独树一帜的字符串匹配算法——RK算法
参加了雅虎2015校招,笔试成绩还不错,谁知初面第一题就被问了个字符串匹配,要求不能使用KMP,但要和KMP一样优,当时瞬间就呵呵了。后经过面试官的一再提示,也还是没有成功在面试现场写得。现将该算法记录如下,思想绝对是字符串匹配中独树一帜的
字符串匹配
存在长度为n的字符数组S[0...n-1],长度为m的字符数组P[0...m-1],是否存在i,使得SiSi+1...Si+m-1等于P0P1...Pm-1,若存在,则匹配成功,若不存在则匹配失败。
RK算法思想
假设我们有某个hash函数可以将字符串转换为一个整数,则hash结果不同的字符串肯定不同,但hash结果相同的字符串则很有可能相同(存在小概率不同的可能)。
算法每次从S中取长度为m的子串,将其hash结果与P的hash结果进行比较,若相等,则有可能匹配成功,若不相等,则继续从S中选新的子串进行比较。
假设进行下面的匹配:
| S0 | S1 | ... | Si-m+1 | Si-m+2 | ... | Si-1 | Si | Si+1 | ... | Sn-1 |
| P0 | P1 | Pm-2 | Pm-1 |
情况一、hash(Si-m+1...Si) == hash(P0...Pm-1),此时Si-m+1...Si与P0...Pm-1有可能匹配成功。只需要逐字符对比就可以判断是否真的匹配成功,若匹配成功,则返回匹配成功点的下标i-m+1,若不成功,则继续取S的子串Si-m+2...Si+1进行hash
情况二、hash(Si-m+1...Si) != hash(P0...Pm-1),此时Si-m+1...Si与P0...Pm-1不可能匹配成功,所以继续取S的子串Si-m+2...Si+1进行hash
可以看出,不论情况一还是情况二,都涉及一个共同的步骤,就是继续取S的子串Si-m+2...Si+1进行hash。如果每次都重新求hash结果的话,复杂度为O(m),整体复杂度为O(mn)。如果可以利用上一个子串的hash结果hash(Si-m+1...Si),在O(1)的时间内求出hash(Si-m+2...Si+1),则可以将整体复杂度降低到线性时间
至此,问题的关键转换为如何根据hash(Si-m+1...Si),在O(1)的时间内求出hash(Si-m+2...Si+1)
设计hash函数为:hash(Si-m+1...Si) = Si-m+1*xm-1 + Si-m+2*xm-2 + ... + Si-1*x + Si
则 hash(Si-m+2...Si+1) = Si-m+2*xm-1 + Si-m+3*xm-2 + ... + Si*x + Si+1
= (hash(Si-m+1...Si) - Si-m+1*xm-1) * x + Si+1
hash结果过大怎么办?对某个大素数取余数即可(经典方法),称其为HASHSIZE
所以,hash函数更新为:hash(Si-m+1...Si) = (Si-m+1*xm-1 + Si-m+2*xm-2 + ... + Si-1*x + Si) % HASHSIZE
则 hash(Si-m+2...Si+1) = (Si-m+2*xm-1 + Si-m+3*xm-2 + ... + Si*x + Si+1) % HASHSIZE
= ((hash(Si-m+1...Si) - Si-m+1*xm-1) * x + Si+1) % HASHSIZE
设计算法时需要注意的几点:
1、可提前计算出hash(P0...Pm-1)和xm-1并保存
2、char c 的取值范围为0~255,计算hash结果时会自动类型提升为int,为避免符号位扩展,使用 (unsigned int)c & 0x000000FF
3、hash(Si-m+1...Si) - Si-m+1*xm-1 的结果可能为负数,需先加上 Si-m+1*HASHSIZE 并最后 % HASHSIZE 来保证结果非负
具体代码如下:
#define UNSIGNED(x) ((unsigned int)x & 0x000000FF)
#define HASHSIZE 10000019 int hashMatch(char* s, char* p) {
int n = strlen(s);
int m = strlen(p);
if (m > n || m == || n == )
return -;
// sv为S子串的hash结果,pv为字符串p的hash结果,base为x的m-1次方
unsigned int sv = UNSIGNED(s[]), pv = UNSIGNED(p[]), base = ;
int i, j;
// 初始化 sv, pv, base
for (i = ; i < m; i++) {
pv = (pv * + UNSIGNED(p[i])) % HASHSIZE;
sv = (sv * + UNSIGNED(s[i])) % HASHSIZE;
base = (base * ) % HASHSIZE;
}
i = m - ;
do {
// 情况一、hash结果相等
if (sv == pv) {
for (j = ; j < m && s[i - m + + j] == p[j]; j++)
;
if (j == m)
return i - m + ;
}
i++;
if (i >= n)
break;
// O(1)时间更新S子串的hash结果
sv = (sv + UNSIGNED(s[i - m]) * (HASHSIZE - base)) % HASHSIZE;
sv = (sv * + UNSIGNED(s[i])) % HASHSIZE;
} while (i < n); return -;
}
时间复杂度分析:循环复杂度O(n),hash结果相等时的逐字符匹配复杂度为O(m),整体时间复杂度为O(m+n)。空间复杂度为O(1)
运行时间PK
随机生成10亿字节(1024*1024*1023)的字符串保存到文件num.txt中,读出到字符串S中,P长度为1024*10字节,分别使用RK算法和KMP算法进行实验
从文件num.txt中读取字符串到S中所需时间为:
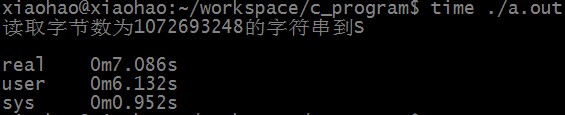
匹配成功时,RK算法匹配所需时间为:
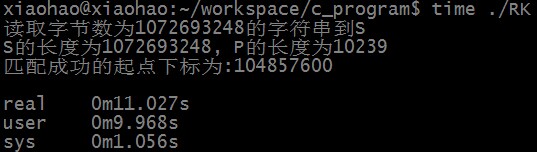
匹配成功时,KMP算法匹配所需时间为:
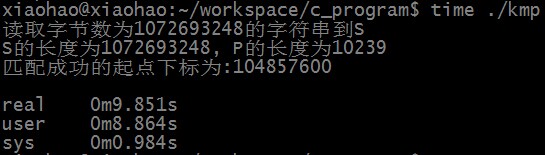
匹配不成功时,RK算法匹配所需时间为:
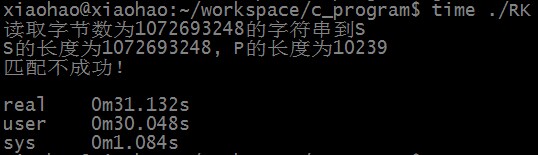
匹配不成功时,KMP算法匹配所需时间为:
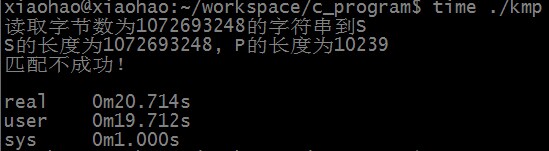
可以看出,RK算法和KMP算法均可以在线性时间内完成匹配,RK算法时间稍慢的原因主要有两点,一是数学取模运算,二是hash结果相同不一定完全匹配,需要再逐字符进行对比。统计hash结果相等但字符串不一定匹配的情况发现,匹配不成功时有105次hash结果相等但字符串不匹配的情况。S中长度为10239的子串个数大约为10亿,所以hash结果相等但不匹配的概率大约为一千万分之一(刚好约等于1/HASHSIZE),所以时间复杂度精确值应为O(n) + O(m*n/HASHSIZE)。
算法优化
在上面的测试中RK算法还是慢于KMP的,优化从两点出发:一是用其他运算代替取模运算,二是降低hash冲突。
先解决降低冲突的问题,在之前的代码中,我们使用了x=10,假设存在char值为2,20,200的三个字符a,b,c,可以发现a*1000,b*100,c*10的hash结果是相同的,也就是发生了冲突,所以取大于等于256的数做x则可以避免这种冲突。另外HASHSIZE的大小也会决定冲突发生的概率,HASHSIZE最大可以多大呢?对于unsigned int来说,总共有2^32次方个,所以可以取HASHSIZE为2^32次方。而计算机对于大于等于2^32次方的数会自动舍弃高位,其刚好等价于对2^32次方取模,即对HASHSIZE取模,所以便可以从代码中去掉取模运算。
优化后的代码如下(代码中d即上文中的x):
#define UNSIGNED(x) ((unsigned char)x)
#define d 257 int hashMatch(char* s, char* p) {
int n = strlen(s);
int m = strlen(p);
if (m > n || m == || n == )
return -;
// sv为s子串的hash结果,pv为p的hash结果,base为d的m-1次方
unsigned int sv = UNSIGNED(s[]), pv = UNSIGNED(p[]), base = ;
int i, j;
int count = ;
// 初始化sv, pv, base
for (i = ; i < m; i++) {
pv = pv * d + UNSIGNED(p[i]);
sv = sv * d + UNSIGNED(s[i]);
base = base * d;
}
i = m - ;
do {
// 情况一,hash结果相等
if (!(sv ^ pv)) {
for (j = ; j < m && s[i - m + + j] == p[j]; j++)
;
if (j == m)
return i - m + ;
}
i++;
if (i >= n)
break;
// O(1)时间内更新sv, sv + UNSIGNED(s[i - m]) * (~base + 1)等价于sv - UNSIGNED(s[i - m]) * base
sv = (sv + UNSIGNED(s[i - m]) * (~base + )) * d + UNSIGNED(s[i]);
} while (i < n); return -;
}
匹配成功时,优化后RK算法匹配所需时间为:
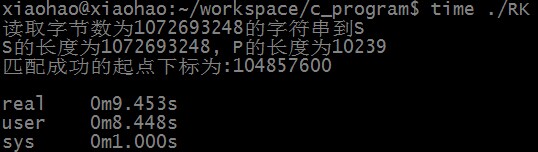
匹配不成功时,优化后RK算法匹配所需时间为:
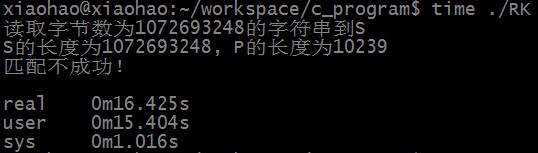
可以看出,优化后的RK算法已经在时间上优于KMP了。而且大小为2^32次方的HASHSIZE也保证了S的10亿个子串基本不会发生冲突。
独树一帜的字符串匹配算法——RK算法的更多相关文章
- 字符串匹配算法 -- Rabin-Karp 算法
字符串匹配算法 -- Rabin-Karp 算法 参考资料 1 算法导论 2 lalor 3 记忆碎片 Rabin-karp 算法简介 在实际应用中,Rabin-Karp 算法对字符串匹配问题能较好的 ...
- 字符串匹配算法——KMP算法
处理字符串的过程中,难免会遇到字符匹配的问题.常用的字符匹配方法 1. 朴素模式匹配算法(Brute-Force算法) 求子串位置的定位函数Index( S, T, pos). 模式匹配:子串的定位操 ...
- 字符串匹配算法——KMP算法学习
KMP算法是用来解决字符串的匹配问题的,即在字符串S中寻找字符串P.形式定义:假设存在长度为n的字符数组S[0...n-1],长度为m的字符数组P[0...m-1],是否存在i,使得SiSi+1... ...
- 字符串匹配算法KMP算法
数据结构中讲到关于字符串匹配算法时,提到朴素匹配算法,和KMP匹配算法. 朴素匹配算法就是简单的一个一个匹配字符,如果遇到不匹配字符那么就在源字符串中迭代下一个位置一个一个的匹配,这样计算起来会有很多 ...
- [Algorithm] 字符串匹配算法——KMP算法
1 字符串匹配 字符串匹配是计算机的基本任务之一. 字符串匹配是什么?举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串& ...
- 字符串匹配算法-kmp算法
一原理: 部分转自:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html 字 ...
- 字符串匹配算法--Brute-Force算法
Brute-Force(暴力)算法是字符串匹配中最简单也是最容易理解的算法. 主要思想是 按顺序遍历母串,将每个字符作为匹配的起始字符,判断是否匹配字串.若第一个字符与字串匹配,则比较下一个字符,否则 ...
- Python 细聊从暴力(BF)字符串匹配算法到 KMP 算法之间的精妙变化
1. 字符串匹配算法 所谓字符串匹配算法,简单地说就是在一个目标字符串中查找是否存在另一个模式字符串.如在字符串 "ABCDEFG" 中查找是否存在 "EF" ...
- Sunday算法:字符串匹配算法进阶
背景 我们第一次接触字符串匹配,想到的肯定是直接用2个循环来遍历,这样代码虽然简单,但时间复杂度却是\(Ω(m*n)\),也就是达到了字符串匹配效率的下限.于是后来人经过研究,构造出了著名的KMP算法 ...
随机推荐
- nginx如何解决超长请求串
nginx是一个强大的http服务器,但是在使用过程中发现,当遇到超长的post请求或者get请求时,nginx会返回413.400.414等状态码,这是因为请求串长度超过了nginx默认的缓存大小或 ...
- 多线程(一)NSThread
iOS中多线程的实现方案: 技术 语言 线程生命周期 使用频率 pthread C 程序员自行管理 几乎不用 NSthread OC 程序员自行管理 偶尔使用 GCD C 自动管理 经常使用 NSOp ...
- 【mysql的设计与优化专题(3)】字段类型与合理的选择字段类型
本篇博客稍微有点长,它实际上包括两个内容:一是mysql字段类型的介绍,二是在mysql建表过程中是如何正确选择这些字段类型; 字段类型 数值 MySQL 的数值数据类型可以大致划分为两个类别,一个是 ...
- mpi冒泡排序并行化
一.实验目的与实验要求 1.实验目的 (1)学会将串行程序改为并行程序. (2)学会mpich2的使用. (3)学会openmp的配置. (4)mpi与openmp之间的比较. 2.实验要求 (1)将 ...
- Mac与Linux的一个巨大不同
就是Mac仍处在桌面市场的商业圈里,尽管它的市场很小,但是正版率却很高,而且还有专门的Mac Store提供付费下载. Linux在桌面市场几乎没有份额,也不会有人会去买它的应用软件,基本上只存在于服 ...
- 好用的linux命令
sudo chown -R `whoami` /usr/local # ps aux |grep php-fpm php-frm start and stop php-fpm -D killall p ...
- 最短路径算法之二——Dijkstra算法
Dijkstra算法 Dijkstra算法主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止. 注意该算法要求图中不存在负权边. 首先我们来定义一个二维数组Edge[MAXN][MAXN]来存储 ...
- itoa函数的实现(不同进制)
2013-07-08 17:12:30 itoa函数相对于atoi函数,比较简单,还是要注意考虑的全面. 小结: 一下几点需要考虑: 对负数,要加上负号: 考虑不同进制,根据要求进行处理:对不同的进制 ...
- NFC(11)MifareUltralight格式规范及读写示例
注意 MifareUltralight 不支三种过滤方式之一,只支持第四种(用代码,activity singleTop ) 见 NFC(4)响应NFC设备时启动activity的四重过滤机制 Mi ...
- 1650. Billionaires(线段树)
1650 简单题 线段树的单点更新 就是字符串神马的 有点小繁琐 开两个map 一个存城市 一个存名字 #include <iostream> #include<cstdio> ...