剖析nsq消息队列(二) 去中心化代码源码解析
剖析nsq消息队列-目录
在上一篇帖子剖析nsq消息队列(一) 简介及去中心化实现原理中,我介绍了nsq的两种使用方式,一种是直接连接,还有一种是通过nslookup来实现去中心化的方式使用,并大概说了一下实现原理,没有什么难理解的东西,这篇帖子我把nsq实现去中心化的源码和其中的业物逻辑展示给大家看一下。
nsqd和nsqlookupd的通信实现
上一篇中在启动nsqd时我用了以下命令,我指定了一个参数 --lookupd-tcp-address
./nsqd -tcp-address ":8000" -http-address ":8001" --lookupd-tcp-address=127.0.0.1:8200 --lookupd-tcp-address=127.0.0.1:7200 -data-path=./a
--lookupd-tcp-address 用于指定nsqlookupd的tcp监听地址。
nsqd 和 nsqlookupd的通信交流简单来说就是下图这样
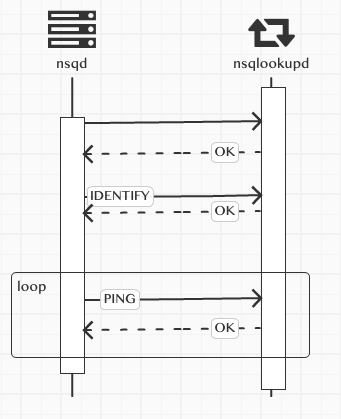
nsqd启动后连接nsqlookupd,连接成功后,要发送一个魔法标识nsq.MagicV1,这个标识有啥魔法么,当然不是,他只是用于标明,客户端和服务端双方使用的信息通信版本,不能的版本有不同的处理方式,为了后期做新的消息处理版本方便吧。
nsqlookupd 的代码块
func (p *tcpServer) Handle(clientConn net.Conn) {
// ...
buf := make([]byte, 4)
_, err := io.ReadFull(clientConn, buf)
// ...
protocolMagic := string(buf)
// ...
var prot protocol.Protocol
switch protocolMagic {
case " V1":
prot = &LookupProtocolV1{ctx: p.ctx}
default:
// ...
return
}
err = prot.IOLoop(clientConn)
//...
}
这个时候的nsqd已经和nsqlookupd建立好了连接,但是这时,仅仅说明他俩连接成功。
nsqlookupd也并没有把这个连接加到可用的nsqd列表里。
建立连接完成后,nsqd会发送IDENTIFY命令,这个命令里包含了nsq的基本信息
nsqd的代码
ci := make(map[string]interface{})
ci["version"] = version.Binary
ci["tcp_port"] = n.RealTCPAddr().Port
ci["http_port"] = n.RealHTTPAddr().Port
ci["hostname"] = hostname
ci["broadcast_address"] = n.getOpts().BroadcastAddress
cmd, err := nsq.Identify(ci)
if err != nil {
lp.Close()
return
}
resp, err := lp.Command(cmd)
包含了nsqd 提供的tcp和http端口,主机名,版本等等,发送给nsqlookupd,nsqlookupd收到IDENTIFY命令后,解析信息然后加到nsqd的可用列表里
nsqlookupd 的代码块
func (p *LookupProtocolV1) IDENTIFY(client *ClientV1, reader *bufio.Reader, params []string) ([]byte, error) {
var err error
if client.peerInfo != nil {
return nil, protocol.NewFatalClientErr(err, "E_INVALID", "cannot IDENTIFY again")
}
var bodyLen int32
err = binary.Read(reader, binary.BigEndian, &bodyLen)
// ...
body := make([]byte, bodyLen)
_, err = io.ReadFull(reader, body)
// ...
peerInfo := PeerInfo{id: client.RemoteAddr().String()}
err = json.Unmarshal(body, &peerInfo)
// ...
client.peerInfo = &peerInfo
// 把nsqd的连接加入到可用列表里
if p.ctx.nsqlookupd.DB.AddProducer(Registration{"client", "", ""}, &Producer{peerInfo: client.peerInfo}) {
p.ctx.nsqlookupd.logf(LOG_INFO, "DB: client(%s) REGISTER category:%s key:%s subkey:%s", client, "client", "", "")
}
// ...
return response, nil
}
然后每过15秒,会发送一个PING心跳命令给nsqlookupd,这样保持存活状态,nsqlookupd每次收到发过来的PING命令后,也会记下这个nsqd的最后更新时间,这样做为一个筛选条件,如果长时间没有更新,就认为这个节点有问题,不会把这个节点的信息加入到可用列表。
到此为止,一个nsqd就把自己的信息注册到nsqlookupd的可用列表了,我们可以启动多个nsqd和多个nsqlookupd,为nsqd
指定多个nsqlookupd,就如同我上一篇帖子写的那样
--lookupd-tcp-address=127.0.0.1:8200 --lookupd-tcp-address=127.0.0.1:7200
nsqd和所有的nsqlookupd建立连接,注册服务信息,并保持心跳,保证可用列表的更新.
nsqlookupd 挂掉的处理方式
上面我们说了nsqd如果出现问题,nsqlookupd的nsqd可用列表里就会处理掉这个连接信息。如nsqlookupd挂了怎么办呢
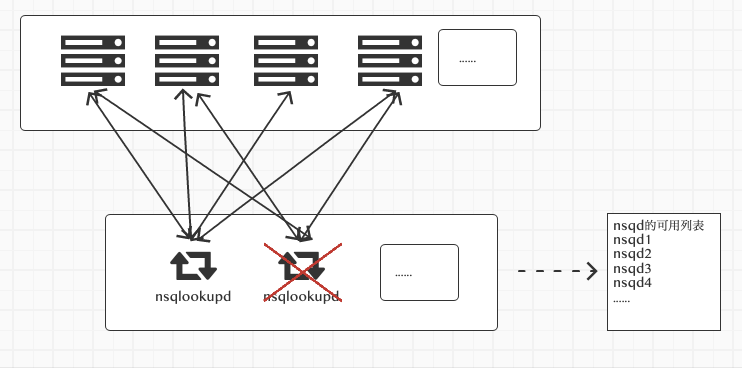
目前的处理方式是这样的,
无论是心跳,还是其他命令,nsqd会给所有的nsqlookup发送信息,当nsqd发现nsqlookupd出现问题时,在每次发送命令时,会不断的进行重新连接:
func (lp *lookupPeer) Command(cmd *nsq.Command) ([]byte, error) {
initialState := lp.state
if lp.state != stateConnected {
err := lp.Connect()
if err != nil {
return nil, err
}
lp.state = stateConnected
_, err = lp.Write(nsq.MagicV1)
if err != nil {
lp.Close()
return nil, err
}
if initialState == stateDisconnected {
lp.connectCallback(lp)
}
if lp.state != stateConnected {
return nil, fmt.Errorf("lookupPeer connectCallback() failed")
}
}
// ...
}
如果连接成功,会再次调用connectCallback方法,进行IDENTIFY命令的调用等。
客户端和nsqlookupd、nsqd的通信实现
上一篇帖子里介绍了,客户端如何连接nsqlookupd来进行通信
adds := []string{"127.0.0.1:7201", "127.0.0.1:8201"}
config := nsq.NewConfig()
config.MaxInFlight = 1000
config.MaxBackoffDuration = 5 * time.Second
config.DialTimeout = 10 * time.Second
topicName := "testTopic1"
c, _ := nsq.NewConsumer(topicName, "ch1", config)
testHandler := &MyTestHandler{consumer: c}
c.AddHandler(testHandler)
if err := c.ConnectToNSQLookupds(adds); err != nil {
panic(err)
}
需要注意adds里地址的端口,是nsqlookupd的http端口
这里我还使用上一篇帖子中的图,给大家详细分析

调用方法c.ConnectToNSQLookupds(adds),他的实现是访问nsqlookupd的http端口http://127.0.0.1:7201/lookup?topic=testTopic1得到提供consumer订阅的topic所有的producers节点信息, url返回的数据信息如下。
{
"channels": [
"nsq_to_file",
"ch1"
],
"producers": [
{
"remote_address": "127.0.0.1:58606",
"hostname": "li-peng-mc-macbook.local",
"broadcast_address": "li-peng-mc-macbook.local",
"tcp_port": 8000,
"http_port": 8001,
"version": "1.1.1-alpha"
},
{
"remote_address": "127.0.0.1:58627",
"hostname": "li-peng-mc-macbook.local",
"broadcast_address": "li-peng-mc-macbook.local",
"tcp_port": 7000,
"http_port": 7001,
"version": "1.1.1-alpha"
}
]
}

方法queryLookupd就是进行的上图的操作
- 得到提供订阅的
topic的nsqd列表 - 进行连接
func (r *Consumer) queryLookupd() {
retries := 0
retry:
endpoint := r.nextLookupdEndpoint()
// ...
err := apiRequestNegotiateV1("GET", endpoint, nil, &data)
if err != nil {
// ...
}
var nsqdAddrs []string
for _, producer := range data.Producers {
broadcastAddress := producer.BroadcastAddress
port := producer.TCPPort
joined := net.JoinHostPort(broadcastAddress, strconv.Itoa(port))
nsqdAddrs = append(nsqdAddrs, joined)
}
// 进行连接
for _, addr := range nsqdAddrs {
err = r.ConnectToNSQD(addr)
if err != nil && err != ErrAlreadyConnected {
r.log(LogLevelError, "(%s) error connecting to nsqd - %s", addr, err)
continue
}
}
}
如何刷新nsqd的可用列表
有新的nsqd加入,是如何处理的呢?
在调用ConnectToNSQLookupd时会启动一个协程go r.lookupdLoop() 调用方法lookupdLoop的定时循环访问 queryLookupd 更新 nsqd的可用列表
// poll all known lookup servers every LookupdPollInterval
func (r *Consumer) lookupdLoop() {
// ...
var ticker *time.Ticker
select {
case <-time.After(jitter):
case <-r.exitChan:
goto exit
}
// 设置Interval 来循环访问 queryLookupd
ticker = time.NewTicker(r.config.LookupdPollInterval)
for {
select {
case <-ticker.C:
r.queryLookupd()
case <-r.lookupdRecheckChan:
r.queryLookupd()
case <-r.exitChan:
goto exit
}
}
exit:
// ...
}
处理 nsqd 的单点故障
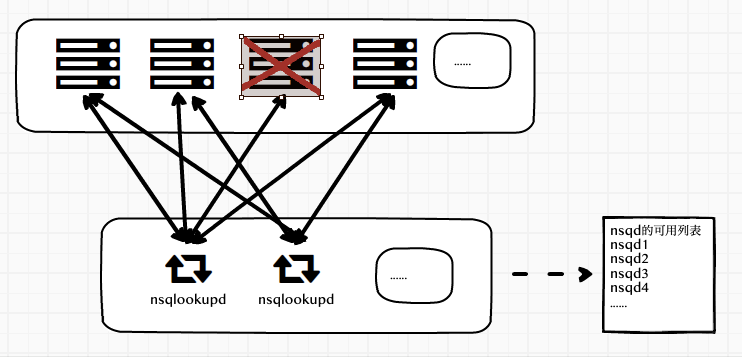
当有nsqd出现故障时怎么办?当前的处理方式是
nsqdlookupd会把这个故障节点从可用列表中去除,客户端从接口得到的可用列表永远都是可用的。- 客户端会把这个故障节点从可用节点上移除,然后要去判断是否使用了
nsqlookup进行了连接,如果是则case r.lookupdRecheckChan <- 1去刷新可用列表queryLookupd,如果不是,然后启动一个协程去定时做重试连接,如果故障恢复,连接成功,会重新加入到可用列表.
客户端实现的代码
func (r *Consumer) onConnClose(c *Conn) {
// ...
// remove this connections RDY count from the consumer's total
delete(r.connections, c.String())
left := len(r.connections)
// ...
r.mtx.RLock()
numLookupd := len(r.lookupdHTTPAddrs)
reconnect := indexOf(c.String(), r.nsqdTCPAddrs) >= 0
// 如果使用的是nslookup则去刷新可用列表
if numLookupd > 0 {
// trigger a poll of the lookupd
select {
case r.lookupdRecheckChan <- 1:
default:
}
} else if reconnect {
// ...
}(c.String())
}
}
剖析nsq消息队列(二) 去中心化代码源码解析的更多相关文章
- 剖析nsq消息队列目录
剖析nsq消息队列(一) 简介及去中心化实现原理 剖析nsq消息队列(二) 去中心化源码解析 剖析nsq消息队列(三) 消息传输的可靠性和持久化[一] 剖析nsq消息队列(三) 消息传输的可靠性和持久 ...
- 剖析nsq消息队列(一) 简介及去中心化实现原理
分布式消息队列nsq,简单易用,去中心化的设计使nsq更健壮,nsq充分利用了go语言的goroutine和channel来实现的消息处理,代码量也不大,读不了多久就没了.后期的文章我会把nsq的源码 ...
- 剖析nsq消息队列(四) 消息的负载处理
剖析nsq消息队列-目录 实际应用中,一部分服务集群可能会同时订阅同一个topic,并且处于同一个channel下.当nsqd有消息需要发送给订阅客户端去处理时,发给哪个客户端是需要考虑的,也就是我要 ...
- 消息队列高手课,带你从源码角度全面解析MQ的设计与实现
消息队列中间件的使用并不复杂,但如果你对消息队列不熟悉,很难构建出健壮.稳定并且高性能的企业级系统,你会面临很多实际问题: 如何选择最适合系统的消息队列产品? 如何保证消息不重复.不丢失? 如果你掌握 ...
- [源码解析] 消息队列 Kombu 之 基本架构
[源码解析] 消息队列 Kombu 之 基本架构 目录 [源码解析] 消息队列 Kombu 之 基本架构 0x00 摘要 0x01 AMQP 1.1 基本概念 1.2 工作过程 0x02 Poll系列 ...
- serf 中去中心化系统的原理和实现
原文:https://www.infoq.cn/article/principle-and-impleme-of-de-centering-system-in-serf serf 是出自 Hashic ...
- Filecoin:一种去中心化的存储网络(二)
开始初步了解学习Filecoin,如下是看白皮书的内容整理. 参考: 白皮书中文版 http://chainx.org/paper/index/index/id/13.html 白皮书英文版 http ...
- Go:Nsq消息队列
Nsq服务端简介 在使用Nsq服务之前,还是有必要了解一下Nsq的几个核心组件整个Nsq服务包含三个主要部分 nsqlookupd 先看看官方的原话是怎么说:nsqlookupd是守护进程负责管理拓扑 ...
- 小众Tox——大众的“去中心化”聊天软件
★Tox是什么 一个反窥探的开源项目:一种基于DHT(BitTorrent)技术的即时通讯协议:一个为安全而生的加密通讯系统 .美国棱镜计划曝光后,一个名为 irungentoo 的牛人于17天后的2 ...
随机推荐
- 【win】【qt5安装】【qt5.5.1安装及第一个示例make错误】
[前言] 昨天按照需求将qt程序从linux系统移植到win上使用(其实有点缪论了,本人linux用的中标麒麟系统对于发布发布系统版本麒麟(注:以下用麒麟代替中标麒麟,什么银河麒麟,优麒麟的,我现在只 ...
- kvm 内部错误:无法找到适合 x86_64 的模拟器
0x00 问题 安装完 KVM 之后,启动管理工具报错:内部错误:无法找到适合 x86_64 的模拟器 于是查看 libvirtd 服务状态,查看到以下内容: 6月 14 10:18:53 local ...
- 【Node/JavaScript】论一个低配版Web实时通信库是如何实现的( WebSocket篇)
引论 simple-socket是我写的一个"低配版"的Web实时通信工具(相对于Socket.io),在参考了相关源码和资料的基础上,实现了前后端实时互通的基本功能 选用了Web ...
- HBase 系列(二)—— HBase 系统架构及数据结构
一.基本概念 一个典型的 Hbase Table 表如下: 1.1 Row Key (行键) Row Key 是用来检索记录的主键.想要访问 HBase Table 中的数据,只有以下三种方式: 通过 ...
- 纯 CSS 实现绘制各种三角形(各种角度)
一.前言 三角形实现原理:宽度width为0:height为0:(1)有一条横竖边(上下左右)的设置为border-方向:长度 solid red,这个画的就是底部的直线.其他边使用border-方向 ...
- Linux Web集群架构详细(亲测可用!!!)
注意:WEB服务器和数据库需要分离,同时WEB服务器也需要编译安装MySQL. 做集群架构的重要思想就是找到主干,从主干区域向外延展. WEB服务器: apache nginx 本地做三个产品 de ...
- nanopi NEO2 学习笔记 3:python 安装 RPi.GPIO
如果我要用python控制NEO2的各种引脚,i2c 或 spi ,RPi.GPIO模块是个非常好的选择 这个第三方模块是来自树莓派的,好像友善之臂的工程师稍作修改移植到了NEO2上,就放在 /roo ...
- python 31 升级版解决粘包现象
目录 1. recv 工作原理 2.升级版解决粘包问题 3. 基于UDP协议的socket通信 1. recv 工作原理 1.能够接收来自socket缓冲区的字节数据: 2.当缓冲区没有数据可以读取时 ...
- 🕸捕获与改写HTTPS请求
前言 本文站在 macOS 用户的角度下,分享一下对 HTTPS 进行请求拦截.对响应进行修改的经验. 要注意的是,本文介绍的工具虽然一定程度上对 Windows 用户也适用 ,但并非所有工具都是免费 ...
- 第三篇 视觉里程计(VO)的初始化过程以及openvslam中的相关实现详解
视觉里程计(Visual Odometry, VO),通过使用相机提供的连续帧图像信息(以及局部地图,先不考虑)来估计相邻帧的相机运动,将这些相对运行转换为以第一帧为参考的位姿信息,就得到了相机载体( ...