机器学习(4):BP神经网络原理及其python实现
BP神经网络是深度学习的重要基础,它是深度学习的重要前行算法之一,因此理解BP神经网络原理以及实现技巧非常有必要。接下来,我们对原理和实现展开讨论。
1.原理
有空再慢慢补上,请先参考老外一篇不错的文章:A Step by Step Backpropagation Example
激活函数参考:深度学习常用激活函数之— Sigmoid & ReLU & Softmax
浅显易懂的初始化:CS231n课程笔记翻译:神经网络笔记 2
有效的Trick:神经网络训练中的Tricks之高效BP(反向传播算法)
通过简单演示BPNN的计算过程:一文弄懂神经网络中的反向传播法——BackPropagation
2.实现----Batch随机梯度法
这里实现了层数可定义的BP神经网络,可通过参数net_struct进行定义网络结果,如定义只有输出层,没有隐藏层的网络结构,激活函数为”sigmoid",学习率,可如下定义
net_struct = [[10,"sigmoid",0.01]] # 网络结构
如定义一层隐藏层为100个神经元,再接一层隐藏层为50个神经元,输出层为10个神经元的网络结构,如下
net_struct = [[100,"sigmoid",0.01],[50,"sigmoid",0.01],[10,"sigmoid",0.01]] # 网络结构
码农最爱的实现如下:
# # encoding=utf8
'''
Created on 2017-7-3 @author: Administrator
'''
import random
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split as ttsplit class LossFun:
def __init__(self, lf_type="least_square"):
self.name = "loss function"
self.type = lf_type def cal(self, t, z):
loss = 0
if self.type == "least_square":
loss = self.least_square(t, z)
return loss def cal_deriv(self, t, z):
delta = 0
if self.type == "least_square":
delta = self.least_square_deriv(t, z)
return delta def least_square(self, t, z):
zsize = z.shape
sample_num = zsize[1]
return np.sum(0.5 * (t - z) * (t - z) * t) / sample_num def least_square_deriv(self, t, z):
return z - t class ActivationFun:
'''
激活函数
'''
def __init__(self, atype="sigmoid"):
self.name = "activation function library"
self.type = atype; def cal(self, a):
z = 0
if self.type == "sigmoid":
z = self.sigmoid(a)
elif self.type == "relu":
z = self.relu(a)
return z def cal_deriv(self, a):
z = 0
if self.type == "sigmoid":
z = self.sigmoid_deriv(a)
elif self.type == "relu":
z = self.relu_deriv(a)
return z def sigmoid(self, a):
return 1 / (1 + np.exp(-a)) def sigmoid_deriv(self, a):
fa = self.sigmoid(a)
return fa * (1 - fa) def relu(self, a):
idx = a <= 0
a[idx] = 0.1 * a[idx]
return a # np.maximum(a, 0.0) def relu_deriv(self, a):
# print a
a[a > 0] = 1.0
a[a <= 0] = 0.1
# print a
return a class Layer:
'''
神经网络层
'''
def __init__(self, num_neural, af_type="sigmoid", learn_rate=0.5):
self.af_type = af_type # active function type
self.learn_rate = learn_rate
self.num_neural = num_neural
self.dim = None
self.W = None self.a = None
self.X = None
self.z = None
self.delta = None
self.theta = None
self.act_fun = ActivationFun(self.af_type) def fp(self, X):
'''
Foward Propagation
'''
self.X = X
xsize = X.shape
self.dim = xsize[0]
self.num = xsize[1] if self.W == None:
# self.W = np.random.random((self.dim, self.num_neural))-0.5
# self.W = np.random.uniform(-1,1,size=(self.dim,self.num_neural))
if(self.af_type == "sigmoid"):
self.W = np.random.normal(0, 1, size=(self.dim, self.num_neural)) / np.sqrt(self.num)
elif(self.af_type == "relu"):
self.W = np.random.normal(0, 1, size=(self.dim, self.num_neural)) * np.sqrt(2.0 / self.num)
if self.theta == None:
# self.theta = np.random.random((self.num_neural, 1))-0.5
# self.theta = np.random.uniform(-1,1,size=(self.num_neural,1)) if(self.af_type == "sigmoid"):
self.theta = np.random.normal(0, 1, size=(self.num_neural, 1)) / np.sqrt(self.num)
elif(self.af_type == "relu"):
self.theta = np.random.normal(0, 1, size=(self.num_neural, 1)) * np.sqrt(2.0 / self.num)
# calculate the foreward a
self.a = (self.W.T).dot(self.X)
###calculate the foreward z####
self.z = self.act_fun.cal(self.a)
return self.z def bp(self, delta):
'''
Back Propagation
'''
self.delta = delta * self.act_fun.cal_deriv(self.a)
self.theta = np.array([np.mean(self.theta - self.learn_rate * self.delta, 1)]).T # 求所有样本的theta均值
dW = self.X.dot(self.delta.T) / self.num
self.W = self.W - self.learn_rate * dW
delta_out = self.W.dot(self.delta);
return delta_out class BpNet:
'''
BP神经网络
'''
def __init__(self, net_struct, stop_crit, max_iter, batch_size=10):
self.name = "net work"
self.net_struct = net_struct
if len(self.net_struct) == 0:
print "no layer is specified!"
return self.stop_crit = stop_crit
self.max_iter = max_iter
self.batch_size = batch_size
self.layers = []
self.num_layers = 0;
# 创建网络
self.create_net(net_struct)
self.loss_fun = LossFun("least_square"); def create_net(self, net_struct):
'''
创建网络
'''
self.num_layers = len(net_struct)
for i in range(self.num_layers):
self.layers.append(Layer(net_struct[i][0], net_struct[i][1], net_struct[i][2])) def train(self, X, t, Xtest=None, ttest=None):
'''
训练网络
'''
eva_acc_list = []
eva_loss_list = [] xshape = X.shape;
num = xshape[0]
dim = xshape[1] for k in range(self.max_iter):
# i = random.randint(0,num-1)
idxs = random.sample(range(num), self.batch_size)
xi = np.array([X[idxs, :]]).T[:, :, 0]
ti = np.array([t[idxs, :]]).T[:, :, 0]
# 前向计算
zi = self.fp(xi) # 偏差计算
delta_i = self.loss_fun.cal_deriv(ti, zi) # 反馈计算
self.bp(delta_i) # 评估精度
if Xtest != None:
if k % 100 == 0:
[eva_acc, eva_loss] = self.test(Xtest, ttest)
eva_acc_list.append(eva_acc)
eva_loss_list.append(eva_loss)
print "%4d,%4f,%4f" % (k, eva_acc, eva_loss)
else:
print "%4d" % (k)
return [eva_acc_list, eva_loss_list] def test(self, X, t):
'''
测试模型精度
'''
xshape = X.shape;
num = xshape[0]
z = self.fp_eval(X.T)
t = t.T
est_pos = np.argmax(z, 0)
real_pos = np.argmax(t, 0)
corrct_count = np.sum(est_pos == real_pos)
acc = 1.0 * corrct_count / num
loss = self.loss_fun.cal(t, z)
# print "%4f,loss:%4f"%(loss)
return [acc, loss] def fp(self, X):
'''
前向计算
'''
z = X
for i in range(self.num_layers):
z = self.layers[i].fp(z)
return z def bp(self, delta):
'''
反馈计算
'''
z = delta
for i in range(self.num_layers - 1, -1, -1):
z = self.layers[i].bp(z)
return z def fp_eval(self, X):
'''
前向计算
'''
layers = self.layers
z = X
for i in range(self.num_layers):
z = layers[i].fp(z)
return z def z_score_normalization(x):
mu = np.mean(x)
sigma = np.std(x)
x = (x - mu) / sigma;
return x; def sigmoid(X, useStatus):
if useStatus:
return 1.0 / (1 + np.exp(-float(X)));
else:
return float(X); def plot_curve(data, title, lege, xlabel, ylabel):
num = len(data)
idx = range(num)
plt.plot(idx, data, color="r", linewidth=1) plt.xlabel(xlabel, fontsize="xx-large")
plt.ylabel(ylabel, fontsize="xx-large")
plt.title(title, fontsize="xx-large")
plt.legend([lege], fontsize="xx-large", loc='upper left');
plt.show() if __name__ == "__main__":
print ('This is main of module "bp_nn.py"') print("Import data")
raw_data = pd.read_csv('./train.csv', header=0)
data = raw_data.values
imgs = data[0::, 1::]
labels = data[::, 0]
train_features, test_features, train_labels, test_labels = ttsplit(
imgs, labels, test_size=0.33, random_state=23323) train_features = z_score_normalization(train_features)
test_features = z_score_normalization(test_features)
sample_num = train_labels.shape[0]
tr_labels = np.zeros([sample_num, 10])
for i in range(sample_num):
tr_labels[i][train_labels[i]] = 1 sample_num = test_labels.shape[0]
te_labels = np.zeros([sample_num, 10])
for i in range(sample_num):
te_labels[i][test_labels[i]] = 1 print train_features.shape
print tr_labels.shape
print test_features.shape
print te_labels.shape stop_crit = 100 # 停止
max_iter = 10000 # 最大迭代次数
batch_size = 100 # 每次训练的样本个数
net_struct = [[100, "relu", 0.01], [10, "sigmoid", 0.1]] # 网络结构[[batch_size,active function, learning rate]]
# net_struct = [[200,"sigmoid",0.5],[100,"sigmoid",0.5],[10,"sigmoid",0.5]] 网络结构[[batch_size,active function, learning rate]] bpNNCls = BpNet(net_struct, stop_crit, max_iter, batch_size);
# train model [acc, loss] = bpNNCls.train(train_features, tr_labels, test_features, te_labels)
# [acc, loss] = bpNNCls.train(train_features, tr_labels)
print("training model finished")
# create test data
plot_curve(acc, "Bp Network Accuracy", "accuracy", "iter", "Accuracy")
plot_curve(loss, "Bp Network Loss", "loss", "iter", "Loss") # test model
[acc, loss] = bpNNCls.test(test_features, te_labels);
print "test accuracy:%f" % (acc)
实验数据为mnist数据集合,可从以下地址下载:https://github.com/WenDesi/lihang_book_algorithm/blob/master/data/train.csv
a.使用sigmoid激活函数和net_struct = [10,"sigmoid"]的网络结构(可看作是softmax 回归),其校验精度和损失函数的变化,如下图所示:
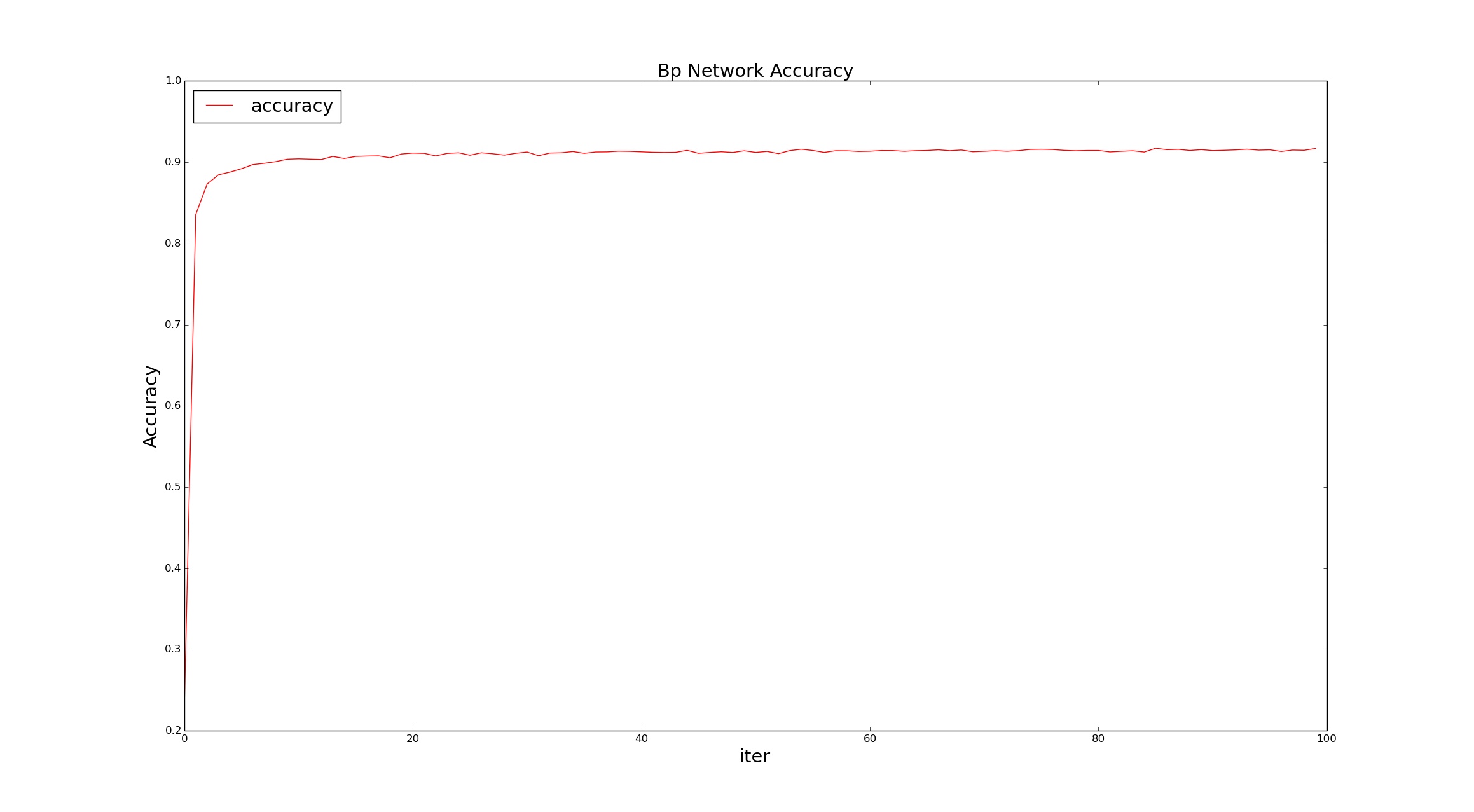

测试精度达到0.916017,效果还是不错的。但是随机梯度法,依赖于参数的初始化,如果初始化不好,会收敛缓慢,甚至有不理想的结果。
b.使用sigmoid激活函数和net_struct = [200,"sigmoid",100,"sigmoid",10,"sigmoid"] 的网络结构(一个200的隐藏层,一个100的隐藏层,和一个10的输出层),其校验精度和损失函数的变化,如下图所示:
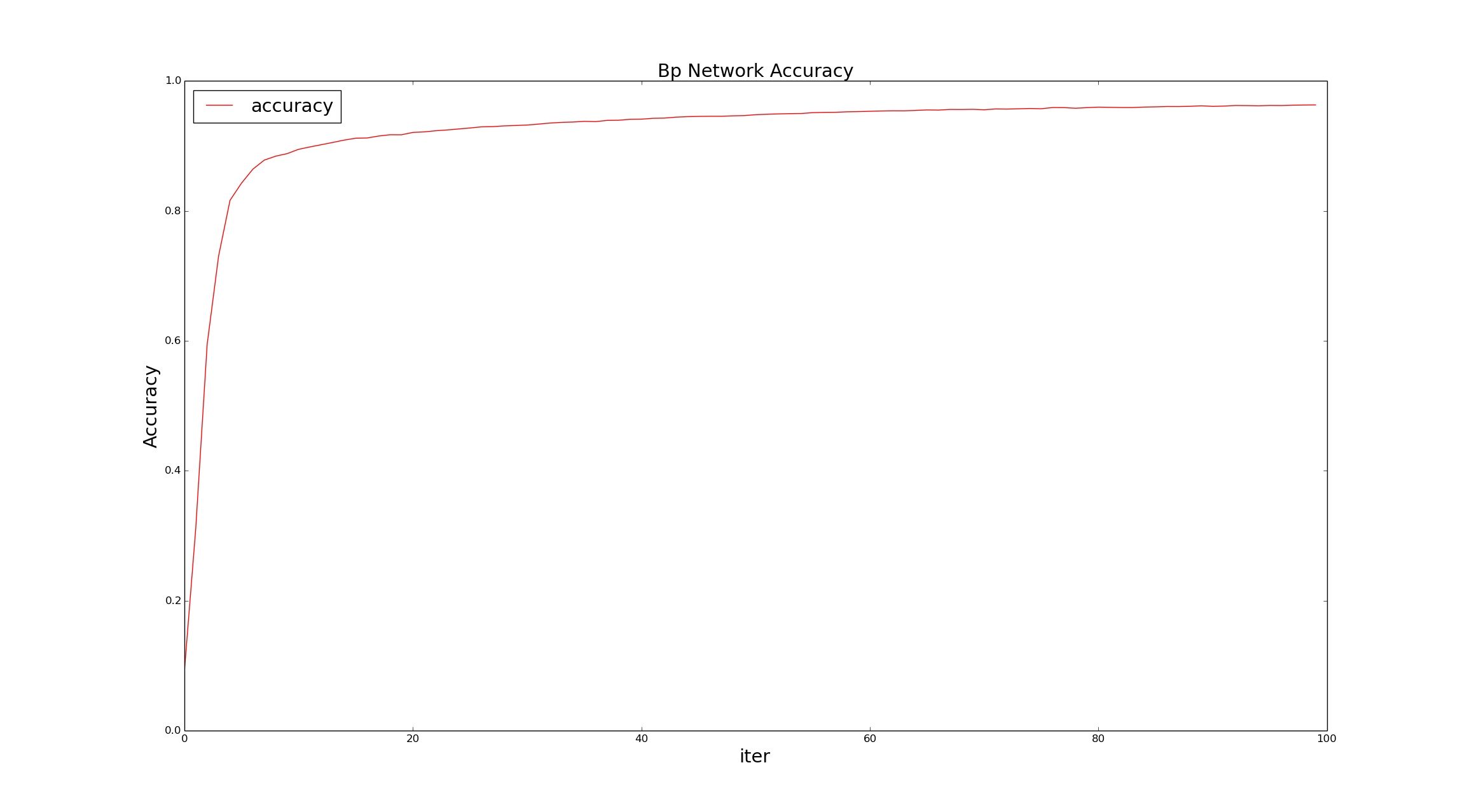

其校验精度达到0.963636,比softmax要好不少。从损失曲线可以看出,加入隐藏层后,算法收敛要比无隐藏层的稳定。
机器学习(4):BP神经网络原理及其python实现的更多相关文章
- BP神经网络原理及python实现
[废话外传]:终于要讲神经网络了,这个让我踏进机器学习大门,让我读研,改变我人生命运的四个字!话说那么一天,我在乱点百度,看到了这样的内容: 看到这么高大上,这么牛逼的定义,怎么能不让我这个技术宅男心 ...
- 机器学习入门学习笔记:(一)BP神经网络原理推导及程序实现
机器学习中,神经网络算法可以说是当下使用的最广泛的算法.神经网络的结构模仿自生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它“兴奋”时,想下一级相连的神经元发送化学物质,改变这些神经元的 ...
- 菜鸟之路——机器学习之BP神经网络个人理解及Python实现
关键词: 输入层(Input layer).隐藏层(Hidden layer).输出层(Output layer) 理论上如果有足够多的隐藏层和足够大的训练集,神经网络可以模拟出任何方程.隐藏层多的时 ...
- 【机器学习】BP神经网络实现手写数字识别
最近用python写了一个实现手写数字识别的BP神经网络,BP的推导到处都是,但是一动手才知道,会理论推导跟实现它是两回事.关于BP神经网络的实现网上有一些代码,可惜或多或少都有各种问题,在下手写了一 ...
- deep learning(1)BP神经网络原理与练习
具体原理参考如下讲义: 1.神经网络 2.反向传导 3.梯度检验与高级优化 看完材料1和2就可以梳理清楚bp神经网络的基本工作原理,下面通过一个C语言实现的程序来练习这个算法 //Backpropag ...
- BP神经网络原理详解
转自博客园@编程De: http://www.cnblogs.com/jzhlin/archive/2012/07/28/bp.html http://blog.sina.com.cn/s/blog ...
- BP神经网络原理及在Matlab中的应用
一.人工神经网络 关于对神经网络的介绍和应用,请看如下文章 神经网络潜讲 如何简单形象又有趣地讲解神经网络是什么 二.人工神经网络分类 按照连接方式--前向神经网络.反馈(递归)神经网络 按照 ...
- bp神经网络原理
bp(back propagation)修改每层神经网络向下一层传播的权值,来减少输出层的实际值和理论值的误差 其实就是训练权值嘛 训练方法为梯度下降法 其实就是高等数学中的梯度,将所有的权值看成自变 ...
- 机器学习之BP神经网络
import random import math #神经元的定义 class Neuron: def __init__(self,bias): self.bias = bias self.weigh ...
随机推荐
- redhat6.5文件共享
以下操作均需要root用户 a端: 固定nfs端口 #vi /etc/sysconfig/nfs 将里面的RQUOTAD_PORT.LOCKD_TCPPORT.LOCKD_UDPPORT.MOUNTD ...
- Redis相关链接
Redis 教程 http://www.runoob.com/redis/redis-data-types.html Python操作redis学习系列之(集合)set,redis set详解 (六) ...
- python网络编程-同步IO和异步IO,阻塞IO和非阻塞IO
同步IO和异步IO,阻塞IO和非阻塞IO分别是什么,到底有什么区别?不同的人在不同的上下文下给出的答案是不同的.所以先限定一下本文的上下文. 本文讨论的背景是Linux环境下的network IO. ...
- 关于move
procedure TForm4.Button1Click(Sender: TObject); var //动态数组 bytes1,bytes2: TBytes; //静态数组 bytes3,byte ...
- 关于在调用JAVAFX相关包时遇到Access restriction: The type 'Application' is not API (restriction on required library)的解决方法
点击工具栏的Project->Properties->Java Build Path->Libraries-> 双击第一项 点击Add添加允许javafx 然后就不会报错了
- SQLServer系统变量使用
1.@@IDENTITY返回最后插入的标识值.这个变量很有用,当你插入一行数据时,想同时获得该行的的ID(标示列),就可以用@@IDENTITY示例:下面的示例向带有标识列的表中插入一行,并用 @@I ...
- hdu 4813(2013长春现场赛A题)
把一个字符串分成N个字符串 每个字符串长度为m Sample Input12 5 // n mklmbbileay Sample Outputklmbbileay # include <iost ...
- Asp.net Vnext 调试源码
概述 本文已经同步到<Asp.net Vnext 系列教程 >中] 如果想对 vnext深入了解,就目前为止太该只有调试源码了 实现 github上下载源码 选择对应的版本,版本错了是不行 ...
- 用 Java 实现一个快速排序算法
快速排序是排序算法中效率最高的一种,它是利用递归的原理,把数组无限制的分成两个部分,直到所有数据都排好序为止. 快速排序是对冒泡排序的一种改进.它的基本思想是通过一趟排序将要排序的数据分 ...
- web中的相对路径与绝对路径
1.什么叫绝对路径 相对于WEB应用的跟路径的路径,即任何路径都必须带上contentPath. 2.javaEE中的/代表什么 代表WEB应用的跟路径(需交由Servlet容器处理) 请求转发时. ...