spark源码阅读---Utils.getCallSite
1 作用
当该方法在spark内部代码中调用时,会返回当前调用spark代码的用户类的名称,以及其所调用的spark方法。所谓用户类,就是我们这些用户使用spark api的类。
2 内部实现
2.1 涉及到的java或scala知识
(1)Thread.currentThread.getStackTrace():返回一个表示该线程堆栈转储的堆栈跟踪元素数组。如果该线程尚未启动或已经终止,则该方法将返回一个零长度数组。如果返回的数组不是零长度的,则其第一个元素代表堆栈顶,它是该序列中最新的方法调用。最后一个元素代表堆栈底,是该序列中最旧的方法调用。返回数组的每个元素是一个StackTraceElement对象,存储了该方法由哪个类声明,方法名,以及文件名,文件第几行。如下:

(2)System.getProperty():返回一个系统属性值,其实就是一个配置参数值。
(3)case class:是scala中一种特殊的class。
2.2 spark源码部分
(1)该方法传入一个参数skipClass函数,用来判断哪些类名需要跳过,默认的判断函数也在Utils文件内部,如下:
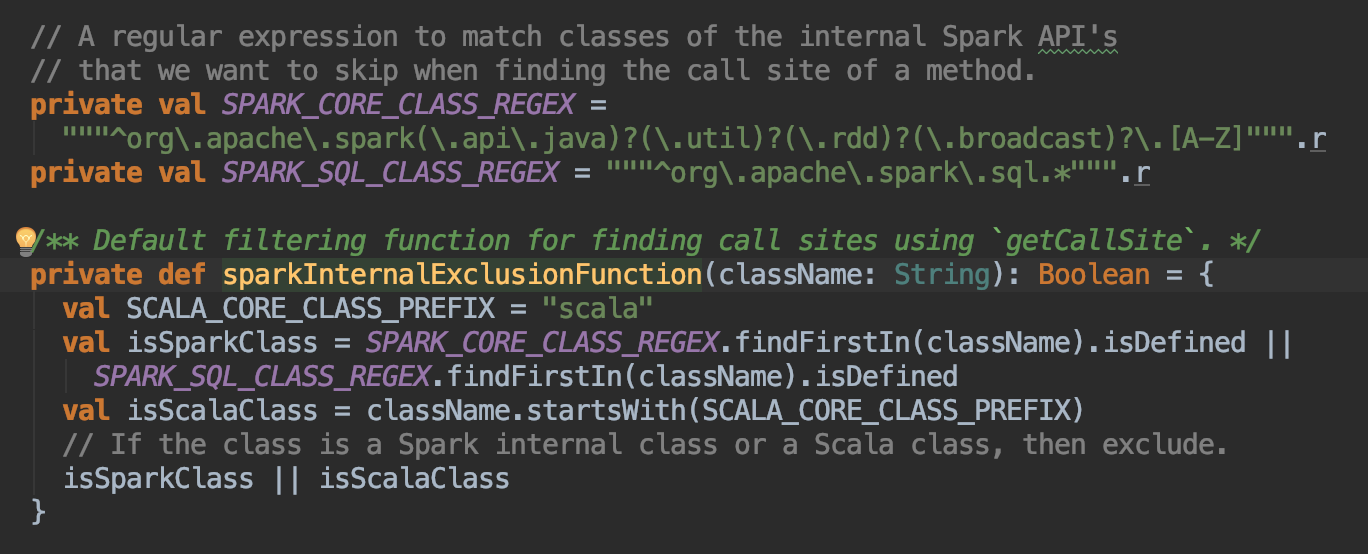
可见,默认的判断函数是通过正则表达式来判断的,其将会过滤出spark和scala的原生类。
(2)该方法维护了lastSparkMethod以及firstUserFile,firstUserLine,callStack。其中lastSparkMethod是表示直接被用户api调用的spark方法,firstUserFile是最深的(直接调用spark api的)用户方法的文件名,callStack存储了调用栈信息,callStack[0]就是lastSparkMethod,其后为所有的用户方法。源码如下:
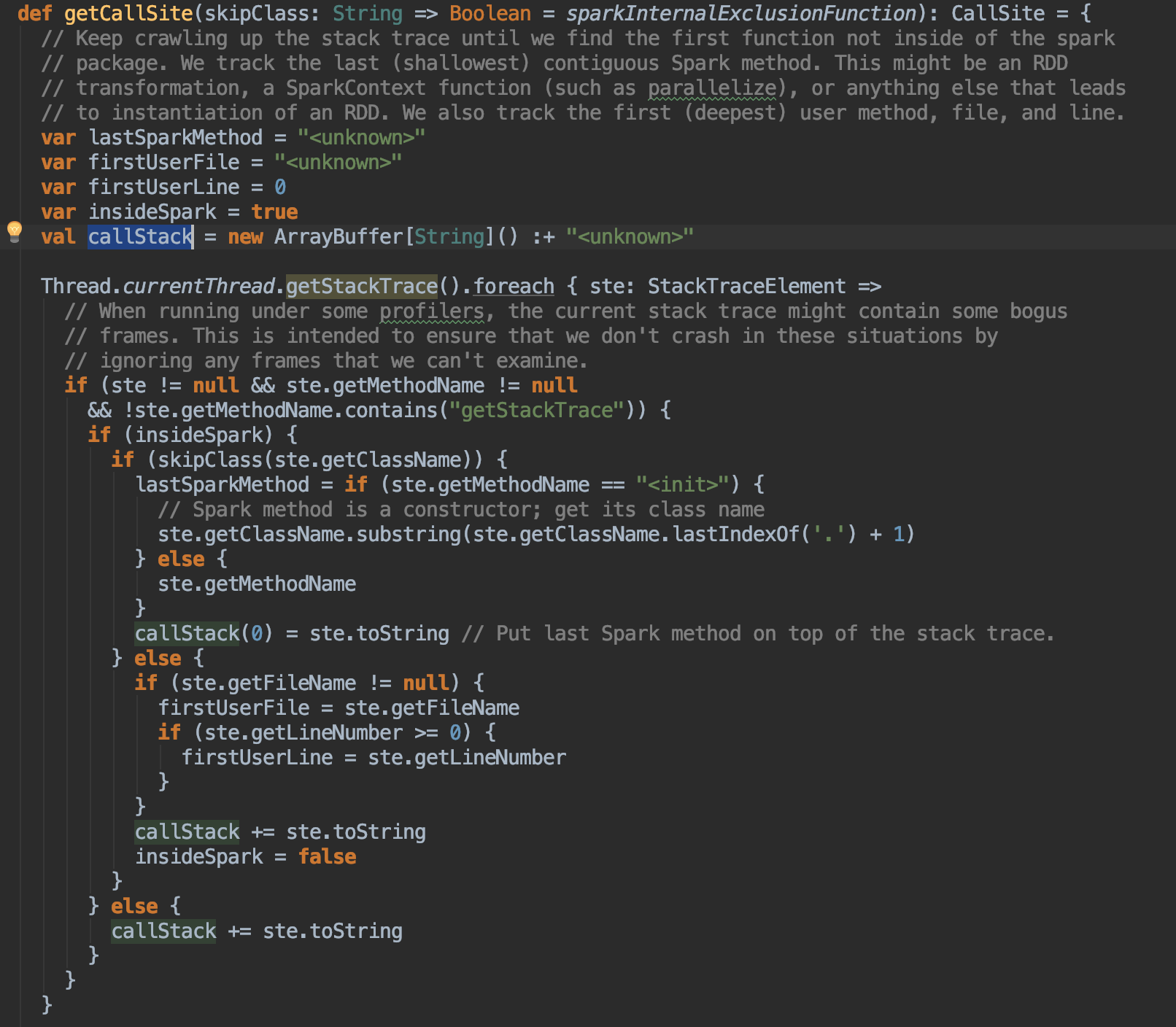
(3)该方法的最后工作,是根据上面得到的信息封装一个CallSite类:

CallSite类是一个case class:

spark源码阅读---Utils.getCallSite的更多相关文章
- Spark源码阅读之存储体系--存储体系概述与shuffle服务
一.概述 根据<深入理解Spark:核心思想与源码分析>一书,结合最新的spark源代码master分支进行源码阅读,对新版本的代码加上自己的一些理解,如有错误,希望指出. 1.块管理器B ...
- win7+idea+maven搭建spark源码阅读环境
1.参考. 利用IDEA工具编译Spark源码(1.60~2.20) https://blog.csdn.net/He11o_Liu/article/details/78739699 Maven编译打 ...
- spark源码阅读
根据spark2.2的编译顺序来确定源码阅读顺序,只阅读核心的基本部分. 1.common目录 ①Tags②Sketch③Networking④Shuffle Streaming Service⑤Un ...
- spark源码阅读--SparkContext启动过程
##SparkContext启动过程 基于spark 2.1.0 scala 2.11.8 spark源码的体系结构实在是很庞大,从使用spark-submit脚本提交任务,到向yarn申请容器,启 ...
- emacs+ensime+sbt打造spark源码阅读环境
欢迎转载,转载请注明出处,徽沪一郎. 概述 Scala越来越流行, Spark也愈来愈红火, 对spark的代码进行走读也成了一个很普遍的行为.不巧的是,当前java社区中很流行的ide如eclips ...
- Spark 源码阅读——任务提交过程
当我们在使用spark编写mr作业是,最后都要涉及到调用reduce,foreach或者是count这类action来触发作业的提交,所以,当我们查看这些方法的源码时,发现底层都调用了SparkCon ...
- spark源码阅读--shuffle过程分析
ShuffleManager(一) 本篇,我们来看一下spark内核中另一个重要的模块,Shuffle管理器ShuffleManager.shuffle可以说是分布式计算中最重要的一个概念了,数据的j ...
- Spark源码阅读(1): Stage划分
Spark中job由action动作生成,那么stage是如何划分的呢?一般的解答是根据宽窄依赖划分.那么我们深入源码看看吧 一个action 例如count,会在多次runJob中传递,最终会到一个 ...
- spark源码阅读之network(1)
spark将在1.6中替换掉akka,而采用netty实现整个集群的rpc的框架,netty的内存管理和NIO支持将有效的提高spark集群的网络传输能力,为了看懂这块代码,在网上找了两本书看< ...
随机推荐
- c++书籍推荐《C++编码规范》下载
百度云及其他网盘下载地址:点我 编辑推荐 <C++编程规范:101条规则.准则与 实践>:良好的编程规范可以改善软件质量,缩短上市时间,提升团队效率,简化维护工作.在<C++编程规范 ...
- nodejs进阶(1)——npm使用技巧和最佳实践
nodejs进阶教程,小白绕道!!! npm使用技巧和最佳实践 前提:请确保安装了node.js npm的最佳实践 npm install是最常见的npm cli命令,但是它还有更多能力!接下来你会了 ...
- Spring MVC源码(二) ----- DispatcherServlet 请求处理流程 面试必问
前端控制器 前端控制器,即所谓的Front Controller,体现的是设计模式中的前端控制器模式.前端控制器处理所有从用户过来的请求.所有用户的请求都要通过前端控制器.SpringMVC框架和其他 ...
- App强更逻辑实现以及版本号如何判断大小
//在开发中,经常会遇到有些需求需要app强更,思路大概:所有请求都要带上版本号和渠道(android或ios),然后网关对这些版本号判断,如果发现这些版本号是很旧的,就返回错误码或者标志符告诉app ...
- Bzoj: 2073 [POI2004]PRZ 题解
2073: [POI2004]PRZ Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 401 Solved: 296[Submit][Status][D ...
- free()函数释放一段分配的内存之陷阱
朋友们对malloc函数应该是比较熟悉了,此函数功能是分配一段内存地址,并且将内存地址给一个指针变量,最后记得再调用free函数释放这段内存地址就可以了,标准的流程对吧,好像没什么问题.但是按照此标准 ...
- Junit简单的案例
Calculator: public class Calculator { public double add(double number1, double number2) { return num ...
- 【基本数据结构】并查集-C++
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中.这一类问题近几年来反复出 ...
- 【带着canvas去流浪(12)】用Three.js制作简易的MARVEL片头动画(上)
目录 一. 大作业说明 二.基本思路 三.视频纹理表面修复--UV映射 3.1 问题描述 3.2 纹理贴图的基本原理-UV映射 3.3 关键示例代码 四.小结 示例代码托管在:http://www.g ...
- CF392BTower of Hanoi(记忆化搜索)
CF392B 记搜好题 预处理 题目给出了将一个盘从x移到y的代价(代码中为a[][]),当我们知道这并不是最优的 就像最短路floyd一样松弛操作预处理得到两柱之间最优值b[][] for(int ...