[读书笔记] R语言实战 (五) 高级数据管理
1. 数值函数
1) 数学函数


2) 统计函数

3. 数据标准化
scale() 函数对矩阵或者数据框的指定列进行均值为0,标准化为1的标准化
mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9))
#对所有列进行标准化
mydata <- scale(mydata)
#对指定列进行标准化
mydata <- data.frame(c1=c(1,2,3),c2=c(4,5,6),c3=c(7,8,9))
mydata <- transform(mydata,c1 = scale(c1))
4. 概率函数
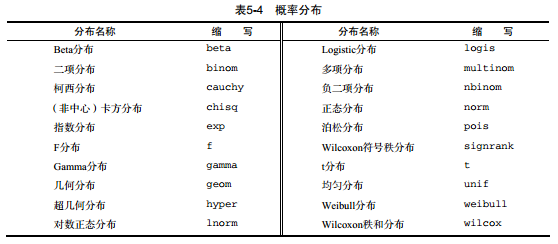
设定随机数种子:每次生成随机数的时候函数都会使用不同的种子,因此也会有不同的结果,可以通过set.seed()显示指定种子,让结果可以重现。
runif() 函数用来生成0到1区间上服从均匀分布的伪随机数
runif(5)
runif(5)
set.seed(1234)
runif(5)
set.seed(1234)
runif(5)
5. 字符处理函数


apply 函数 可以将任意一个函数应用到矩阵数组,数据框的任何维度上:
apply(x, MARGIN, FUN, ... )
mydata <- matrix(rnorm(30),nrow=6)
mydata
#计算每行的均值
apply(mydata,1,mean)
#计算每列的均值
apply(mydata,2,mean)
一个综合的例子
#限定输出小数点后两位
options(digits=2)
Student <-c("Jhon Davis","Angela Williams","Bullwinkle None",
"David Jones","Janice Markhammer","Chervl Cushing",
"Reuven Ytzrhak","Greg Knox","Joel England","Mary Rayburn")
Math <- c(502,600,412,358,495,512,410,625,573,522)
Science <- c(95,99,80,82,75,85,80,95,89,86)
English <- c(25,22,18,15,20,28,15,30,27,18)
roster <- data.frame(Student,Math,Science,English,stringsAsFactors = FALSE)
#将数学,科学,英语分数标准化,便于比较
z <- scale(roster[,2:4])
#计算行均值,每一个人的平均分
score <- apply(z,1,mean)
#将平均分
roster <- cbind(roster,score)
#计算80%,60%,40%,20%分位线
y <- quantile(score,c(.8,.6,.4,.2))
roster$grade[score>=y[1]]<-'A'
roster$grade[score<y[1] & score>=y[2]]<-'B'
roster$grade[score<y[2] & score>=y[3]]<-'C'
roster$grade[score<y[3] & score>=y[4]]<-'D'
roster$grade[score<y[4]]<-'F'
#将姓,名分开
name <- strsplit(roster$Student," ")
#抽取姓和名,'['提取对象一部分的函数
firstname <- sapply(name,"[",2)
lastname <- sapply(name,"[",1)
#将第一列剔除(下标使用-1),列拼接名和姓
roster <-cbind(firstname,lastname,roster[,-1])
roster <- roster[order(lastname,firstname),]
roster
6. 控制流
1) for 循环:for (var in seq) statement
2) while循环: while(cond) statement
3) 条件 if-else ifelse switch
7. 用户自编函数
mystats <- function(x, parametric=TRUE, print=FALSE){
if(parametric){
#计算均值和标准差
center <- mean(x); spread <- sd(x)
}else
{
#中位数和绝对中位差
center <- median(x);spread <- mad(x)
}
if (print & parametric){
cat("Mean=",center,"\n","MAD=",spread,"\n")
}
result <- list(center=center,spread=spread)
return(result)
}
set.seed(1234)
#生成服从正态分布,大小为500的样本
x <- rnorm(500)
y <- mystats(x,print=TRUE)
8. 重构与整合
1) 矩阵转置 t()
2) aggregate() 函数, aggregate(x,by,FUN), x 是待折叠的数据对象, by 是变量名组成的列表,这些变量被去掉形成新的观测,FUN,生成描述性统计量的标量函数,用来计算新观测中的值
by中的变量必须在一个列表中
options(digits=3)
attach(mtcars)
#按照cly 和 gear分类形成新的观测
aggdata <- aggregate(mtcars, by=list(Group.cyl=cyl,Group.gear=gear),FUN=mean,na.rm=TRUE)
detach(mtcars)
3) reshape包
先对数据进行融合melt():每个观测变量单独占一行,行中有唯一确定这个测量需要的标识符变量
在对数据进行重铸cast():读取已经融合的数据,使用你提供的公式和一个可选的用于整合数据的函数将其重塑
#载入reshape包
library(reshape)
#创建数据框
mydata <- data.frame(ID = c(1,1,2,2),Time = c(1,2,1,2),X1 = c(5,3,6,2),X2 = c(6,5,1,4))
#以ID和Time为标识融合数据
md <- melt(mydata,id=(c("ID","Time")))
#以ID为标识对变量求均值,可以看到ID为1的X1均值为4,X2均值为5.5
cast(md,ID~variable,mean)
#对不同ID和Time下的观测变量X进行平均
cast(md,ID~Time,mean)
[读书笔记] R语言实战 (五) 高级数据管理的更多相关文章
- [读书笔记] R语言实战 (一) R语言介绍
典型数据分析的步骤: R语言:为统计计算和绘图而生的语言和环境 数据分析:统计学,机器学习 R的使用 1. 区分大小写的解释型语言 2. R语句赋值:<- 3. R注释: # 4. 创建向量 c ...
- [读书笔记] R语言实战 (四) 基本数据管理
1. 创建新的变量 mydata<-data.frame(x1=c(2,2,6,4),x2=c(3,4,2,8)) #方法一 mydata$sumx<-mydata$x1+mydata$x ...
- [读书笔记] R语言实战 (二) 创建数据集
R中的数据结构:标量,向量,数组,数据框,列表 1. 向量:储存数值型,字符型,或者逻辑型数据的一维数组,用c()创建 ** R中没有标量,标量以单元素向量的形式出现 2. 矩阵:二维数组,和向量一 ...
- [读书笔记] R语言实战 (六) 基本图形方法
1. 条形图 barplot() #载入vcd包 library(vcd) #table函数提取各个维度计数 counts <- table(Arthritis$Improved) count ...
- [读书笔记] R语言实战 (十四) 主成分和因子分析
主成分分析和探索性因子分析是用来探索和简化多变量复杂关系的常用方法,能解决信息过度复杂的多变量数据问题. 主成分分析PCA:一种数据降维技巧,将大量相关变量转化为一组很少的不相关变量,这些无关变量称为 ...
- [读书笔记] R语言实战 (三) 图形初阶
创建图形,保存图形,修改特征:标题,坐标轴,标签,颜色,线条,符号,文本标注. 1. 一个简单的例子 #输出到图形到pdf文件 pdf("mygrapg.pdf") attach( ...
- [读书笔记] R语言实战 (十三) 广义线性模型
广义线性模型扩展了线性模型的框架,它包含了非正态的因变量分析 广义线性模型拟合形式: $$g(\mu_\lambda) = \beta_0 + \sum_{j=1}^m\beta_jX_j$$ $g( ...
- 《R语言实战》读书笔记--为什么要学
本人最近在某咨询公司实习,涉及到了一些数据分析的工作,用的是R语言来处理数据.但是在应用的过程中,发现用R很不熟练,所以再打算学一遍R.曾经花一个月的时间看过一遍<R语言编程艺术>,还用R ...
- R语言实战(第二版)-part 1笔记
说明: 1.本笔记对<R语言实战>一书有选择性的进行记录,仅用于个人的查漏补缺 2.将完全掌握的以及无实战需求的知识点略去 3.代码直接在Rsudio中运行学习 R语言实战(第二版) pa ...
随机推荐
- 【JavaScript框架封装】实现一个类似于JQuery的CSS样式框架的封装
// CSS 样式框架 (function (xframe) { // 需要参与链式访问的(必须使用prototype的方式来给对象扩充方法)[只要是需要使用到this获取到的元素集合这个变量的时候, ...
- BZOJ 4712 洪水 (线段树+树剖动态维护DP)
题目大意:略 题目传送门 数据结构好题,但据说直接上动态DP会容易处理不少,然而蒟蒻不会.一氧化碳大爷说还有一个$log$的做法,然而我只会$log^{2}$的.. 考虑静态时如何处理,设$f[x]$ ...
- C++ auto类型说明符
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50864612 编程时常常需要把表达式的 ...
- [Angular] ngx-formly (AKA angular-formly for Angular latest version)
In our dynamic forms lessons we obviously didn’t account for all the various edge cases you might co ...
- 《生活在Linux中》之:在Bash的Emacs模式中使用Vim
export EDITOR=vim ctrl-x ctrl-e
- SSD纠错码向LDPC码演变
作者:Stephen Bates SSD控制器芯片中採用的纠错编码(ECCs)的类型正在发生一场演变.相信很多这篇博文的读者对此都有所了解.传统上採用的纠错码是基于群变换的博斯-查德胡里-霍昆格母(B ...
- Android顶部粘至视图具体解释
不知从某某时间開始,这样的效果開始在UI设计中流行起来了.让我们先来看看效果: 大家在支付宝.美团等非常多App中都有使用.要实现这个效果,我们能够来分析下思路: 我们肯定要用2个一样的布局来显示我们 ...
- 2015.05.15,外语,学习笔记-《Word Power Made Easy》 02 “如何谈论医生”
包括Sessions 4-6: Prefix Person,nous,etc. Practice,etc. Adjective internus内部 internist [ɪn'tɝnɪst] n.内 ...
- Linux下配置httpd服务
第一步拷贝 cp /usr/local/apache2/bin/apachectl /etc/rc.d/init.d/httpd 第二步,修改 vim /etc/rc.d/init.d/httpd # ...
- tomcat指定JDK版本
在windows环境下以批处理文件方式启动tomcat,只要运行<CATALINA_HOME>/bin/startup.bat这个文件,就可以启动Tomcat. 在启动时,startup. ...