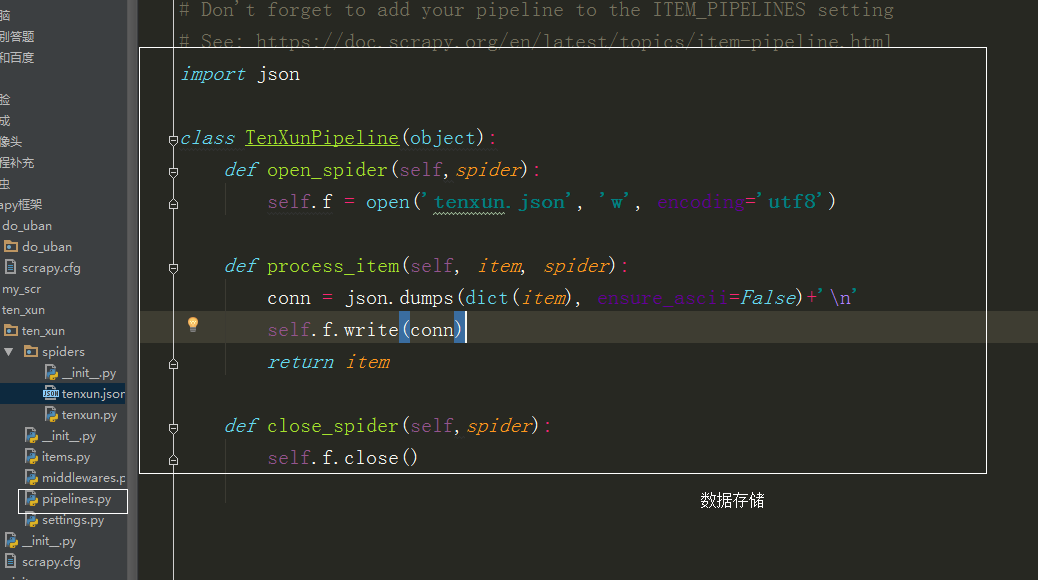
import json class TenXunPipeline(object):
def open_spider(self,spider):
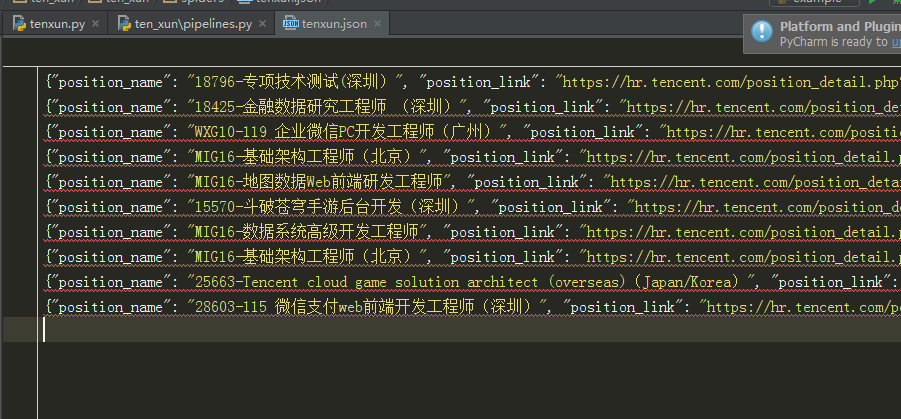
self.f = open('tenxun.json', 'w', encoding='utf8') def process_item(self, item, spider):
conn = json.dumps(dict(item), ensure_ascii=False)+'\n'
self.f.write(conn)
return item def close_spider(self,spider):
self.f.close()
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
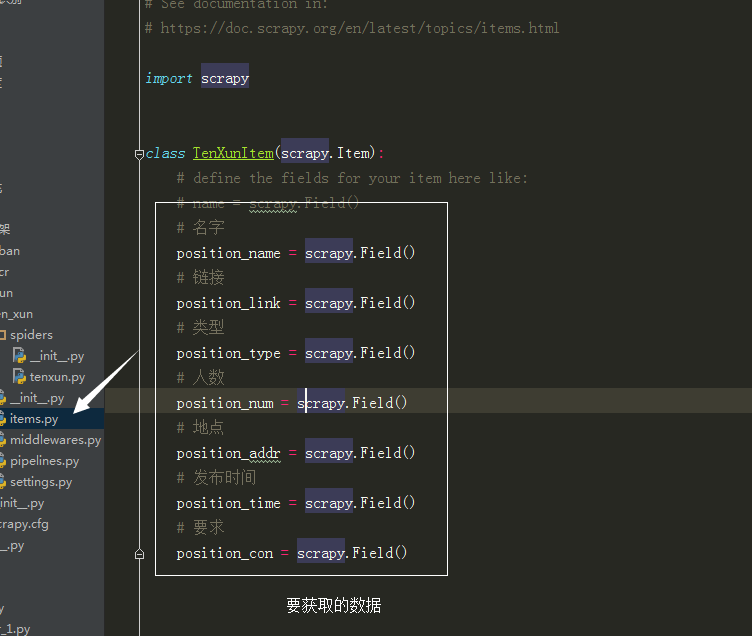
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class TenXunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 名字
print('00000000000000001111111111111111')
position_name = scrapy.Field()
# 链接
position_link = scrapy.Field()
# 类型
position_type = scrapy.Field()
# 人数
position_num = scrapy.Field()
# 地点
position_addr = scrapy.Field()
# 发布时间
position_time = scrapy.Field()
# 要求
position_con = scrapy.Field()
存入数据库:
潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫基础 第三课 urllib (课堂笔记)
Python网络请求urllib和urllib3详解 urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了url ...
随机推荐
- Expm 4_2 有向无环图中的最短路径问题
[问题描述] 建立一个从源点S到终点E的有向无环图,设计一个动态规划算法求出从S到E的最短路径值,并输出相应的最短路径. 解: package org.xiu68.exp.exp4; import j ...
- totastmessage 触发事件后浮框消失的方法
1. 前言 通过查了官放的文档,发现没有 totastmessage 触发事件后,浮框消失的方法,然后通过研究了下点击关闭时的源码,得到了一个的解决方案. 2. 样例代码如下 $("#dro ...
- K最近邻kNN-学习笔记
# -*- coding: utf-8 -*- """ Created on Thu Jan 24 09:34:32 2019 1. 翼尾花数据 2. 用 KNeighb ...
- OneNET麒麟座应用开发之八:采集大气压力等环境参数
采集大气压力和温度也是核算大气标准状况下的各种数据的必须参数,为此我们必须知道压力和温度才能计算标准状况下的各种参数,于此我们需要一个既能检测压力也能检测温度的元件. 1.硬件概述 MS5837压力传 ...
- ORACLE与SQLSERVER数据转换
前言: 将SQLServer数据库中的表和数据全量导入到Oracle数据库,通过Microsoft SqlServer Management Studio工具,直接导入到oracle数据库,免去了生成 ...
- 如何理解深度学习中的Transposed Convolution?
知乎上的讨论:https://www.zhihu.com/question/43609045?sort=created 不过看的云里雾里,越看越糊涂. 直到看到了这个:http://deeplearn ...
- navicat连接sqlserver数据库提示:未发现数据源名称并且未指定默认驱动程序
原因是navicat没有安装sqlserver驱动,就在navicat安装目录下,找到双击安装即可:
- jmeter在返回的json串中提取需要的值
接口测试时我们需要对某条信息进行修改,如我们先创建了一篇文章,然后进行修改操作 我们就需要找到该文章的唯一标志,如id 示例:我们要将下图返回的json 中id进行提取 注:可输入$.加需要的key即 ...
- WCF简介-01
WCF Windows Communication Foundation 1.1 新建一个"空白解决方案" 1.2 在解决方案中添加类库IBLL 1.2.1 添加接口IUserIn ...
- 二.hadoop环境搭建
目录: 目录见文章1 文章:官方文档hadoop2.7.4 目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有 ...