潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享,
scrapy 调度 基于文件每户,默认只能在单机运行,
scrapy-redis 默认把数据放到 redis 中,实现数据共享,
安装: pip install scrapy-redis
命令与 scrapy 没有不同

在该文件下导入 scrapy_redis

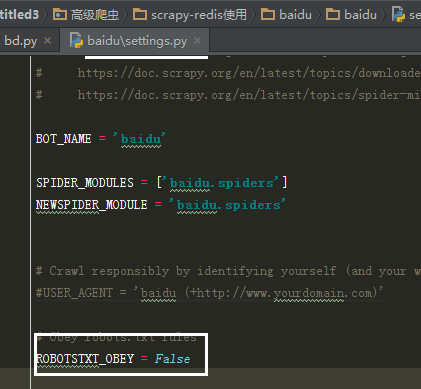
在配置文件中添加内容
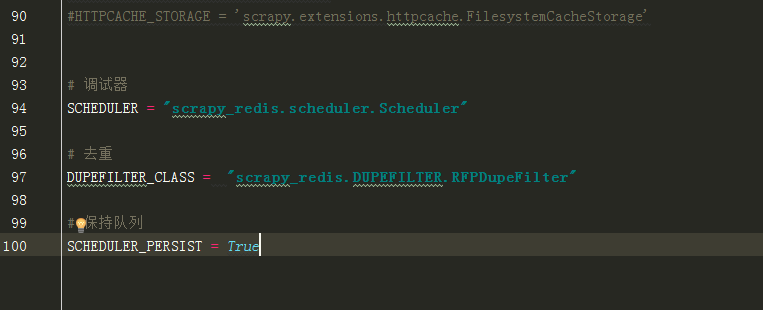
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而True允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
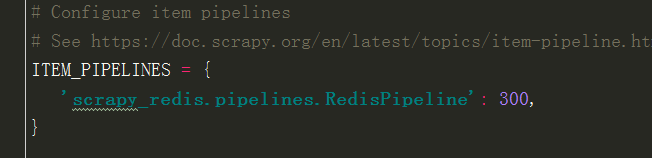
4(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item
这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100
}
5(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
这里要改下

改成
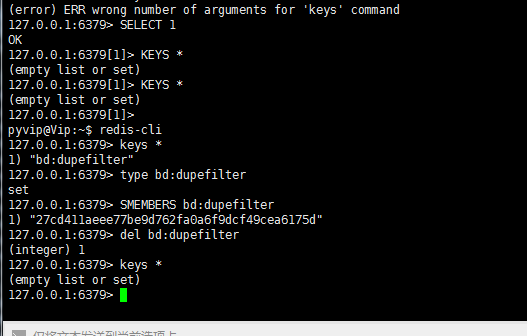

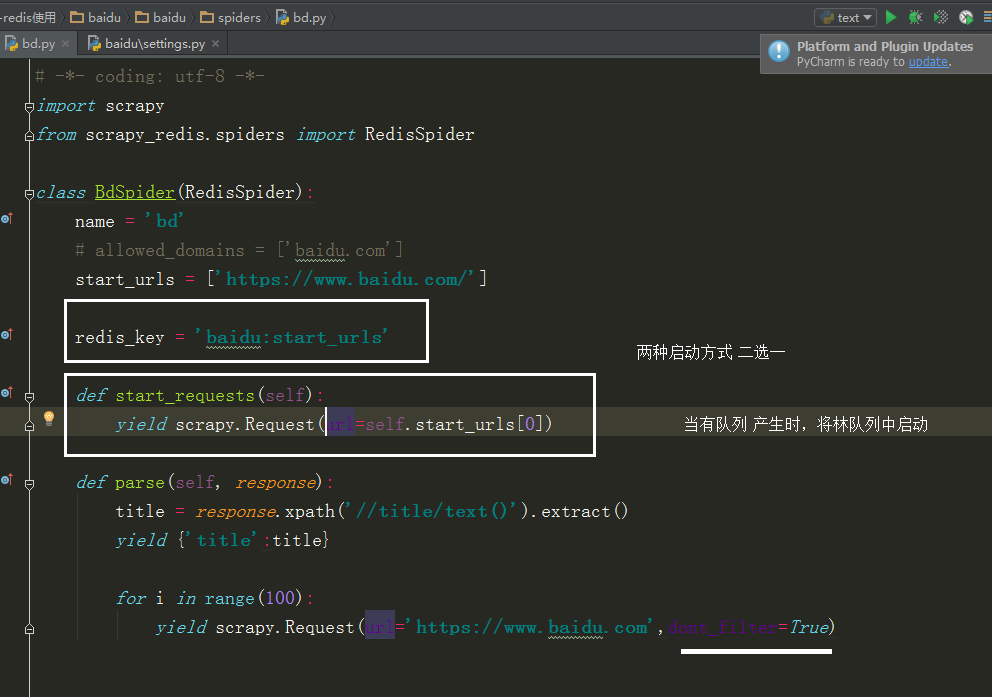
当选择 redis_key 启动时,会从 redis 中获取 url
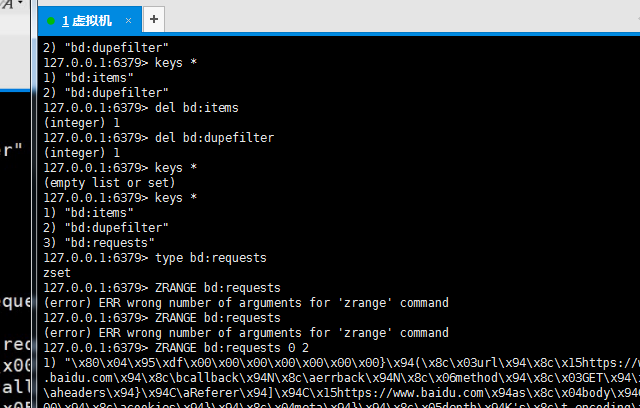
所以在 redis 中用到下面这个命令,才会启动

redis 中查队列

潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十二 课 Scrapy-redis分布 项目实战 (课堂笔记)
建代理池, 1,获取多个网站的免费代理IP, 2,对免费代理进行检测,>>>>>携带IP进行请求, 3,检测到的可用IP进行存储, 4,实现api接口,方便调用, 5,各 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
随机推荐
- DoNetZip类库解压和压缩文件
using Ionic.Zip; public class ZipHelper { public static void ZipSingleFile(string zipPath) { try { u ...
- Install zeal on ubuntu16.04
Dash is a helpful software for macOS users. For Windows and Linux users, zeal is the open-source cou ...
- 在th中显示图片
从DataTable中获取值: foreach (DataRow dr in ((DataTable)ViewBag.bookInfoList).Rows) { <tr> <th c ...
- 【Maven】Select Dependency 无法检索
问题: 在 “pom.xml” 中,点击 “Dependencies” -> “Add” 添加依赖时,无法检索. 如下图所示: 解决办法: 依次点击 “Windows”->“Show ...
- npm报错没有权限
在npm install经常会报错没有权限 这个时候需要清除一下缓存 npm cache clean --force
- aws上ecs上tomcat8080端口打开但是无法访问
参考: https://yq.aliyun.com/articles/92050?t=t1 1. 安全组设置 2. 防火墙规则 3. 查看 8080 端口是否绑定到 127.0.0.1上的.如果是 ...
- 事件(Event)(onclick,onchange,onload,onunload,onfocus,onblur,onselect,onmuse)【转载】
ylbtech-Event:事件(Event)对象 事件(Event) HTML 4.0 事件属性 onclick onchange onload onunload onselect onmouse ...
- 071 SparkStreaming与SparkSQL集成
1.说明 虽然DStream可以转换成RDD,但是如果比较复杂,可以考虑使用SparkSQL. 2.集成方式 Streaming和Core整合: transform或者foreachRDD方法 Cor ...
- js實現彈窗
strSucc += "<br/><font color=\"red\">提醒您!在預設狀態下,Google Chrome 會阻止彈出式視窗自動在 ...
- word,excel,ppt在线预览功能
我们在开发web项目时,尤其类似oa功能时总会遇到上传附件并在线预览的功能,发现一款api比较好使,下面简单介绍一下. 微软官网本身提供了在线预览的API 首先将要预览的文档转成.docx,.xlsx ...