Jmeter 接口自动化-脚本数据分离实例
一、 背景:
为了让大家更加的了解Jmeter,并且使用起来游刃有余。
这篇我们主要讲一下,如何优雅的使用Jmeter一步步的实现接口自动化,完成脚本与数据分离,把可能对Jmeter脚本的维护转移到csv文本中,降低接口变更时对脚本的维护,最终目标是实现写好接口自动化脚本后,接口变更的维护都只要操作csv文件。
Jmeter脚本,数据和报告地址:
https://github.com/grizz/jmeter-master
testerhome地址:https://testerhome.com/topics/13029
二、实例
先介绍一个Jmeter的函数-》csvRead函数,后续介绍使用的会比较多,熟悉的伙伴可以直接跳过。
1、csvRead函数使用:
csvRead函数是从外部读取参数,可以从一个文件中读取多个参数。
使用步骤:
1、先新建一个文件,例如test.csv(或test.txt),里面的数据存放为
grizz,qq1111
jiezai,qq1111
文件为用户名和密码,用逗号隔开,每一列表示一种参数,每一行则表示一组参数。
2、选项-》函数助手对话框-》函数助手,打开Jmeter的函数助手,选择csvRead函数:
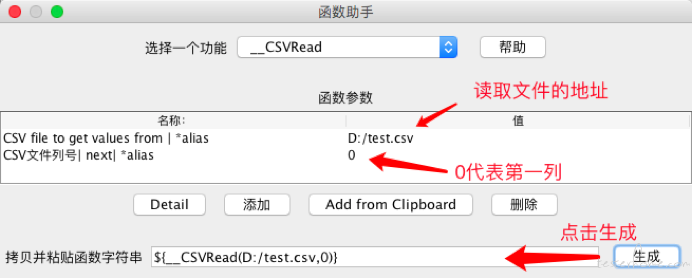
其中:
CSV file to get values from | *alias:要读取的文件路径,为绝对路径
CSV文件列号| next| *alias:从第几列开始读取,注意第一列是0
即${__CSVRead(D:/test.csv,0)} 取到的值为grizz
即${__CSVRead(D:/test.csv,1)} 取到的值为qq1111
3.Jmeter执行的时候,如果有多个线程,顺序读取每行的数据,如果线程组多于文件中的行数,则循环读取。如线程数为2,则第2个线程读取的是第二行的数据,线程数为3,线程数3大于文件中的行数2,则第3个线程读取的是第一行的数据。
PS:这一函数并不适合于读取很大的文件,因为整个文件都会被存储到内存之中。对于较大的文件,请使用配置元件CSV Data Set或者StringFromFile 。但是我们不是压测,只是接口自动化,一般没有太大的数据文件,啊哈哈哈哈。
默认情况下,函数会在遇到的每一个逗号处断行,需要换一个分隔符(通过设置属性csvread.delimiter来实现)
修改jmeter.properties文件:
#csvread.delimiter=,
修改为
csvread.delimiter=?
即把分隔符修改为?问号,注意前面的#号代表注释,要去掉。重启Jmeter生效。
2、使用的接口:
这里我们以两个接口举例,其中Content-Type=application/json:
1·获取token的接口/getToken
入参:
{
"flag":"test",
"appId":"001"
}
返回值:
{"returnFlag":"1000","returnMsg":"获取token成功","token":"19940622"}
2·使用token的接口/useToken,主要是测试useToken接口,useToken接口的token需要从getToken接口的返回值中取,其实就是参数关联。
入参:
{
"flag":"${token}",
"appId":"001"
}
返回值,以3个场景为例:
{"returnFlag":"1000","returnMsg":"使用token成功"}
{"returnFlag":"1001","returnMsg":"token为空"}
{"returnFlag":"1002","returnMsg":"token错误"}
对于接口的断言,我们默认"returnFlag":"1000"即接口业务正常返回,1001,1002代表接口针对业务的不同异常给予的返回,当然也在我们的接口测试范围内。
我们分v1,v2,v3,v4,4个版本循序渐进的讲:
v1版本:
刚开始入门时,我们的脚本可能会是这样的
先请求getToken接口,并获取token,用正则表达式提取如下
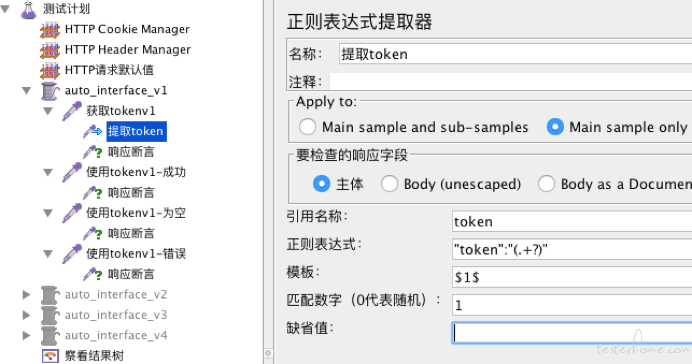
再请求useToken接口,flag的值输入${token},使用提取到的token值。
入参:{"flag":"${token}","appId":"001"}
返回值:{"returnFlag":"1000","returnMsg":"使用token成功"}
断言:"returnFlag":"1000",断言成功
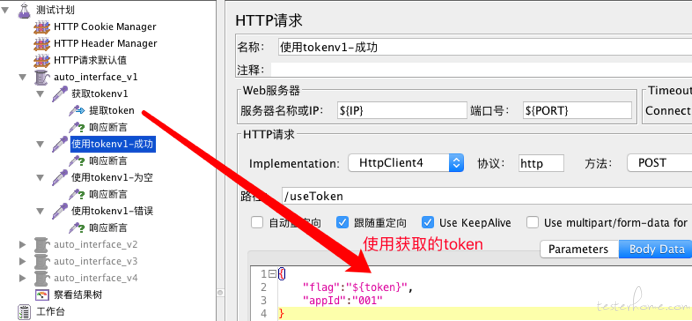
再测试后续两种场景,入参如下:
sampler-使用tokenv1-为空:
入参:{"flag":"","appId":"002"}
返回值:{"returnFlag":"1001","returnMsg":"token为空"}
断言:"returnFlag":"1000",断言失败
sampler-使用tokenv1-错误:
入参:{"flag":"errorToken","appId":"003"}
返回值:{"returnFlag":"1002","returnMsg":"token错误"}
断言:"returnFlag":"1000",断言失败
查看结果树
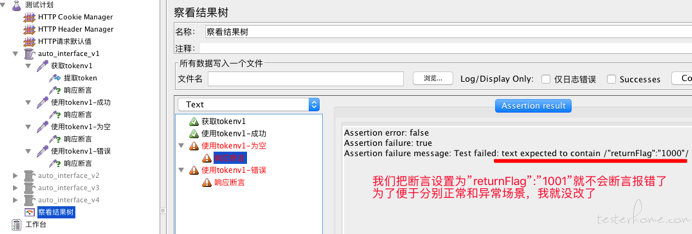
这一顿操作下来,没啥问题,因为useToken接口的3种场景我们都覆盖了,只要把异常的场景的断言对应改一下,我们的接口脚本就写好了,可以交付。但是如果我们要实现接口自动化,那么v1版本中sampler的重复率比较高,我们考虑能不能把useToken的3种场景放到一个sampler中。
于是有了v2版本
v2版本:
由于聪明的我们有一定前瞻性,我们知道,想降低脚本中sampler的重复率,需要借助数据文件,我们可以把接口useToken的请求body直接从文件中读
入参1:{"flag":"${token}","appId":"001"}
入参2:{"flag":"","appId":"002"}
入参3:{"flag":"errorToken","appId":"003"}
入参2,3我们可以从文件中读取没问题,但是入参1这样从文件中读取,”${token}”读取出来的值就是字符串”${token}”,而不是我们想要的”19940622”,怎么办呢?
于是我们思考着,可以把接口useToken的请求分两种情况,需要正确的token和不需要正确的token,如果需要正确的token,我们就在Jmeter中传给他,其它参数还是可以在文本中读取;如果不需要正确的token,则请求全部从文件中读取。什么意思呢,继续往下看。
我们设置存放csv文件的目录 DATA=/jmeter/testcase,因为我们可能会多次使用到这个目录,所以可以用${ DATA }代表我们的文件目录。
useToken_v2.csv文件:
用例1-token正确?1?"appId":"001"}
用例2-token为空?0?{"flag":"","appId":"002"}
用例3-token错误?0?{"flag":"errorToken","appId":"003"}
举例:${__CSVRead(${DATA}/useToken_v2.csv,1)}依次取到的是1,0,0${__CSVRead(${DATA}/useToken_v2.csv,2)}第二次取到的是{"flag":"","appId":"002"}
如果我们useToken_v2.csv文件有3行,则设置auto_interface_v2线程数为3。
因为对于csvRead函数,每一个线程都有独立的内部指针指向文件数组中的当前行。当某个线程第一次引用文件时,函数会为线程在数组中分配下一个空闲行。如此一来,任何一个线程访问的文件行,都与其他线程不同(除非线程数大于数组包含的行数)。
当我们需要正确Token时,我们利用if控制器,如果文本的第二列(我这里是以问号分隔的,因为默认是逗号,但是我们接口json数据本身就有逗号,只能换一个)为1,则flag从Jmeter中自己读取;如果文本的第二列为0则代表不需要正确token,那接口入参我们就全部从文件中读取。
If:${__CSVRead(${DATA}/useToken_v2.csv,1)}==1
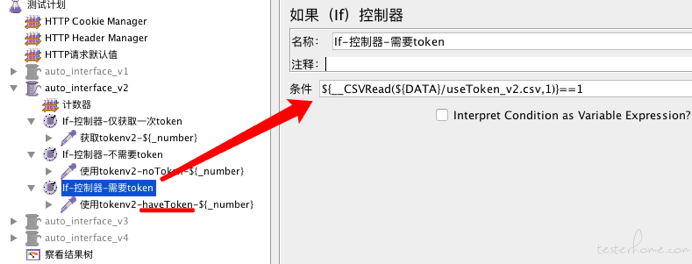
sampler-使用tokenv2-haveToken的请求body为:

{"flag":"${token}", ${__CSVRead(${DATA}/useToken_v2.csv,2)}
即请求body由两部分组成,一部分来自Jmeter内,主要是获取正确的token,另一部分来自useToken_v2.csv文件的第3列。
我们这里token正确时,另一个参数好像只有"appId":"001"这一种情况,显得好像这样写起来更加冗余,其实不然,我们appId也有可能为空,也可能错误。这时候我们的useToken_v2.csv文件应该会是这样:
用例1-token正确?1?"appId":"001"}
用例2-appId为空?1?"appId":""}
用例3-appId错误?1?"appId":"error appId "}
用例4-token为空?0?{"flag":"","appId":"002"}
用例5-token错误?0?{"flag":"errorToken","appId":"003"}
而且一个接口的入参不可能只有两个,但一般token只会有一个,所以当接口参数多时,这样写还是减少了一定量的sampler的重复率。
If:${__CSVRead(${DATA}/useToken_v2.csv,1)}==0
请求body就为:${__CSVRead(${DATA}/useToken_v2.csv,2)}

再解释一下这里为什了加了一个计算器,和接口名称为什么命名为使用tokenv2-noToken-${_number}。
首先,当我们把线程数设置为3时,其实getToken接口也跑了3次,但是其实我们只需要它跑一次,取出正确的token就可以了,getToken接口的if控制器跟计算器一起作用,当第1个线程启动时触发if控制器的规则${_number}==1,第2,第3个线程是就不会触发if控制器里面的getToken接口。
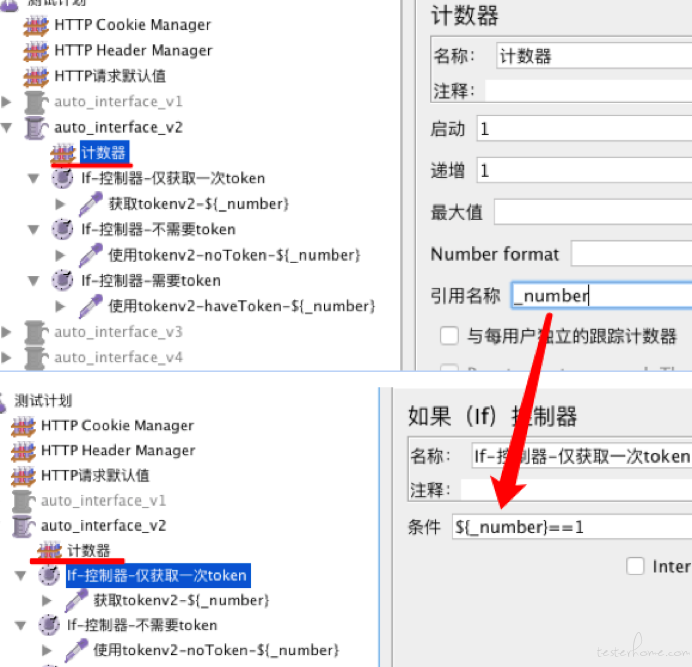
useToken接口命名后面加一个${_number},
使用tokenv2-noToken-${_number}和使用tokenv2-haveToken-${_number};主要是当接口报错时,可以根据接口的名称(其后面加了${_number},接口每个场景${_number}都是不一样的),判断其对应useToken_v2.csv文件的哪一行导致报错,可快速定位并进行报错修改。
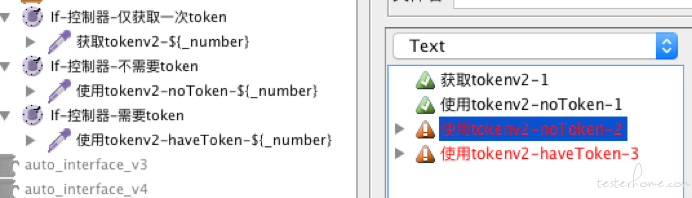
方便理解,给出运行效果图如下:
v3版本:
v2版本我们好像把我们能做的都给做了,但是前提是
从文件中读取,”${token}”读取出来的值就是字符串”${token}”,而不是我们想要的”19940622”!
随着时间的推移,楼主真的前前后后看过网上各种Jmeter教程和使用,不下40次,毕竟自己一直有信念,别人能做的自己也可以,1次看不懂的,那就看5次,5次还不懂,10次。不努力,没有办法比别人做得更好的。接着说随着时间的推移,grizz发现那个前提是可以打破的,因为Jmeter有个eval函数。
函数__eval可以用来执行一个字符串表达式,并返回执行结果。
举个栗子:
name=grizz
SQL=select * from able where name='${name}'
${ SQL }=select * from able where name='${name}'
${__eval(${SQL})}= select * from able where name='grizz'
现在我们可以设置useToken_v3.csv文件如下:
用例1-token正确?{"flag":"${token}","appId":"001"}?"returnFlag":"1000"
用例2-token为空?{"flag":"","appId":"002"}?"returnFlag":"1000"
用例3-token错误?{"flag":"errorToken","appId":"003"}?"returnFlag":"1000"
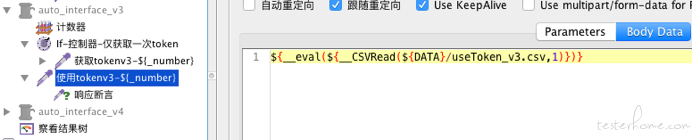
明显的,我们不需要if控制器来判断是否需要正确的Token了,脚本看起来清新了一些,而且我们把响应断言也从文件中读取。这样开发修改接口的返回提示时,我们可以直接通过修改csv文件完成对应的修改,不需要去动jmeter脚本。
入参:${__eval(${__CSVRead(${DATA}/useToken_v3.csv,1)})}
断言${__CSVRead(${DATA}/useToken_v3.csv,2)}
看到这我们可以思考一下,在v4版本还有哪些内容可以优化?
v4版本:
v1到v2是入门到掌握,v2到v3应该是弱鸡到熟悉,v4应该到星耀了吧,很想写个v5版本,v5(威武),应该很强的怕。
我们想想,我们的最终目标是实现写好接口自动化脚本后,接口变更的维护都只要操作csv文件。
那么当我们的useToken接口新增了一个场景,token过期
useToken_v4.csv文件
用例个数?4
用例1-token正确?{"flag":"${token}","appId":"001"}?"returnFlag":"1000"
用例2-token为空?{"flag":"","appId":"002"}?"returnFlag":"1000"
用例3-token错误?{"flag":"errorToken","appId":"003"}?"returnFlag":"1000"
用例4-token过期?{"flag":"oldToken","appId":"003"}?"returnFlag":"1000"
设置线程组auto_interface_v4的线程数为${__CSVRead(${DATA}/useToken_v4.csv,1)},其实就是文件useToken_v4.csv第一行的第二列,就是4
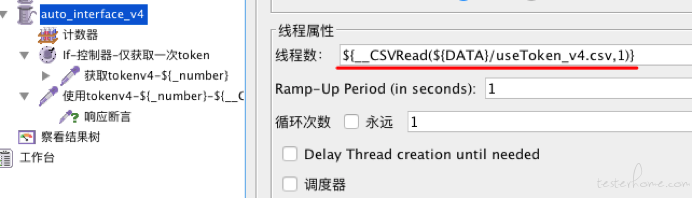
因为我们的线程数与我们的文件行数挂钩,但这里为什么文件有5行,而线程数是4。前面说了,因为对于csvRead函数,每一个线程都有独立的内部指针指向文件数组中的当前行。当某个线程第一次引用文件时,函数会为线程在数组中分配下一个空闲行。即Jmeter会分配一个线程去保存线程的属性,如线程数,启动时间,循环次数等。即当线程数设置为${__CSVRead(${DATA}/useToken_v4.csv,1)}时,控制线程属性的线程就读取了useToken_v4.csv文件的第一行。
PS:再说一下csvRead函数
csvRead函数默认从文件第一行开始读取,除非你二次开发,不然这个默认就一只在(苦笑),就是说我们不好加文件列的标题(当然可以利用v4版本的第一行也行),降低了文件的可读性。但当对某个文件进行第一次读取时,文件将被打开并读取到一个内部数组中。如果在读取过程中找到了空行,函数就认为到达文件末尾了,即允许拖尾注释。就是我们可以在文件写完后回车一下,再写一些文件的注释,或者${__CSVRead(D:/test.csv,next)}了解一下,csvRead函数的第二个值为next可自行进行文件行标的切换。
其实当我们的脚本量化后,还有很多东西要考虑的,接口csv文件的命名规范,线程组和sampler的命名规范,因为线程组和sampler的名称会在报告中体现,接口入口和出口标准,怎么维护我们的数据和脚本更优雅,怎样更高效的运行脚本和生成更丰富的报告,更加的节省测试人力。
下一篇讲一下jemter和ant,jenkins的持续集成
Jmeter+ant+Jenkins 接口自动化框架完整版
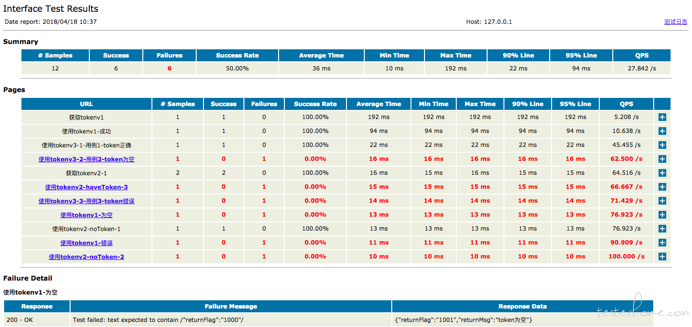
接口汇总报告:
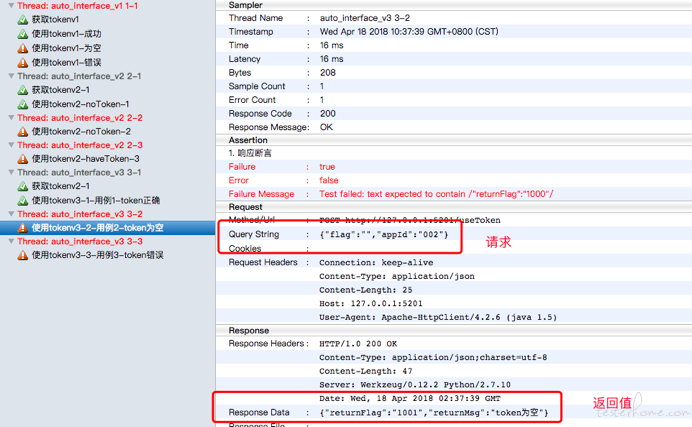
接口详细报告:
欢迎交流指正,感谢阅读。
Jmeter 接口自动化-脚本数据分离实例的更多相关文章
- Jenkins+Ant+Jmeter接口自动化集成测试实例
Jenkins+Ant+Jmeter接口自动化集成测试实例 一.Jenkins安装配置 1.安装配置JDK1.6+环境变量: 2.下载jenkins.war,放入C:\jenkins目录下,目录位置随 ...
- 纯python自研接口自动化脚本更新版本,让小白也能实现0到1万+的接口自动化用例
查看完整文章点击原文链接:纯python自研接口自动化脚本更新版本,让小白也能实现0到1万+的接口自动化用例 你是否还在用postman\jmeter做接口自动化吗?用python的开源框架[unit ...
- JMeter接口自动化发包与示例
JMeter接口自动化发包与示例 近期需要完成对于接口的测试,于是了解并简单做了个测试示例,看了看这款江湖上声名远播的强大的软件-Jmeter靠不靠谱. 官网:https://jmeter.apach ...
- 第9期《jmeter接口自动化实战》零基础入门!
2019年 第9期<jmeter接口自动化实战>课程,12月6号开学! 上课方式:QQ群视频在线教学 本期上课时间:12月6号-1月18号,每周五.周六晚上20:00-22:00 报名费: ...
- jmeter接口自动化-通过csv文件读取用例并执行测试
最近在公司测试中经常使用jmeter这个工具进行接口自动化,简单记录下~ 一.在csv文件中编写好用例 首先在csv文件首行填写相关参数(可根据具体情况而定)并编写测试用例.脚本可通过优先级参数控制执 ...
- jmeter接口自动化集成
接口自动化集成 一.jmeter基础学习 1.博客 :http://www.cnblogs.com/fnng/category/345478.html 2.博客 http://www.cnblo ...
- jmeter接口自动化部署jenkins教程
首先,保证本地安装并部署了jenkins,jmeter,xslproc 我搭建的自动化测试框架是jmeter+jenkins+xslproc ---注意:原理是,jmeter自生成的报告jtl文件,通 ...
- Jmeter接口自动化参数化 (转自软件测试部落)
测试场景: 有个查询城市(大概一百个 )天气预报的接口(需求参考第一课),需要根据不同的citycode,去查询对应城市的天气预报,这种接口该如何去测试呢? 分析需求: 不管是功能测试需求,还是接口测 ...
- jmeter接口自动化和性能学习目录
目录黑色代表未完成的,绿色代表已完成的文章.目录的作用的为了引导和总结自己的学习,也是为了更好的分享给大家. 一.接口自动化 jmeter解决登录token获取 jmeter五种提取器 之 正则表达 ...
随机推荐
- 由group by引发的sql_mode的学习
前言 在一次使用group by查询数据库时,遇到了问题.下面先搭建环境,然后让问题复现,最后分析问题. 一 问题复现 mysql版本 建表插入数据 表的结构 现在问题来了:我想查询上面表中每个部门年 ...
- JAVA笔记【类】
java的概述和编程基础在这里我就不过多的强调了,因为已经有学习C和C++的基础了,我在这里强调一下类和对象. [一]类的定义: Java类的定义包括类声明和类体两个部分,其中类体又包含变量声明,方法 ...
- nodeJS 中mongoose操作分页
开始前先聊聊五毛钱的: 好久没写了,可能是因为懒(哎),写这个是好事,既帮助了自己,巩固一下知识,也可以让别人给自己纠错纠错,三月份接触到了node,先是跟着一些教程写了一些小实例,感觉自己就喜欢上了 ...
- Java性能测试从入门到放弃-概述篇
Java性能测试从入门到放弃-概念篇 辅助工具 Jmeter: Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试.JMeter 可以用于对服务器.网络 ...
- 从 View 的四个构造方法说起
View 类的四个构造函数 写过自定义 View 的都知道,View 有四个构造函数,一般大家都知道第一个构造方法是简单的在代码中new View 的时候调用的,第二个构造方法使用最广泛,是对应的生成 ...
- Linux的权限属性信息1到10位分别什么意思
要设置权限,就需要知道文件的一些基本属性和权限的分配规则. 在Linux中,ls命令常用来查看文件的属性,用于显示文件的文件名和相关属性. #ls -l 路径 [ls -l 等价于 ...
- Python字典排序问题
字典的问题 navagation: 1.问题来源 2.dict的学习 *3.numpy的应用 1.问题来源 在做cs231n,assigment1-kNN实现的时候,需要对一个列表中的元素进行计数,并 ...
- 洛谷-P1414 又是毕业季II -枚举因子
P1414 又是毕业季II:https://www.luogu.org/problemnew/show/P1414 题意: 给定一个长度为n的数列.要求输出n个数字,每个数字代表从给定数列中最合理地取 ...
- CodeForces 834D The Bakery
The Bakery 题意:将N个数分成K块, 每块的价值为不同数字的个数, 现在求总价值最大. 题解:dp[i][j] 表示 长度为j 且分成 i 块的价值总和. 那么 dp[i][j] = max ...
- HZNU 2019 Summer training 6 -CodeForces - 622
A - Infinite Sequence CodeForces - 622A 题目大意:给你一个这样的数列1,1,2,1,2,3,1,2,3,4,1,2,3,4,5....就是从1~n排列(n++ ...