Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
1.安装步骤:
首先,你要先进入pycharm的Project Interpreter界面,进入方法是:setting(ctrl+alt+s) ->Project Interpreter,Project Interpreter在具体的Project下。如下图所示:
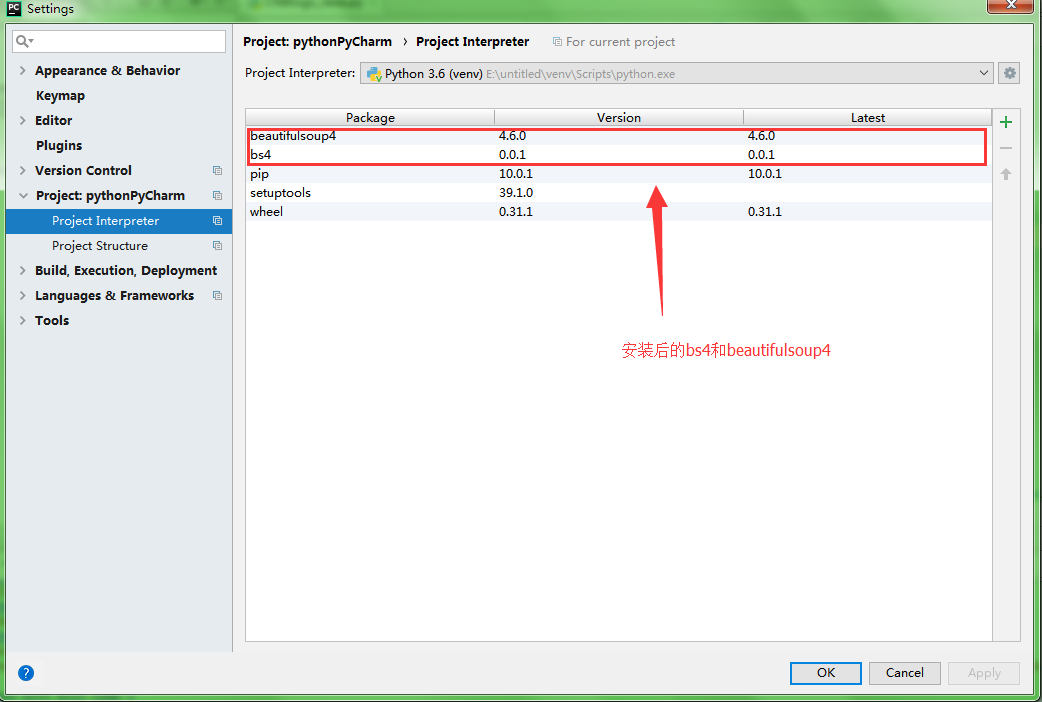
点击“+”,输入beautifulsoup ,就可以找到你要安装的插件了。
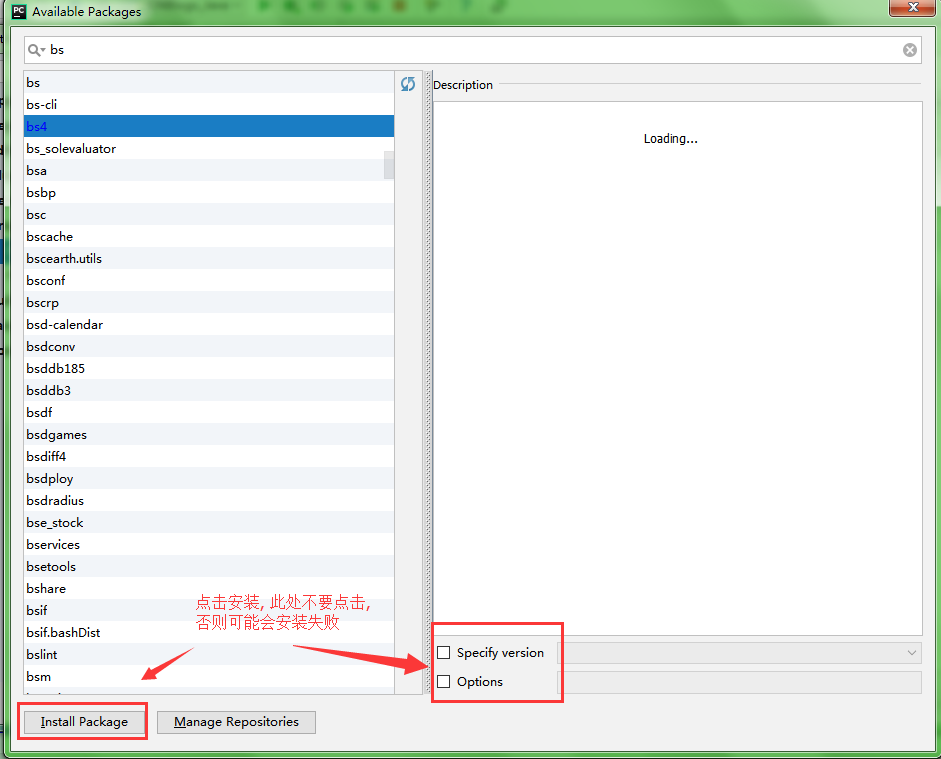
注意: Python3的选择bs4进行安装,Python2的选择beautifulSoup。
Pycharm安装package出现如下报错:
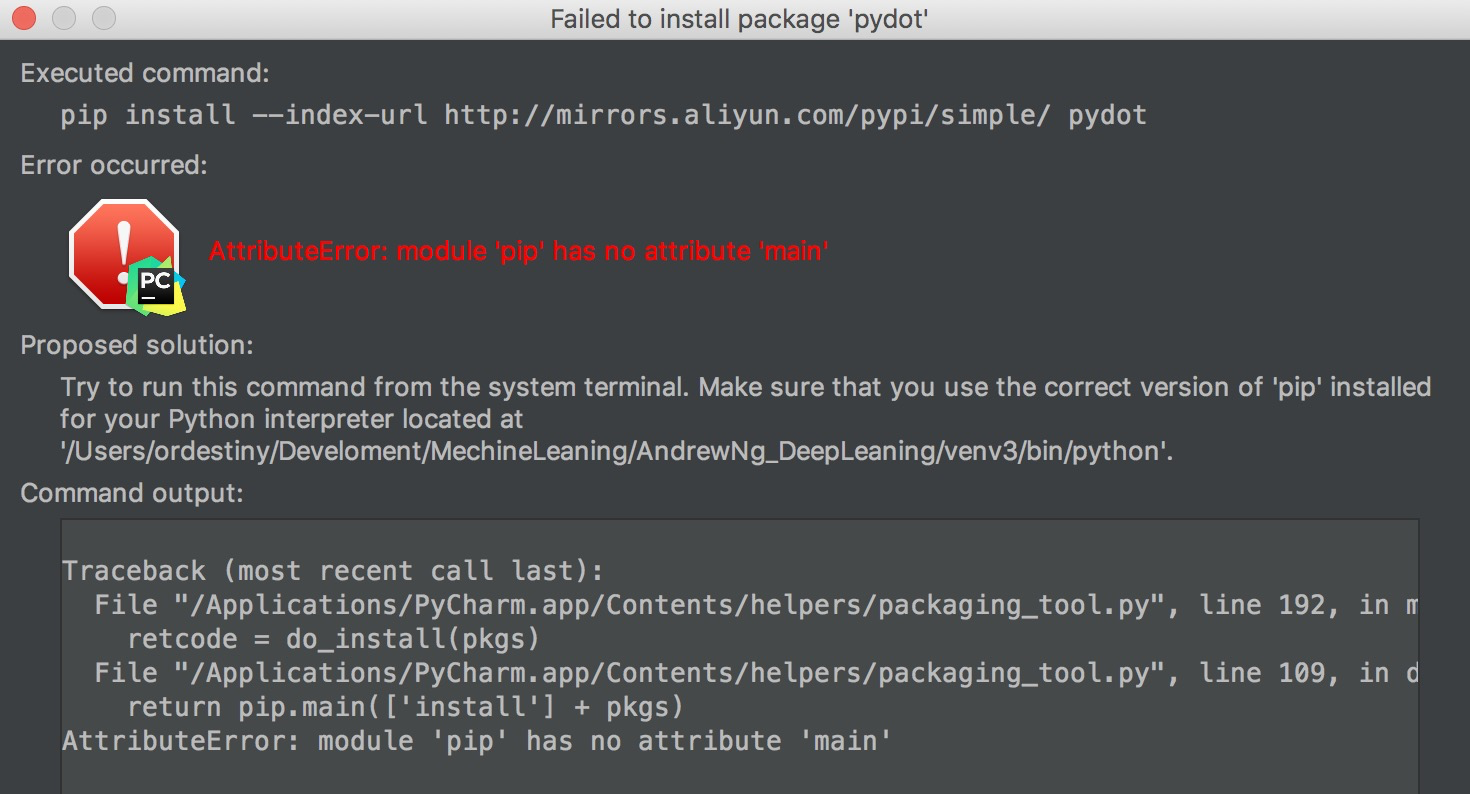
这是由于pip版本的问题,pip 10.0版本的没有main()方法, 因此更改如下代码即可:
可以考虑降个版本:python -m pip install --upgrade pip==9.0.3
解决方法:
找到C:\Program Files\JetBrains\PyCharm 2017.3.2安装目录下的 helpers/packaging_tool.py文件,找到如下代码:
def do_install(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['install'] + pkgs)
def do_uninstall(pkgs):
try:
import pip
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
修改为如下,保存即可
def do_install(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['install'] + pkgs) def do_uninstall(pkgs):
try:
# import pip
try:
from pip._internal import main
except Exception:
from pip import main
except ImportError:
error_no_pip()
return main(['uninstall', '-y'] + pkgs)
再次运行就OK了
Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法的更多相关文章
- [转]Python爬虫html解析工具beautifulSoup在pycharm中安装及失败的解决办法
原文地址:https://www.cnblogs.com/yysbolg/p/9040649.html 刚开始学习一门技术最麻烦的问题就是搞定IDE环境,直接在PyCharm里安装BeautifulS ...
- pycharm中导入包失败的解决办法
将鼠标移动到requests处,出现如下提示 按住alt+enter键,点击install package requests即可安装requests包 安装成功后
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- python爬虫网页解析之lxml模块
08.06自我总结 python爬虫网页解析之lxml模块 一.模块的安装 windows系统下的安装: 方法一:pip3 install lxml 方法二:下载对应系统版本的wheel文件:http ...
- python爬虫网页解析之parsel模块
08.06自我总结 python爬虫网页解析之parsel模块 一.parsel模块安装 官网链接https://pypi.org/project/parsel/1.0.2/ pip install ...
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
web报表工具FineReport使用中遇到的常见报错及解决办法(二) 这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己. 出现问题先搜一下文档上有没有,再看看度娘 ...
- win10 +python3.6环境下安装opencv以及pycharm导入cv2有问题的解决办法
一.安装opencv 借鉴的这篇博客已经写得很清楚了--------https://blog.csdn.net/u011321546/article/details/79499598 ,这 ...
随机推荐
- Presto + Superset 数据仓库及BI
基于Presto和superset搭建数据分析平台. Presto可以作为数据仓库,能够连接多种数据库和NoSql,同时查询性能很高: Superset提供了Presto连接,方便数据可视化和dash ...
- 微服务日志之.NET Core使用NLog通过Kafka实现日志收集
一.前言 NET Core越来越受欢迎,因为它具有在多个平台上运行的原始.NET Framework的强大功能.Kafka正迅速成为软件行业的标准消息传递技术.这篇文章简单介绍了如何使用.NET(Co ...
- 使用TheFolderSpy监控文件夹的变化-邮件通知
一.概述 当我们的文档或者代码文件发布在公网.共享文件夹中,其他用户具备访问或修改的权限时,就存在文档被覆盖或删除的分享.另外一个典型的场景,发布在Web服务器上的网页文件,在网站版本不更新的时间,服 ...
- GitHub(从安装到使用)
一.安装Git for Windows(又名msysgit) 下载地址: https://git-for-windows.github.io/ 在官方下载完后,安装到Windows Explore ...
- log4j学习(二) 不要用log4j了,用slf4j + logback吧
标题比较尴尬,log4j学习系列的最后一篇是放弃log4j - -! 一. 简介 log4j的作者提出了slf4j,简单日志门面,相当于是一套统一的java日志api,是个接口标准,编程时使用 ...
- Android 上传文件到 FTP 服务器
实现背景 近期接触到一个需求,就是将文件从Android系统上传到FTP服务器,虽然之前接触过FTP服务器,了解基本的使用流程,但是将此流程从使用习惯转化为代码实现还是有一定难度的.但是基本的流程还是 ...
- 面试时遇到的题目。正则,replace()
function Fn(str){ this.str = str; } Fn.prototype.format = function(){ var arg = arguments; var dd = ...
- js中的行为委托和无类编程
概述 <你不知道的JavaScript>中有这么一段话:不幸的是,将类和继承的设计模式思维带入Javascript的想法是你所做的最坏的事情,因为语法可能会让你迷惑不已,让你以为真的有类这 ...
- HTTP请求时间参数设置
1. JSON 2019-01-18 18:36:35 2. Postman 2019/01/18 18:36:35
- speex与webrtc回声消除小结
回声消除AEC包含: 延时估计对齐+线性自适应滤波器+NLP(双讲检测.处理)+舒适噪声CNG 一.speex aec 1.没有NLP 2.只考虑实时DSP系统,即是没有延时对齐等 3.自适应滤波 ...