使用t-SNE做降维可视化
最近在做一个深度学习分类项目,想看看训练集数据的分布情况,但由于数据本身维度接近100,不能直观的可视化展示,所以就对降维可视化做了一些粗略的了解以便能在低维空间中近似展示高维数据的分布情况,以下内容不会很深入细节,但足以让你快速使用这门技术。
什么是降维可视化?
简而言之,降维是在2维或3维中展现更高维数据(具有多个特征的数据,且彼此具有相关性)的技术。
降维思想主要有两种:
- 仅保留原始数据集中最相关的变量(特征选择)。
- 寻找一组较小的新变量,其中每个变量都是输入变量的组合,包含与输入变量基本相同的信息(降维)。
什么时候需要用到降维可视化?
如果你的数据集有数十个或者数百个特征,而你想直观的看出数据集样本之间的分布情况,那么降到2维或3维来展示这种分布是一个不错的选择。
有哪些主流的降维可视化方法?
降维可视化方法其实还挺多的,但是最常见的是以下三种:
- t-SNE
t-分布式随机邻域嵌入是一种用于挖掘高维数据的非线性降维算法。 它将多维数据映射到适合于人类观察的两个或多个维度。sklearn中已有相应的实现,用起来很方便。 - PCA
主成分分析,是一种线性降维方法,虽然快,但相比非线性降维丢失的信息更多。 - LargeVis
一种在t-SNE之上提出的更快的,效果和t-SNE差不多的降维算法,项目地址:https://github.com/lferry007/LargeVis
t-SNE的原理?
我们知道,数据降维后,数据中的信息是有一定的损失量的,这个损失量在t-SNE方法中,是采用K-L散度来计算的。
K-L散度计算的是“用一个分布q来近似另一个分布p时的信息损失量”,其公式如下:

我们知道,对于一组离散型随机变量{x1,x2,...,xn},其期望值=x1* x1的概率+x2 * x2的概率+xn * xn的概率,所以上式可以用期望值表达成分布p和分布q之间的对数差值的期望,这里对数差值对应之前说的一组随机变量:

更一般的写法如下,根据log a - log b = log (a/b):

K-L散度越小,表示信息损失越小,两个分布越相近。
现在回到t-SNE,我们使用t-SNE是为了将高维数据用低维数据来表达,以便能够可视化。那么这里就涉及到2种分布,一个是高维数据的分布p,一个是低维数据的分布q,想让低维数据能够最好的表达高维的情况,就可以将K-L散度公式做为损失函数,通过最小化散度来学习出q分布下的各样本点。
目标函数:

其中:
p分布是基于高斯分布来构建的,表达了两点之间的相似度,对比高斯公式可以看到,这里用xi表示了总体均值μ,所以这里说的相似度是通过以样本点i为均值时,样本点i与其相差几个标准差来表达的:

q分布也是基于高斯分布来构建的,但是指定了标准差σ=1/√2(即我们规定用这样的分布来近似高维的分布),所以相比上面少了σ的参数项。

上面说的其实是SNE方法,t-SNE相对SNE的区别如下:
- 使用联合概率(xi和xj同时出现的概率)代替条件概率(xi出现的条件下xj出现的概率、xj出现的条件下,xi出现的概率),调整后的公式如下:

- 低维空间下,使用t分布代替高斯分布表达两点之间的相似度,调整后的q分布和梯度如下:


这样调整后,梯度计算会更加简洁,并且在这样得梯度公式下,当遇到高维空间中距离不相近,但是低维空间中距离相近的样本点,也会产生较大的梯度,让模型学习到这些点在低维空间中并不靠的近,也就是说这样会使得高维空间相似的样本在低维空间靠的更近,高维空间不相似的点在低维空间分的更开,避免SNE经常出现的拥挤(各个簇聚在一起无法区分)问题。
如何使用t-SNE?
看一个对手写数字图片进行二维可视化的例子,效果如下:
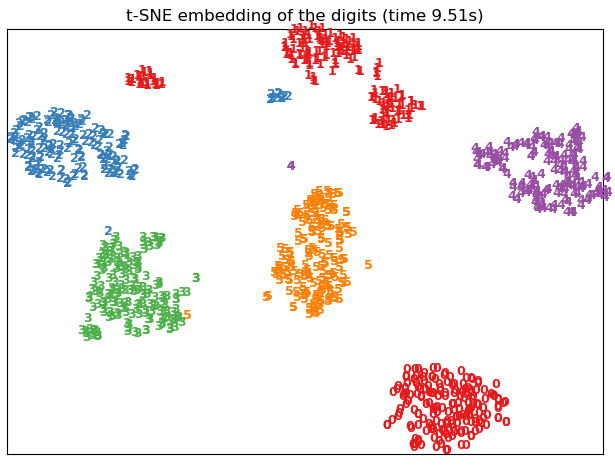
代码如下:
"""
t-SNE对手写数字进行可视化
"""
from time import time
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.manifold import TSNE
def get_data():
digits = datasets.load_digits(n_class=6) # 取数字0-5
data = digits.data
label = digits.target
n_samples, n_features = data.shape
return data, label, n_samples, n_features
def plot_embedding(data, label, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure()
ax = plt.subplot(111)
for i in range(data.shape[0]):
plt.text(data[i, 0], data[i, 1], str(label[i]),
color=plt.cm.Set1(label[i] / 10.),
fontdict={'weight': 'bold', 'size': 9})
plt.xticks([])
plt.yticks([])
plt.title(title)
return fig
def main():
data, label, n_samples, n_features = get_data()
print('Computing t-SNE embedding')
# 降到2维
tsne = TSNE(n_components=2, init='pca', random_state=0)
t0 = time()
result = tsne.fit_transform(data)
plot_embedding(result, label,
't-SNE embedding of the digits (time %.2fs)'
% (time() - t0))
plt.show()
if __name__ == '__main__':
main()
参考资料:
http://www.datakit.cn/blog/2017/02/05/t_sne_full.html#25-不足
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
使用t-SNE做降维可视化的更多相关文章
- 手把手教你用FineBI做数据可视化
前些日子公司引进了帆软商业智能FineBI,在接受了简单的培训后,发现这款商业智能软件用作可视分析只用一个词形容的话,那就是“轻盈灵动”!界面简洁.操作流畅,几个步骤就可以创建分析,获得想要的效果.此 ...
- 2021年都要过去啦,你还在用Excel做数据可视化效果吗?
2021年都要过去啦,你还在用Excel做数据可视化效果吗?古语有云,"工欲善其事,必先利其器",没有专业的工具,前期准备的再好也是白搭.现在运用数据可视化工具于经营活动中的企业是 ...
- BI工具做数据可视化项目频频失败的原因
现如今数据可视化可谓是非常之火,随着硬件价格的一降再降,仿佛做数据可视化项目,你没有数据大屏,你就没有逼格.理想很丰满,现实很骨感,并不是每一个数据可视化项目都能够成功.数据可视化项目的进行,无外乎是 ...
- 为什么有些BI工具做数据可视化项目频频失败?
现如今数据可视化可谓是非常之火,随着硬件价格的一降再降,仿佛做数据可视化项目,你没有数据大屏,你就没有逼格.理想很丰满,现实很骨感,并不是每一个数据可视化项目都能够成功.数据可视化项目的进行,无外乎是 ...
- 毕业论文着急了?Python疫情数据分析,并做数据可视化展示
采集流程 一..明确需求 采集/确诊人数/新增人数 二.代码流程 四大步骤 发送请求 获取数据 网页源代码 解析数据 筛选一些我想用的数据 保存数据 保存成表格 做数据可视化分析 开始代码 1. 发送 ...
- 【Python代码】TSNE高维数据降维可视化工具 + python实现
目录 1.概述 1.1 什么是TSNE 1.2 TSNE原理 1.2.1入门的原理介绍 1.2.2进阶的原理介绍 1.2.2.1 高维距离表示 1.2.2.2 低维相似度表示 1.2.2.3 惩罚函数 ...
- tsne降维可视化
Python代码:准备训练样本的数据和标签:train_X4000.txt.train_y4000.txt 放于tsne.py当前目录.(具体t-SNE – Laurens van der Maate ...
- 用Arduino做一个可视化网络威胁级别指示器!
在当今世界,网络监控器是非常重要的.互联网是个可怕的地方.人们已经采取措施以提高警戒----他们安装了入侵检测系统(IDS)比如SNORT. 通过把可视化部分从电脑中移出来,我们想让它更容易去观察.一 ...
- 这么多房子,哪一间是我的小窝?python采集数据并做数据可视化~
前言 嗨喽,大家好呀!这里是小熊猫 环境使用: (https://jq.qq.com/?_wv=1027&k=ONMKhFSZ) Python 3.8 Pycharm 模块使用: (https ...
随机推荐
- 【译】为什么永远都不要使用MongoDB Why You Should Never Use MongoDB
背景 最近在学习DDIA(Designing Data-Intensive Applications)这本分布式领域非常急经典的入门书籍,里面第二章<数据模型与查询语言>,强调了对一对多. ...
- Mysql数据库调优和性能优化的21条最佳实践
Mysql数据库调优和性能优化的21条最佳实践 1. 简介 在Web应用程序体系架构中,数据持久层(通常是一个关系数据库)是关键的核心部分,它对系统的性能有非常重要的影响.MySQL是目前使用最多的开 ...
- day20191102笔记
当日所学默写笔记: 1.select id="唯一,必须写,对应的接口方法名称" resultType="必须写,返回的类型是对应持久化数据层的全限定类名或者是其别名&q ...
- 后端传给前端Long类型数据,导致精度丢失
1.前几天遇到了一个问题,后端向前端传递一个Long类型的数据,前端拿到的值不对. 2.当Long类型的数据大于17位时候,就会出现精度丢失的情况. 3.解决办法 我们采用的解决方案是将后端的Long ...
- git本地项目连接私人远程仓库以及遇到的问题
一.引言 1.最开始的时候,我本地项目连接的是github远程仓库,现在要转到公司的私人远程仓库. 2.我和大家说两个事: (1)本地项目连接github远程仓库, (2)本地项目连接私人远程仓库, ...
- EFK教程(4) - ElasticSearch集群TLS加密通讯
基于TLS实现ElasticSearch集群加密通讯 作者:"发颠的小狼",欢迎转载 目录 ▪ 用途 ▪ ES节点信息 ▪ Step1. 关闭服务 ▪ Step2. 创建CA证书 ...
- Xtrabackup 安装 参数详解
目录 安装 常用参数详解 innobackupex 相关参数 xtrabackup相关参数 安装 继Xtrabackup 介绍,本次来讲解安装和使用. Xtrabackup的RPM包下载地址: 系统版 ...
- C#使用Consul集群进行服务注册与发现
前言 我个人觉得,中间件的部署与使用是非常难记忆的:也就是说,如果两次使用中间件的时间间隔比较长,那基本上等于要重新学习使用. 所以,我觉得学习中间件的文章,越详细越好:因为,这对作者而言也是一份珍贵 ...
- MySql简单的增删改查语句 js
最近在项目中需要连接数据库,做增删改查的功能,sql语句整理做了以下记录(基于NodeJs,注:data为你的真实数据): (一)新增插入表中数据: sql: 'insert into work(表名 ...
- Multi-Camera Coordination and Control in Surveillance Systems: A Survey 阅读笔记
原文: Natarajan, Prabhu, Pradeep K. Atrey, and Mohan Kankanhalli. "Multi-camera coordination and ...