本文讲的是如何使用zookeeper将solr分布式部署,也可以理解为tomcat分布式部署。
为什么要使用zookeeper,请参考文章《Solr的SolrCloud与Master-slave主从模式对比》http://blog.csdn.net/jiangchao858/article/details/53363310
尚未成功启动solr的,请看我的另一篇文章《solr6.4.1 搜索引擎(1)启动eclipse启动》http://www.cnblogs.com/zhuwenjoyce/p/6506359.html
solr尚未首次同步数据库的,请看我的另一篇文章《solr6.4.1搜索引擎(2)首次同步mysql数据库》http://www.cnblogs.com/zhuwenjoyce/p/6512378.html
1,安装JDK1.8
2,下载zookeeper3.4.9
zookeeper官方版本下载地址: http://apache.fayea.com/zookeeper/
官方版本已经更新到zookeeper-3.5.2-alpha,但是是alpha内部测试版,所以我们下载一个稳定版本zookeeper-3.4.9就可以了
http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz (22M)
3,下载solr6.4.1地址:http://archive.apache.org/dist/lucene/solr/ (149M)
4,下载tomcat8.0.28
http://archive.apache.org/dist/tomcat/tomcat-8/v8.0.28/bin/apache-tomcat-8.0.28.zip
一、solr集群准备
我在本机上模拟多台机器上的solr集群,所以是伪集群,新建目录如下:
D:\solr\solrCloud1 存放solr云的目录
D:\solr\solrCloud1\conf 存放solr云配置文件的目录,把D:\solr\solr-6.4.1\server\solr\configsets\sample_techproducts_configs\conf该目录下所有配置文件移动到该目录下
D:\solr\solrMachine1\ 代替原本需要真实集群的第一台机器目录
D:\solr\solrMachine2\ 代替原本需要真实集群的第二台机器目录
二、第一台机器集群准备
1)添加一个tomcat,端口号为9080,D:\solr\solrMachine1\apache-tomcat-8.0.28-9080
2)发布solr应用到该tomcat的webapp下,可以用war形式或者eclipse形式,可以参考我的文章《solr6.4.1 搜索引擎(1)启动eclipse启动》http://www.cnblogs.com/zhuwenjoyce/p/6506359.html
3)添加一个solrhome : D:\solr\solrMachine1\solrhome
4)修改D:\solr\solrMachine1\solrhome\solr.xml,把<int name="hostPort">${jetty.port:8983}</int>改为<int name="hostPort">${jetty.port:9080}</int>,因为solrhome的启动端口要与tomcat保持一致
5)修改tomcat的webapps目录下的solr应用的WEB-INF/web.xml(D:\solr\solrMachine1\apache-tomcat-8.0.28-9080\webapps\solr),solrhome的目录修改如下:
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/solr/solrMachine1/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
6)修改tomcat的D:\solr\solrMachine1\apache-tomcat-8.0.28-9080\bin\catalina.bat设置,使之可以被zookeeper识别,在setlocal之后换行添加如下内容:
set JAVA_OPTS=-Dbootstrap_confdir=D:/solr/solrCloud1/conf -Dcollection.configName=cloudconf -DzkHost=127.0.0.1:2181 -DnumShards=2
参数说明:
-Dbootstrap_confdir 告诉zookeeper,solr云的配置文件存放目录在哪儿。PS: 主tomcat需要告诉zookeeper solr云的配置文件在哪儿
-Dcollection.configName 自定义一个config的名字
-DzkHost 告诉solr你的zookeeper部署在哪个IP上哪个端口
三、第二台机器集群准备
1)添加一个tomcat,端口号为9081,D:\solr\solrMachine2\apache-tomcat-8.0.28-9081
3)添加一个solrhome : D:\solr\solrMachine2\solrhome
4)修改D:\solr\solrMachine2\solrhome\solr.xml,把<int name="hostPort">${jetty.port:8983}</int>改为<int name="hostPort">${jetty.port:9081}</int>,因为solrhome的启动端口要与tomcat保持一致
5)修改tomcat的webapps目录下的solr应用的WEB-INF/web.xml(D:\solr\solrMachine2\apache-tomcat-8.0.28-9081\webapps\solr2),solrhome的目录修改如下:
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>D:/solr/solrMachine2/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
6)修改tomcat的D:\solr\solrMachine2\apache-tomcat-8.0.28-9081\bin\catalina.bat设置,使之可以被zookeeper识别,在setlocal之后换行添加如下内容:
set JAVA_OPTS=-DzkRun -DzkHost=localhost:2181
参数说明:
-DzkRun 该参数将促使一个内嵌的 zookeeper 服务作为 Solr 服务的部分运行起来。
-DzkHost 告诉solr你的zookeeper部署在哪个IP上哪个端口
PS: 从tomcat不需要告诉zookeeper solr云的配置文件在哪儿,可以有多个tomcat都照此配置。
四、伪集群tomcat的准备工作
因为这里是伪集群,所以同时部署在同一个机器上的两个tomcat,端口必然不能重复:
D:\root\tomcat\apache-tomcat-8.0.28-9080 --端口9080,把8005和8009端口分别改为9001,9002
D:\root\tomcat\apache-tomcat-8.0.28-9081 --端口9081,把8005和8009端口分别改为9003,9004
到现在为止,我们已经使用-DzkHost=localhost:2181配置好了两个tomcat关联到zookeeper
五、zookeeper准备工作
下载后解压到目录D:/zookeeper-3.4.9
复制D:\zookeeper-3.4.9\conf\zoo_sample.cfg为zoo.cfg,修改zoo.cfg:
dataDir=D:/zookeeper-3.4.9/data --这里修改为实际的data数据目录
zookeeper的默认启动端口为2181
六、启动solr云
1)启动zookeeper3.4.9 D:\zookeeper-3.4.9\bin\zkServer.cmd
2)启动主tomcat D:\solr\solrMachine1\apache-tomcat-8.0.28-9080\bin\startup.bat
3)启动从tomcat D:\solr\solrMachine2\apache-tomcat-8.0.28-9081\bin\startup.bat
启动之后命令行窗口好多的打印!也不知道在打印个什么东西,第一次启动的时候我以为是solr应用在上传数据到zookeeper,因为我的solr索引已经达到110多万,后来我把索引数据清空了,还是有很多打印,不太明白为什么zookeeper在干什么。
七、访问solr云
在启动成功之后,随意访问任何一个tomcat,都可以查看到solr云已经成功显示,我这里访问的是http://localhost:9081/solr/index.html
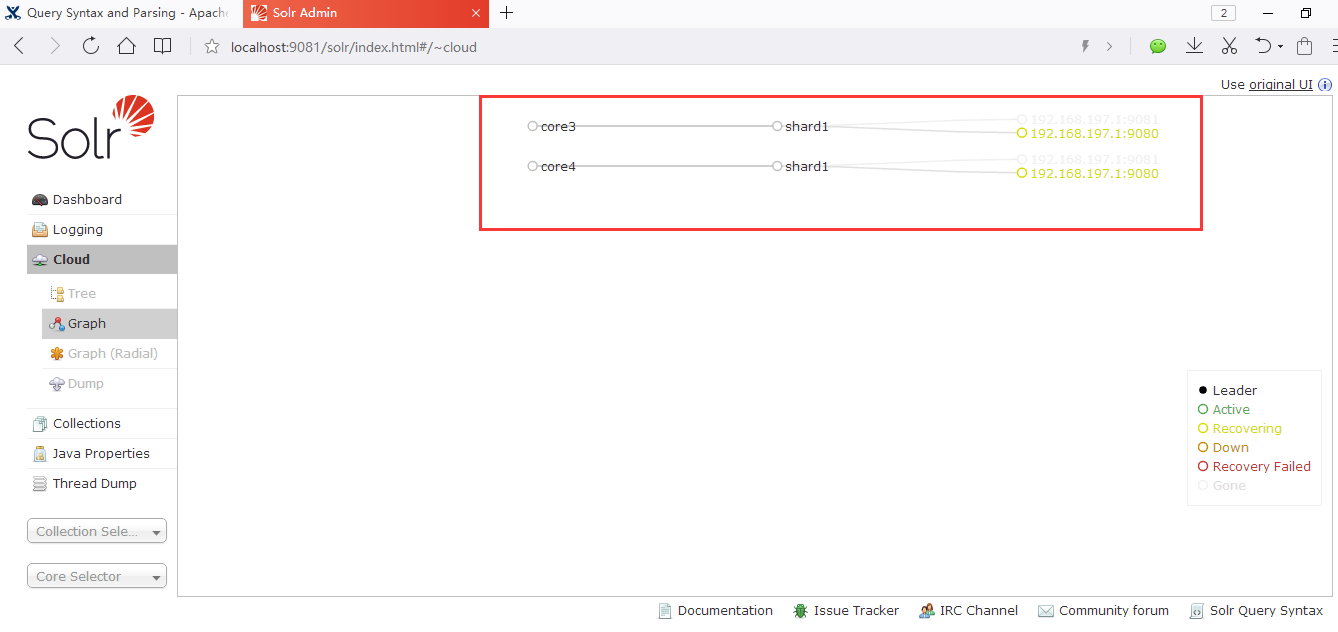
点击Cloud菜单后,默认会进入Graph视图,该视图显示如下:
可以看到9080和9081两个分布式节点已经成功部署。
八、solr云失败频率高
不知道是本地内存不够还是zookeeper或者solr没有优化好,只要我点击Cloud菜单下的Tree或者Graph(Radial)子菜单,就一定会出现各种假死:
一个节点已经死了,另一个节点正在艰难恢复中。 ╯﹏╰
- Solr5.2.1+Zookeeper3.4.8分布式集群搭建
1.选取三台服务器 由于机器比较少,现将zookeeper和solr都部署在以下三台机器上.(以下操作都是在172.16.20.101主节点上进行的哦) 172.16.20.101 主节点 172.1 ...
- Solr5.2.1+Zookeeper3.4.9分布式集群搭建
1.选取三台服务器 由于机器比较少,现将zookeeper和solr都部署在以下三台机器上.(以下操作都是在172.16.20.101主节点上进行的哦) 172.16.20.101 主节点 172.1 ...
- Zookeeper3.4.9分布式集群安装
一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh/p/6623530.html 二.文件准备 2.1 文件名称 zookeeper-3.4.9.ta ...
- ubuntu1.4搭建zookeeper3.5.2分布式集群
1.下载 官网链接:http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.5.2-alpha/zookeeper-3.5.2-alpha.ta ...
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- 分布式Apache ZooKeeper-3.4.6集群安装
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3900253.html Apache ZooKeeper是一个为分布式应用所设计的开源协 ...
- 注册中心zookeeper-3.4.6集群以及高可用
zookeeper是什么 百度定义: ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件. 它是一个为 ...
随机推荐
- MySQL 导出用户权限
Version <= 5.6 #!/bin/bash #Function export user privileges source /etc/profile pwd=****** expgra ...
- React Native 开发日常、常见问题总结及解决
优点: 1.写 UI 快,跟写 HTML 差不多,flex 布局写起来很爽,而且跨平台: 2.调试方便,command + R 直接刷新 Simulator,不用像 Xcode 等待编译: 3.体验好 ...
- keepalived高可用集群。
keepalived故障切换转移原理1vrrp协议:(vritual router redundancy protocol)虚拟路由冗余协议,2故障转移.keepalived三大功能1实现物理高可用, ...
- Mysql 编译安装脚本
cat mysql_init.sh##安装mariadb依赖包function install_yum(){ yum -y install $1}i="ncurses* bison gcc ...
- .net core 使用 ef core
第一步: 创建一个.net core console app. 第二步:安装EFCore package 和 design(以前vs是有EF项目模板的,core版本现在没有,所有安装这个工具来创建M ...
- js 面试知识点
基础 原型 原型链 作用域 闭包 异步 单线程 JS API DOM操作 AJAX 事件绑定 开发环境 版本管理 模块化 打包工具 运行环境 页面渲 ...
- jq demo 轮播图,图片可调用,向左,自动+鼠标点击切换
<!doctype html> <html> <head> <meta http-equiv="Content-Type" content ...
- Java语法基础学习DayEleven(Map)
一.Map接口 1.概述:Map与Collection并列存在,用于保存具有映射关系的数据Key-Value. Map接口 |- - - - -HashMap:Map的主要实现类 |- - - - - ...
- python+appium 自动化1--启动手机京东app
出处:https://www.cnblogs.com/yoyoketang/p/6128735.html 前言: 环境搭建好了.接下来先体验下如何启动app--1.首先获取包名:2.然后获取launc ...
- 18-10-09 Linux常用命令大全(非常全!!!)
Linux常用命令大全(非常全!!!) Linux常用命令大全(非常全!!!) 最近都在和Linux打交道,感觉还不错.我觉得Linux相比windows比较麻烦的就是很多东西都要用命令来控制, ...