什么是redis的缓存雪崩与缓存穿透
今天来分享一下Redis几道常见的面试题:
- 如何解决缓存雪崩?
- 如何解决缓存穿透?
- 如何保证缓存与数据库双写时一致的问题?
一、缓存雪崩
1.1 什么是缓存雪崩?
首先我们先来回答一下我们为什么要用缓存(Redis):
1、提高性能能:缓存查询是纯内存访问,而硬盘是磁盘访问,因此缓存查询速度比数据库查询速度快
2、提高并发能力:缓存分组了部分请求,支持更高的并发
现在有个问题,如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了。
我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期时间,将已经过期的键值对删除,它采用的是惰性删除+定期删除两种策略对过期键删除。
如果缓存数据设置的过期时间是相同的,并且Redis恰好将这部分数据全部删光了。这就会导致在这段时间内,这些缓存同时失效,全部请求到数据库中。
这就是缓存雪崩:
- Redis挂掉了,请求全部走数据库。
- 对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
缓存雪崩如果发生了,很可能就把我们的数据库搞垮,导致整个服务瘫痪!
1.2 如何解决缓存雪崩?
对于“对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。”这种情况,非常好解决:
- 解决方法:在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于“Redis挂掉了,请求全部走数据库”这种情况,我们可以有以下的思路:
- 事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
- 事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
- 事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
二、缓存穿透
2.1什么是缓存穿透
比如,我们有一张数据库表,ID都是从1开始的(正数),但是可能有黑客想把我的数据库搞垮,每次请求的ID都是负数。这会导致我的缓存就没用了,请求全部都找数据库去了,但数据库也没有这个值啊,所以每次都返回空对象出去。
缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
这就是缓存穿透:
- 请求的数据在缓存大量不命中,导致请求走数据库。
缓存穿透如果发生了,也可能把我们的数据库搞垮,导致整个服务瘫痪!
2.1如何解决缓存穿透?
解决缓存穿透也有两种方案:
由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
这种情况我们一般会将空对象设置一个较短的过期时间。
三、缓存与数据库双写一致
3.1对于读操作,流程是这样的
上面讲缓存穿透的时候也提到了:如果从数据库查不到数据则不写入缓存。
一般我们对读操作的时候有这么一个固定的套路:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求
3.2什么是缓存与数据库双写一致问题?
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要更新时候呢?各种情况很可能就造成数据库和缓存的数据不一致了。
- 这里不一致指的是:数据库的数据跟缓存的数据不一致
从理论上说,只要我们设置了键的过期时间,我们就能保证缓存和数据库的数据最终是一致的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来尽量避免数据库与缓存处于不一致的情况发生。
3.3对于更新操作
一般来说,执行更新操作时,我们会有两种选择:
- 先操作数据库,再操作缓存
- 先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这两个操作要么同时成功,要么同时失败。所以,这会演变成一个分布式事务的问题。
所以,如果原子性被破坏了,可能会有以下的情况:
- 操作数据库成功了,操作缓存失败了。
- 操作缓存成功了,操作数据库失败了。
如果第一步已经失败了,我们直接返回Exception出去就好了,第二步根本不会执行。
下面我们具体来分析一下吧。
3.3.1操作缓存
操作缓存也有两种方案:
- 更新缓存
- 删除缓存
一般我们都是采取删除缓存缓存策略的,原因如下:
- 高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就更加容易导致数据库与缓存数据不一致问题。(删除缓存直接和简单很多)
- 如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
3.3.2先更新数据库,再删除缓存
正常的情况是这样的:
- 先操作数据库,成功;
- 再删除缓存,也成功;
如果原子性被破坏了:
- 第一步成功(操作数据库),第二步失败(删除缓存),会导致数据库里是新数据,而缓存里是旧数据。
- 如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的概率特别低,也不是没有:
- 缓存刚好失效
- 线程A查询数据库,得一个旧值
- 线程B将新值写入数据库
- 线程B删除缓存
- 线程A将查到的旧值写入缓存
要达成上述情况,还是说一句概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
对于这种策略,其实是一种设计模式:Cache Aside Pattern
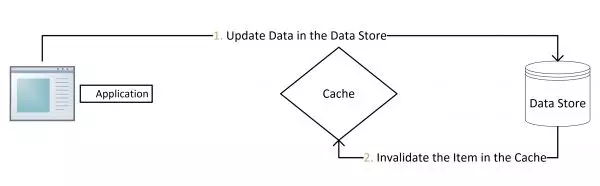
删除缓存失败的解决思路:
- 将需要删除的key发送到消息队列中
- 自己消费消息,获得需要删除的key
- 不断重试删除操作,直到成功
3.3.3先删除缓存,再更新数据库
正常情况是这样的:
- 先删除缓存,成功;
- 再更新数据库,也成功;
如果原子性被破坏了:
- 第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
- 如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
- 线程A删除了缓存
- 线程B查询,发现缓存已不存在
- 线程B去数据库查询得到旧值
- 线程B将旧值写入缓存
- 线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
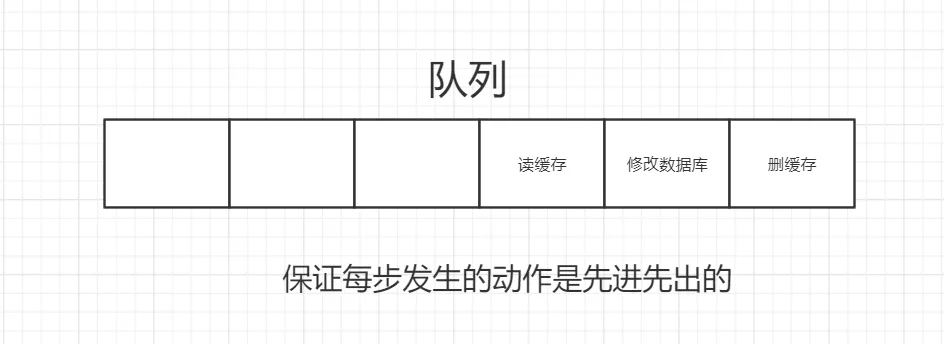
并发下解决数据库与缓存不一致的思路:
- 将删除缓存、修改数据库、读取缓存等的操作积压到队列里边,实现串行化。
3.4对比两种策略
我们可以发现,两种策略各自有优缺点:
- 先删除缓存,再更新数据库
- 在高并发下表现不如意,在原子性被破坏时表现优异
- 先更新数据库,再删除缓存(
Cache Aside Pattern设计模式) - 在高并发下表现优异,在原子性被破坏时表现不如意
什么是redis的缓存雪崩与缓存穿透的更多相关文章
- Redis总结(五)缓存雪崩和缓存穿透等问题
前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhong/category/771056.html .今 ...
- Redis缓存雪崩、缓存穿透、热点Key解决方案和分析
缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题(转载)
前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhong/category/771056.html .今 ...
- Redis缓存雪崩、缓存穿透、缓存击穿、缓存降级、缓存预热、缓存更新
Redis缓存能够有效地加速应用的读写速度,就DB来说,Redis成绩已经很惊人了,且不说memcachedb和Tokyo Cabinet之流,就说原版的memcached,速度似乎也只能达到这个级别 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- SpringBoot微服务电商项目开发实战 --- Redis缓存雪崩、缓存穿透、缓存击穿防范
最近已经推出了好几篇SpringBoot+Dubbo+Redis+Kafka实现电商的文章,今天再次回到分布式微服务项目中来,在开始写今天的系列五文章之前,我先回顾下前面的内容. 系列(一):主要说了 ...
- Redis缓存雪崩,缓存穿透,热点key解决方案和分析
缓存穿透 缓存系统,按照KEY去查询VALUE,当KEY对应的VALUE一定不存在的时候并对KEY并发请求量很大的时候,就会对后端造成很大的压力. (查询一个必然不存在的数据.比如文章表,查询一个不存 ...
- Redis之缓存雪崩、缓存穿透、缓存预热、缓存更新、缓存降级
目录 Redis之缓存雪崩.缓存穿透.缓存预热.缓存更新.缓存降级 1.缓存雪崩 2.缓存穿透 3.缓存预热 4.缓存更新 5.缓存降级 Redis之缓存雪崩.缓存穿透.缓存预热.缓存更新.缓存降级 ...
- 实例解读什么是Redis缓存穿透、缓存雪崩和缓存击穿
from:https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc Redis缓存的使用,极大的提升 ...
- Redis中的缓存雪崩与缓存穿透
1.缓存雪崩 1.1什么是缓存雪崩? 如果我们的缓存挂掉了,这意味着我们的全部请求都跑去数据库了. 我们都知道Redis不可能把所有的数据都缓存起来(内存昂贵且有限),所以Redis需要对数据设置过期 ...
随机推荐
- 【JVM】01虚拟机内存模型
学习链接:https://blog.csdn.net/u010425776/article/details/51170118 博主整理的条理清晰,在这里先感谢博主分享 去年看视频学习写过一篇JVM的博 ...
- [apue] 管道原子写入量的一个疑问
PIPE_BUF定义了管道可原子写入的数据量,在我的系统(CentOS 6.7)上这个值是4096,写了个程序验证了一下,通过三个维度来考察: N: 生产者数量 M:每个生产者的生产次数 P:每次写入 ...
- 源码解读·RT-Thread操作系统从开机到关机
本篇内容比较简单,但却很繁琐,篇幅也很长,毕竟是囊括了整个操作系统的生命周期.这篇文章的目的是作为后续设计多任务开发的铺垫,后续会单独再抽出一篇分析任务的相关知识.另外本篇文章以单核MCU为背景,并且 ...
- 并发编程-concurrent指南-Lock-可重入锁(ReentrantLock)
可重入和不可重入的概念是这样的:当一个线程获得了当前实例的锁,并进入方法A,这个线程在没有释放这把锁的时候,能否再次进入方法A呢? 可重入锁:可以再次进入方法A,就是说在释放锁前此线程可以再次进入方法 ...
- Redis主从复制实现原理
一.Redis2.8之前的版本, 首先redis复制功能分为同步操作和命令传播两个操作 同步操作作于将从服务器的数据库状态更新至主服务器当前所处的数据库状态 命令传播操作则用于在主服务器的数据库状态 ...
- STM32F0_HAL库驱动描述——基于F1的USART串口IT中断实现解析
从原子F103 HAL库基础串口例程来看HAL程序结构: 从main函数开始,首先是HAL库两个函数的初始化: HAL_Init(): Stm32_Clock_Init(RCC_PLL_MUL9); ...
- STM32F072从零配置工程-建立工程文件
快速建立工程有两种方法: 第一种是通过官方提供的外设库来搭建,好处是使用库函数,而不需要深入研究寄存器配置: 第二种是通过STM32CubeMX,好处是直观快速,可以直接帮你配置好功能和时钟,不过使用 ...
- Jenkins Ci系列目录
Jenkins入门篇 1.Jenkins入门之界面概览 2.Jenkins入门之新建任务 3.Jenkins入门之导航操作 4.Jenkins入门之任务基本操作 5.Jenkins入门之执行Power ...
- 网页判断浏览器是否安装flash
<script> //检验flash版本 以及falsh是否安装 function detectFlash() { try { if(navigator.mimeTypes.length& ...
- markdown浅谈
markdown是啥? markdown就是一种修饰网页/博客的方法,他能使网页变得更美观. 我们先解释一下代码框: 这个没法保留,就是把键盘左上角的⋅·⋅ 切换成英文变成`. 然后``` 在隔一行` ...