sklearn--模型的评价
sklearn.metrics
1.MSE(均方误差)和RMSE(均方根误差),以及score()
lr.score(test_x,test_y)#越接近1越好,负的很差
from sklearn.metrics import mean_squared_error
mean_squared_error(test_y,lr.predict(test_x))#mse
np.sqrt(mean_squared_error(test_y,lr.predict(test_x)))
from sklearn.metrics import accuracy_score
print(accuracy_score(predict_results, target_test))
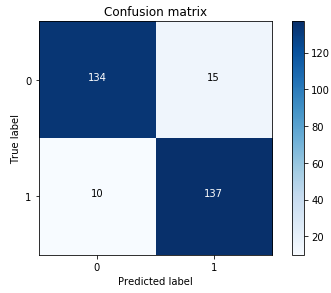
2.混淆矩阵
混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第二行第一列的2表示有2个实际归属为第二类的实例被错误预测为第一类。
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
import seaborn as sns
sns.heatmap(cnf_matrix,cmap="Blues",annot=True,fmt='d',square=True)
plt.ylabel('True Label')
plt.xlabel('pre Label')
plt.title('Confusion matrix')
学习曲线
通过观察训练集和测试集的得分来看两个曲线的靠近程度,如果是两个曲线的方差太大,测试集差训练集好,则说明是过拟合,如果两个曲线方差不太大,两个的训练的效果都不好,这就说明是欠拟合
from sklearn.model_selection import learning_curve #绘制学习曲线,以确定模型的状况
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
"""
plt.figure()
train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes,scoring='neg_mean_squared_error')
train_scores=np.sqrt(-train_scores)
test_scores=np.sqrt(-test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show() #少样本的情况情况下绘出学习曲线

sklearn--模型的评价的更多相关文章
- sklearn 模型选择和评估
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- sklearn模型保存与加载
sklearn模型保存与加载 sklearn模型的保存和加载API 线性回归的模型保存加载案例 保存模型 sklearn模型的保存和加载API from sklearn.externals impor ...
- python sklearn模型的保存
使用python的机器学习包sklearn的时候,如果训练集是固定的,我们往往想要将一次训练的模型结果保存起来,以便下一次使用,这样能够避免每次运行时都要重新训练模型时的麻烦. 在python里面,有 ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn模型保存
使用sklearn训练完模型之后,只有将模型持久化到硬盘上,才能方便下次直接使用. 第一种方式:使用pickle >>> from sklearn import svm >&g ...
- sklearn 模型评估
原文链接 http://d0evi1.com/sklearn/model_evaluation/ 预测值:pred 真实值:y_test #### 直接用平均值 ``` mean(pred == y_ ...
- Sklearn,TensorFlow,keras模型保存与读取
一.sklearn模型保存与读取 1.保存 from sklearn.externals import joblib from sklearn import svm X = [[0, 0], [1, ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- python进行机器学习(四)之模型验证与参数选择
一.模型验证 进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数据的表现效果. 这里我们将 ...
随机推荐
- Nmap工具介绍
使用方法 实例: nmap -v scanme.nmap.org 这个选项扫描主机scanme.nmap.org中 所有的保留TCP端口.选项-v启用细节模式. nmap -sS -O scanme. ...
- 【计算机视觉】双目测距(六)--三维重建及UI显示
原文: http://blog.csdn.NET/chenyusiyuan/article/details/5970799 在获取到视差数据后,利用 OpenCV 的 reProjectImageTo ...
- 洛谷 题解 UVA1626 【括号序列 Brackets sequence】
看还没有人发记搜的题解,赶紧来水发一篇 我们定义dp[i][j]为区间i~j内最少添加几个括号才能把这个串变成正规括号序列. 考虑四种情况 i>j不存在这种子串,返回0 i==j子串长度为1无论 ...
- 学习笔记:CentOS7学习之二十一: 条件测试语句和if流程控制语句的使用
目录 学习笔记:CentOS7学习之二十一: 条件测试语句和if流程控制语句的使用 21.1 read命令键盘读取变量的值 21.1.1 read常用见用法及参数 21.2 流程控制语句if 21.2 ...
- Spring mybatis源码篇章-Mybatis的XML文件加载
通过阅读源码对实现机制进行了解有利于陶冶情操,承接前文Spring mybatis源码篇章-Mybatis主文件加载 前话 前文主要讲解了Mybatis的主文件加载方式,本文则分析不使用主文件加载方式 ...
- mysql 不支持group by的解决方案
进入mysql命令行 执行如下两句语句 set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_ ...
- JS实现级联菜单
是首先应该添加两个下拉列表并设置id属性来方便操作: <select id="country"> <option>国家</option> < ...
- Hadoop环境搭建过程中遇到的问题以及解决方法
1.启动hadoop之前,ssh免密登录slave主机正常,使用命令start-all.sh启动hadoop时,需要输入slave主机的密码,说明ssh文件权限有问题,需要执行以下操作: 1)进入.s ...
- Solr 8.2 使用指南
1 Solr简介 1.1 Solr是什么 Solr是一个基于全文检索的企业级应用服务器.可以输入一段文字,通过分词检索数据.它是单独的服务,部署在 tomcat. 1.2 为什么需要Solr 问题:我 ...
- Spring中@Component与@Bean的区别
@Component和@Bean的目的是一样的,都是注册bean到Spring容器中. @Component VS @Bean @Component 和 它的子类型(@Controller, @S ...