node.js爬虫爬取拉勾网职位信息
简介
用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京、上海、广州、深圳、杭州、西安、成都7个城市的数据,分别以前端、PHP、java、c++、python、Android、ios作为关键词进行爬取,爬到的数据以json格式储存到本地,为了方便观察,我将数据整理了一下供大家参考
数据结果
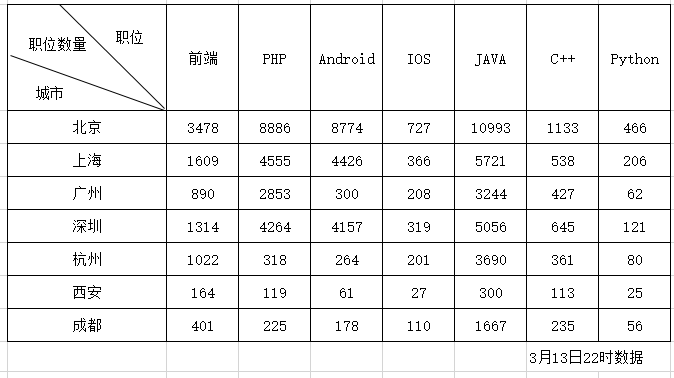
上述数据为3月13日22时爬取的数据,可大致反映各个城市对不同语言的需求量。
爬取过程展示
控制并发进行爬取

爬取到的数据文件

json数据文件

爬虫程序
实现思路
请求拉钩网的 “https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false&city=城市&kd=关键词&pn=页数”可以返回一个json格式的数据,该数据包含所要请求职位的信息,省去了使用chreio解析的麻烦,所以直接用superagent来进行请求上述地址,并将数据储存在本地即可,其中参数city是为城市,kd为所要搜索的关键词,pn为要请求的页数,当中使用到了async来控制异步流程,使得并发数不超过3,防止被封ip。
代码地址及使用
github:https://github.com/zsqosos/positionAnalysis
代码请在github上查看,使用该程序需要安装node环境,如果觉得还不错的话烦请给个star,欢迎大家修改使用该程序。
node.js爬虫爬取拉勾网职位信息的更多相关文章
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- 基于selenium爬取拉勾网职位信息
1.selenium Selenium 本是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.而这一特性为爬虫开发提供了一个选择及方向,由于其本身依赖 ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- node js 爬虫爬取静态页面,
先打一个简单的通用框子 //根据爬取网页的协议 引入对应的协议, http||https var http = require('https'); //引入cheerio 简单点讲就是node中的jq ...
- 【实战】用request爬取拉勾网职位信息
from urllib import request import urllib import ssl import json url = 'https://www.lagou.com/jobs/po ...
随机推荐
- BNU Online Judge-34777-Magical GCD
题目链接 http://www.bnuoj.com/bnuoj/problem_show.php?pid=34777 题意 如样例 输入 1530 60 20 20 20 输出 80 如 30 和 ...
- HTML <head>
HTML <head> 元素 <head> 元素包含了所有的头部标签元素.在 <head>元素中你可以插入脚本(scripts), 样式文件(CSS),及各种met ...
- spring mvc 注解入门示例
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi=" ...
- Flex移动应用程序开发的技巧和窍门(五)
范例文件 flex-mobile-development-tips-tricks-pt5.zip This is Part 5 of a multipart series of articles th ...
- Log4j与common-logging联系与区别
http://blog.csdn.net/courage89/article/details/29649801
- 关于多字节字符入库失败处理(所谓的Emji),该处理是舍弃特殊字符
具体处理方法及样例如下: /** * 屏蔽超过三个字节以上的字符 * @param strByte * @return */ public static String filterUtf8(byte[ ...
- 2017年Unity开发环境与插件配置安装(总体介绍)
最近(2017年初)有朋友问,Unity客户端开发如何在机器配置一般的情况下,配置更高效的开发环境,进一步加快开发进度. 推荐如下: Win10(或者Win8)+Unity5.5.1版本(2017年2 ...
- 论SNAPSHOT包的危害性
先介绍一下背景:我们应用是一个标准的spring+webx工程,博主在一次项目发布前为了再次测试一下自己的代码,将分支部署到日常环境中,但是项目启动的时候报错: 第一眼看到这个堆栈后有点懵逼 第一是上 ...
- UITableView、UICollectionView行高/尺寸自适应
UITableView 我们都知道UITableView从iOS 8开始实现行高的自适应相对比较简单,首先必须设置estimatedRowHeight给出预估高度,设置rowHeight为UITabl ...
- matlab和C语言的break及continue测试
break和continue语句 有两个附加语句可以控制while和for循环:break和continue语句.break语句可以中止循环的执行和跳到end后面的第一句执行,而continue只中止 ...