Scrapy开发指南
一、Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
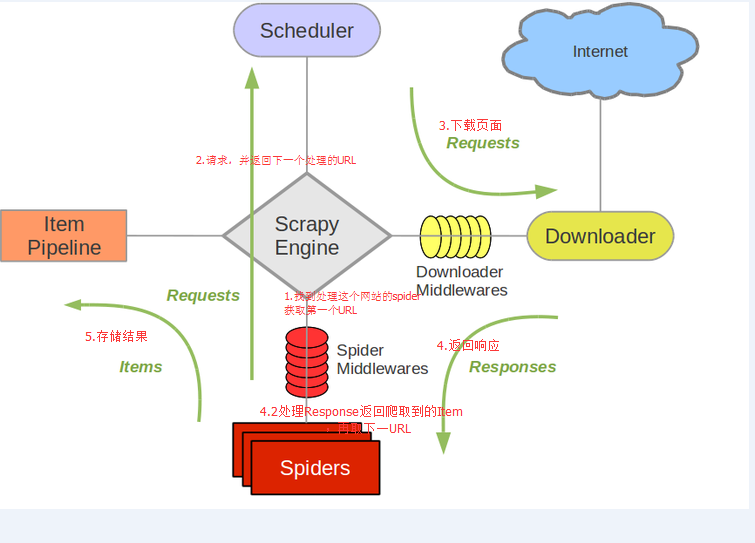
组件
Scrapy Engine
引擎负责控制数据流。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
二、Scrapy环境配置
安装以下程序
- Python 2.7
- Python Package: pip and setuptools. 现在 pip 依赖 setuptools ,如果未安装,则会自动安装setuptools 。
- lxml. 大多数Linux发行版自带了lxml。如果缺失,请查看http://lxml.de/installation.html
- OpenSSL. 除了Windows(请查看 平台安装指南)之外的系统都已经提供。
pip install pyopenssl
- Visual C++2008
- 安装PyWin32
- pip install scrapy
创建工程模板
命令行执行:scrapy startproject 工程名
创建好的工程结构如下图:

Idea中配置scrapy启动

二、常用API说明
开发中主要涉及spider,item,Pipeline,settings模块的开发。需要扩展插件则开发extions模块。
Spider类
继承scrapy.Spider类
属性
name : 爬虫名字,用于区别spider,唯一。
start_urls : Spider在启动时进行爬取的url列表。后续的URL则从初始的URL获取到的数据中提取。
方法
parse(self, response) :每个初始url爬取到的数据将通过response参数传递过来。此方法负责解析数据(response), 提取数据(生成Item),生成需要进一步处理的URL请求(request)。
scrapy.Request(url=link, errback=self.errback_http, callback=self.parse_article)
框架会对url=link的地址发起请求,如果请求出现错误执行用户自定义的errback_http方法,如果请求成功则执行用户自定义的parse_article方法。
Item类
需要继承scrapy.Item。Item是一个dict(),用于存储spider中parse()中解析到的数据,在pipeline中调用。
import scrapy class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
Scrapy Selector基于xpath和css提取元素。
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
运行爬虫
在项目目录下运行以下命令,即可执行爬虫:
scrapy crawl NAME(爬虫名字)
配置文件Settings
Settings文件可以可以控制包括核心(core),插件(extension),pipeline及spider组件。这里只说3.settings模块。
- 命令行选项(Command line Options)(最高优先级)
- 每个spider的设定
- 项目设定模块(Project settings module)
- 命令默认设定模块(Default settings per-command)
- 全局默认设定(Default global settings) (最低优先级)
访问settings
如果需要使用该配置文件中定义的属性,类(爬虫,管道,插件)需要增加额外的类方法: from_crawler(cls, crawler)。
设定可以通过Crawler的 scrapy.crawler.Crawler.settings 属性进行访问。其由插件及中间件的from_crawler 方法所传入:
class MyExtension(object):
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
if settings['LOG_ENABLED']:
print "log is enabled!"
也可以通过字典访问,避免错误,建议使用setting API中的规范key值。
管道开发
管道类似过滤处理链,根据自定义业务依次处理Spider解析后的数据,例如数据验证(去重、转换),计算存储(DB,NOSQL),发送消息(Kafka,MQ),报表生成。
开发自定义管道类需要两步骤:
- 在pipelines中定义类并实现 process_item(self, item, spider) 方法, 其中item对象为spider解析后待处理的数据。
- 在settings中开启管道配置信息,ITEM_PIPELINES 中配置自定义管道类名和执行序列。
说明
自定义管道根据序列号从小到大依次执行请求,如果抛出DropItem异常,后续管道将不会执行,例如数据出现重复主键,可以抛出DropItem异常。
日志开发
使用以下代码在管道中定义日志名称
logger = logging.getLogger('pipelogger')
同时可以在包初始化文件__init__.py中定义日志级别 : LOG_LEVEL = 'INFO'
日志启用也可以在settings中设置如下属性
LOG_ENABLED = True #启用日志
LOG_ENCODING = 'utf-8' #设置日志字符集
LOG_FILE = 'e://workspace/log/csdncrawl.log' #指定日志文件及路径
LOG_LEVEL = 'INFO' #定义日志级别
LOG_STDOUT = True #是否将print语句打印内容输出到日志
扩展插件
开发者可自定义运行在不同阶段的插件,例如打开爬虫、关闭爬虫、数据抓取等。
插件只需要关注:在什么时候做什么事情,即 状态-方法。
开发插件只需要2步:
- 开发插件类,可定义在extensions.py文件中,在from_crawler中增加状态-方法的映射关系,例如在打开爬虫的时候执行spider_opened方法可这样配置:
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
- 在settings中配置插件类,和管道定义类似, 其KEY为EXTENSIONS
四、代码示例
Spider示例
import scrapy class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
] def parse(self, response):
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
日志Logging
import logginglogger = logging.getLogger('mycustomlogger')
logger.warning("This is a warning")
import logging
import scrapy
logger = logging.getLogger('mycustomlogger')
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://scrapinghub.com']
def parse(self, response):
logger.info('Parse function called on %s', response.url)
参考资料:
中文版scrapy资料地址:https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html
Scrapy开发指南的更多相关文章
- ASP.NET Aries 开源开发框架:开发指南(一)
前言: 上周开源了Aries开发框架后,好多朋友都Download了源码,在运行过程里,有一些共性的问题会问到. 所以本篇打算写一下简单的开发指南,照顾一下不是太看的懂源码的同学,同时也会讲解一下框架 ...
- FreeMarker模板开发指南知识点梳理
freemarker是什么? 有什么用? 怎么用? (问得好,这些都是我想知道的问题) freemarker是什么? FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生 ...
- Jetty使用教程(四:21-22)—Jetty开发指南
二十一.嵌入式开发 21.1 Jetty嵌入式开发HelloWorld 本章节将提供一些教程,通过Jetty API快速开发嵌入式代码 21.1.1 下载Jetty的jar包 Jetty目前已经把所有 ...
- JVM 平台上的各种语言的开发指南
JVM 平台上的各种语言的开发指南 为什么我们需要如此多的JVM语言? 在2013年你可以有50中JVM语言的选择来用于你的下一个项目.尽管你可以说出一大打的名字,你会准备为你的下一个项目选择一种新的 ...
- iOS原生地图开发指南续——大头针与自定义标注
iOS原生地图开发指南续——大头针与自定义标注 出自:http://www.sxt.cn/info-6042-u-7372.html 在上一篇博客中http://my.oschina.net/u/23 ...
- Angularjs中文版本开发指南发布
从本人开始在写关于Angularjs的文章开始,也算是见证了Angularjs在国内慢慢的火起来,如今的Angularjs正式如日中天.想知道为什么Angularjs会这么火,请移步angularjs ...
- nodejs开发指南读后感
nodejs开发指南读后感 阅读目录 使用nodejs创建http服务器; supervisor的使用及nodejs常见的调式代码命令了解; 了解Node核心模块; ejs模板引擎 Express 理 ...
- Libgdx 开发指南——目录
本系列文档选译自libgdx github项目 wiki : https://github.com/libgdx/libgdx/wiki 由于关于Libgdx的中文文档非常稀缺,因此在这里对官方Wik ...
- jQuery MiniUI 开发指南+API组件参考手册
jQuery MiniUI 开发指南 本文档将逐步的讲解jQuery MiniUI的方方面面,从此您将踏上jQuery MiniUI的深入探索之旅. 1.Hello M ...
随机推荐
- 那些年【深入.NET平台和C#编程】
一.深入.NET框架 1..NET框架具有两个组件:CLR(公共语言运行时)和FCL(框架类库),CLR是.NET框架的基础 2.框架核心类库: System.Collections.Generic: ...
- 从阿里巴巴笔试题看Java加载顺序
一.阿里巴巴笔试题: public class T implements Cloneable { public static int k = 0; public static T t1 = new T ...
- C# 工厂模式+虚方法(接口、抽象方法)实现多态
面向对象语言的三大特征之一就是多态,听起来多态比较抽象,简而言之就是同一行为针对不同对象得到不同的结果,同一对象,在不同的环境下得到不同的状态. 实例说明: 业务需求:实现一个打开文件的控制台程序的d ...
- Maven(一)linux下安装
1.检查是否安装JDK,并且设置了环境变量(JAVA_HOME): echo $JAVA_HOME java -version 运行结果: 显示jdk的安装路径,和java的版本,如: #jdk路径 ...
- 自建git node pm2 (不赘述,就说遇见的问题)
//======================[git]部分 主题部分还是按照网上的办法进行安装. 安装的话 分为两个办法(一个是yum (contos办法) 或者sudo(ubuntu办法) ...
- FineReport如何部署Tomcat服务器集群
环境准备 Tomcat服务器集群中需要进行环境准备: Apache:Apache是http服务器,利用其对Tomcat进行负载均衡,这里使用的版本是Apache HTTP Server2.0.64: ...
- 归并排序的java实现
归并排序的优点不说了. 做归并排序之前,我先试着将两个有序数组进行排序,合并成一个有序数组. 思路:定义好两个有序数组,理解的时候我先思考了数组只有一个数组的排序,然后是两个元素的数组的排序,思路就有 ...
- 机器指令翻译成 JavaScript —— No.5 指令变化
上一篇,我们通过内置解释器的方案,解决任意跳转的问题.同时,也提到另一个问题:如果指令发生变化,又该如何应对. 指令自改 如果指令加载到 RAM 中,那就和普通数据一样,也是可以随意修改的.然而,对应 ...
- 需要UWP Vendor一名
工作地点北京,海淀,微软大厦2号楼,小冰项目组.
- Leetcode 笔记 101 - Symmetric Tree
题目链接:Symmetric Tree | LeetCode OJ Given a binary tree, check whether it is a mirror of itself (ie, s ...