大数据系列之Flume+HDFS
本文将介绍Flume(Spooling Directory Source) + HDFS,关于Flume 中几种Source详见文章 http://www.cnblogs.com/cnmenglang/p/6544081.html
1.资料准备 : apache-flume-1.7.0-bin.tar.gz
2.配置步骤:
a.上传至用户(LZ用户mfz)目录resources下
b.解压
tar -xzvf apache-flume-1.7.-bin.tar.gz
c.修改conf下 文件名

mv flume-conf.properties.template flume-conf.properties
mv flume-env.sh.template flume-env.sh
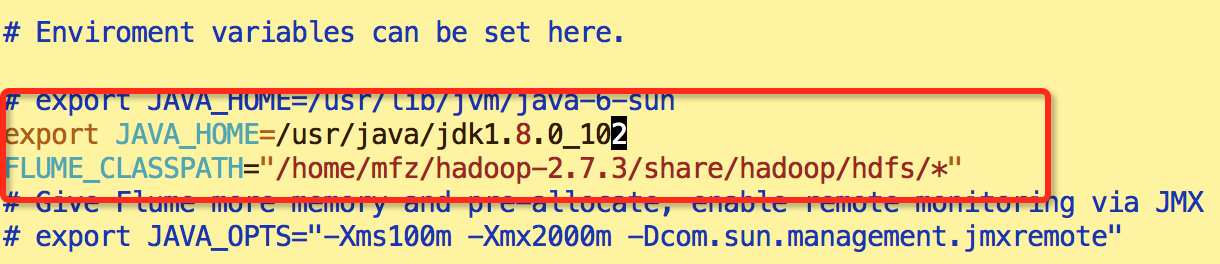
d.修改flume-env.sh 环境变量,添加如下:
export JAVA_HOME=/usr/java/jdk1.8.0_102
FLUME_CLASSPATH="/home/mfz/hadoop-2.7.3/share/hadoop/hdfs/*"
e.新增文件 hdfs.properties
LogAgent.sources = apache
LogAgent.channels = fileChannel
LogAgent.sinks = HDFS #sources config
#spooldir 对监控指定文件夹中新文件的变化,一旦有新文件出现就解析,解析写入channel后完成的文件名将追加后缀为*.COMPLATE
LogAgent.sources.apache.type = spooldir
LogAgent.sources.apache.spoolDir = /tmp/logs
LogAgent.sources.apache.channels = fileChannel
LogAgent.sources.apache.fileHeader = false #sinks config
LogAgent.sinks.HDFS.channel = fileChannel
LogAgent.sinks.HDFS.type = hdfs
LogAgent.sinks.HDFS.hdfs.path = hdfs://master:9000/data/logs/%Y-%m-%d/%H
LogAgent.sinks.HDFS.hdfs.fileType = DataStream
LogAgent.sinks.HDFS.hdfs.writeFormat=TEXT
LogAgent.sinks.HDFS.hdfs.filePrefix = flumeHdfs
LogAgent.sinks.HDFS.hdfs.batchSize = 1000
LogAgent.sinks.HDFS.hdfs.rollSize = 10240
LogAgent.sinks.HDFS.hdfs.rollCount = 0
LogAgent.sinks.HDFS.hdfs.rollInterval = 1
LogAgent.sinks.HDFS.hdfs.useLocalTimeStamp = true #channels config
LogAgent.channels.fileChannel.type = memory
LogAgent.channels.fileChannel.capacity =10000
LogAgent.channels.fileChannel.transactionCapacity = 100
3.启动:
1.在 apache-flume 目录下执行
bin/flume-ng agent --conf-file conf/hdfs.properties -c conf/ --name LogAgent -Dflume.root.logger=DEBUG,console

启动出错,Ctrl+C 退出,新建监控目录/tmp/logs
mkdir -p /tmp/logs
重新启动:
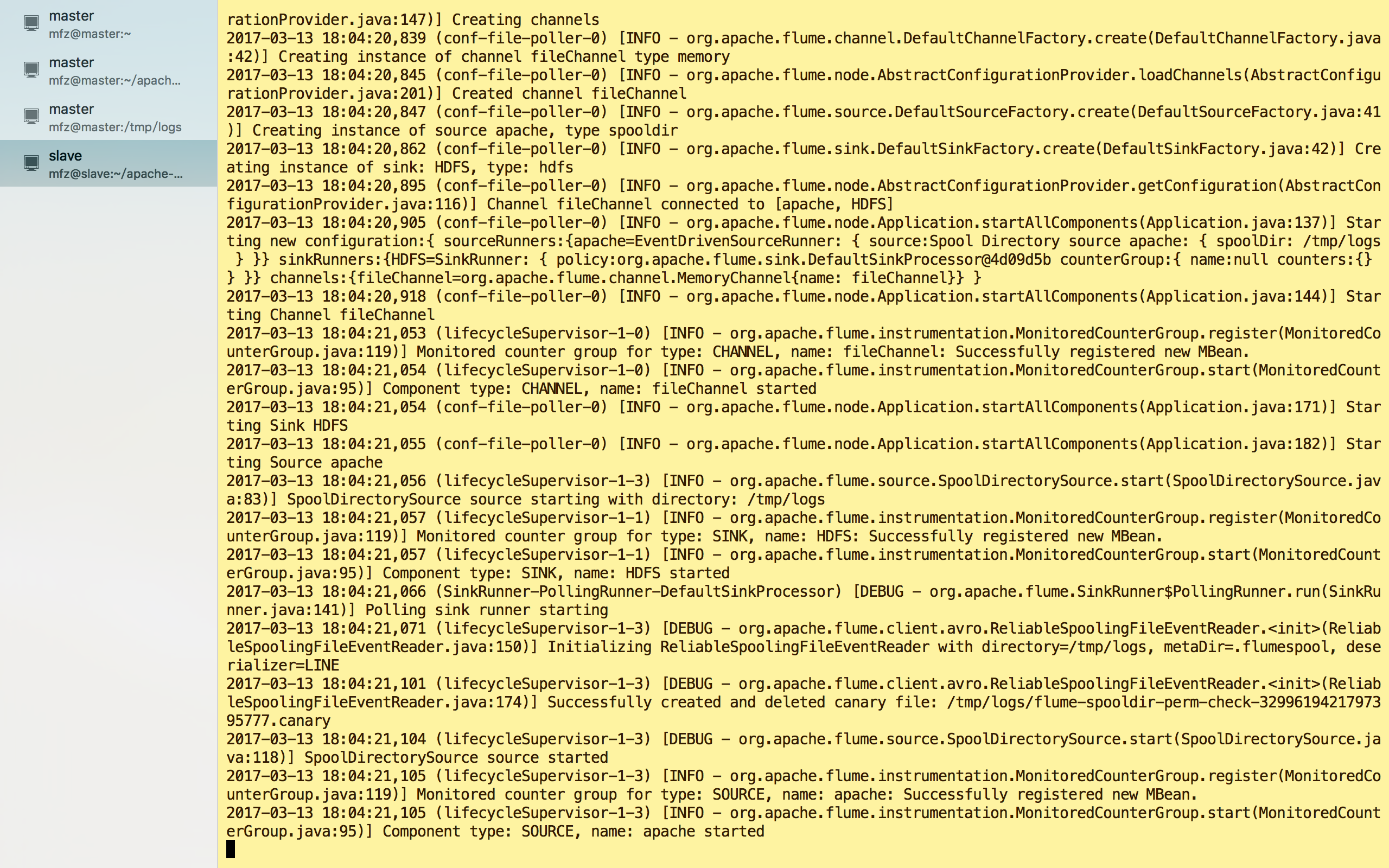
启动成功!
4.验证:
a.另新建一终端操作;
b.在监控目录/tmp/logs下新建test.log目录
vi test.log #内容
test hello world
c.保存文件后查看之前的终端输出为
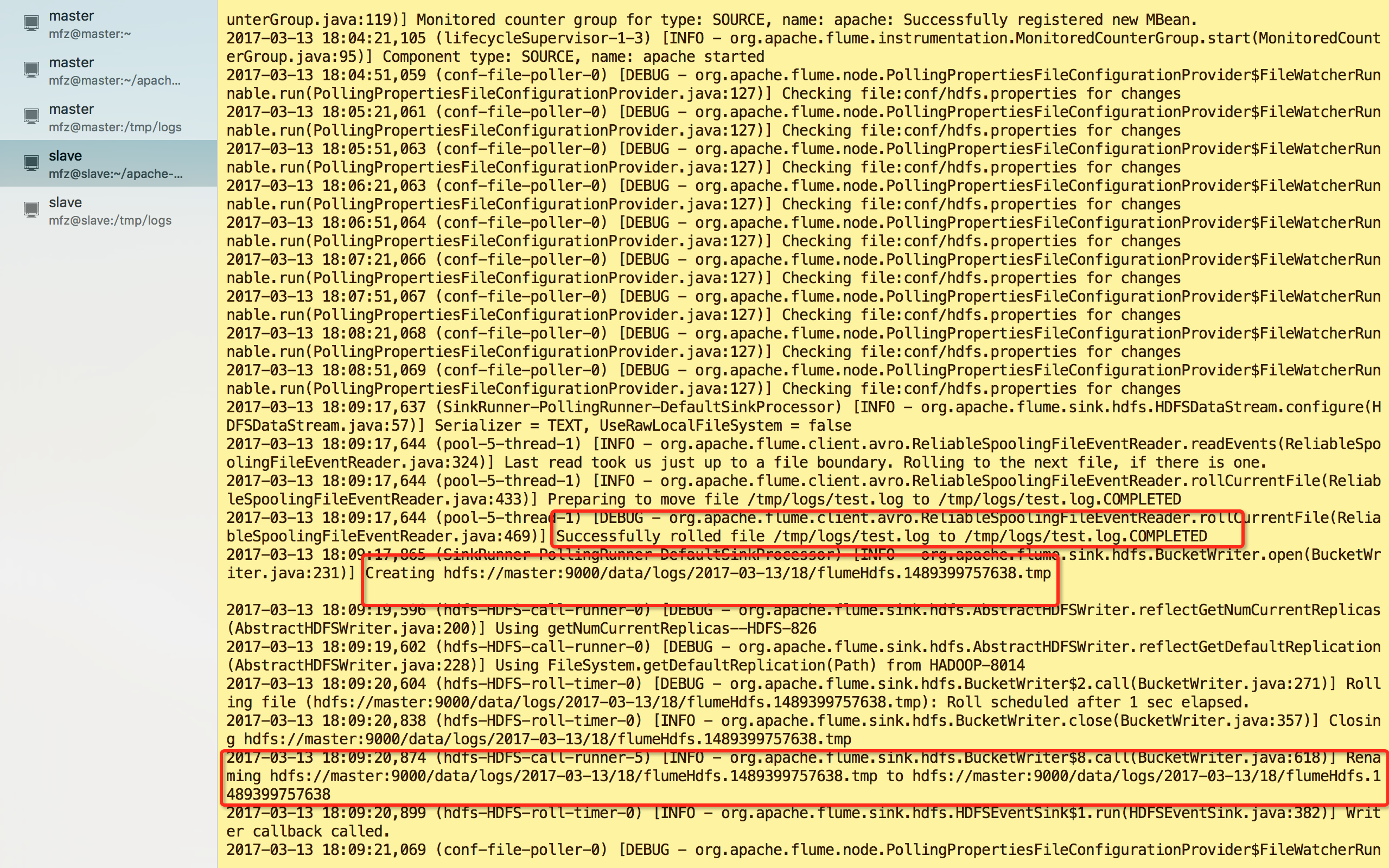
看图可得到信息:
1.test.log 已被解析传输完成且名称修改为test.log.COMPLETED;
2.HDFS目录下生成了文件及路径为:hdfs://master:9000/data/logs/2017-03-13/18/flumeHdfs.1489399757638.tmp
3.文件flumeHdfs.1489399757638.tmp 已被修改为flumeHdfs.1489399757638
那么接下里登录master主机,打开WebUI,如下操作
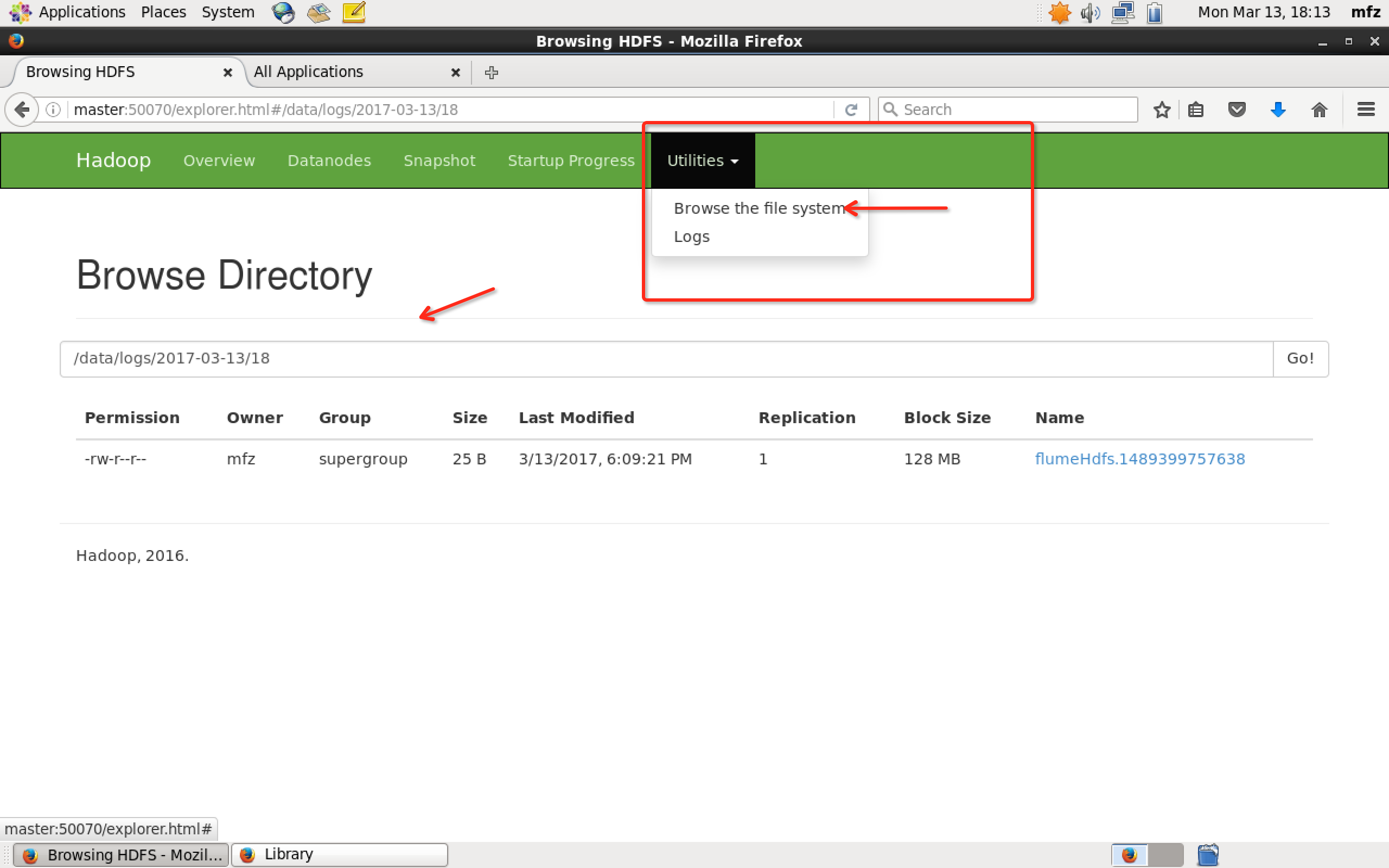
或者打开master终端,在hadoop安装包下执行命令
bin/hadoop fs -ls -R /data/logs/--/

查看文件内容,命令:
bin/hadoop fs -cat /data/logs/2017-03-13/18/flumeHdfs.1489399757638

OK,完成!
大数据系列之Flume+HDFS的更多相关文章
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
随机推荐
- NSArray和NSSet的区别
NSSet到底什么类型? 其实它和NSArray功能性质一样,用于存储对象,属于集合: NSSet , NSMutableSet类声明编程接口对象,无序的集合,在内存中存储方式是不连续的 像NSAr ...
- Raphael的拖动处理
Raphael的拖动处理: <%@ page language="java" contentType="text/html; charset=UTF-8" ...
- 在ASP.NET MVC中使用 Bootstrap table插件
Bootstrap table: http://bootstrap-table.wenzhixin.net.cn/zh-cn/getting-started/ 1. 控制器代码: using Syst ...
- Pomelo的监控模块
对服务器的监控和管理有三个主体:master,monitor,client:master负责收集所有服务器的信息,下发对服务器的操作指令.monitor负责上报服务器状态,并对master的命令作出反 ...
- Java反射机制示例
链接: http://www.cnblogs.com/rollenholt/archive/2011/09/02/2163758.html package com.stono.reftest; imp ...
- Golomb及指数哥伦布编码原理介绍及实现
2017年的第一篇博文. 本文主要有以下三部分内容: 介绍了Golomb编码,及其两个变种:Golomb-Rice和Exp-Golomb的基本原理 C++实现了一个简单的BitStream库,能够方便 ...
- LoadRunner面试题
在LoadRunner中为什么要设置思考时间和pacing 答: 录制时记录的是客户端和服务端的交互,如果要精确模拟 用户的行为,那么客户操作客户端时花费了很多时间要怎么模拟呢?录入 填写提交的内容, ...
- 使用Typescript来写javascript
使用Typescript来写javascript 前几天尝试使用haxejs来写javascript,以获得静态类型带来的益处.虽然成功了,但很快发现将它与angularjs一起使用,有一些不太顺畅的 ...
- C# 6 与 .NET Core 1.0 高级编程 - C# 6 改进
个人原创译文,转载请注明出处.有不对的地方欢迎指出与交流. 英文原文:Professional C# 6 and .NET Core 1.0 - What's New in C# 6 C# 6 改进 ...
- [html5] 学习笔记-bootstrap介绍
1.Bootstrap介绍 Bootstrap 是最受欢迎的 HTML.CSS 和 JS 框架,用于开发响应式布局.移动设备优先的 WEB 项目. 2.下面对于官网上给出的最简单的一个bootstra ...