FAQ 关于allure和pycharm的运行模式
关于allure和pycharm的运行模式
案例
新建一个项目allure_mode
新建一个python代码test_allure_001.py
代码如下
import pytest, os def test_001():
assert 1 == 1 if __name__ == '__main__':
pytest.main(['-sv', __file__, '--alluredir', './html', '--clean-alluredir'])
os.system(f'allure serve ./html')右键运行(注意样式)
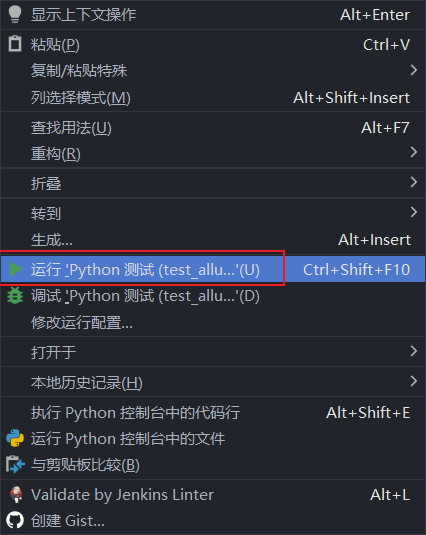
- 运行结果:注意底部右侧的测试结果区域
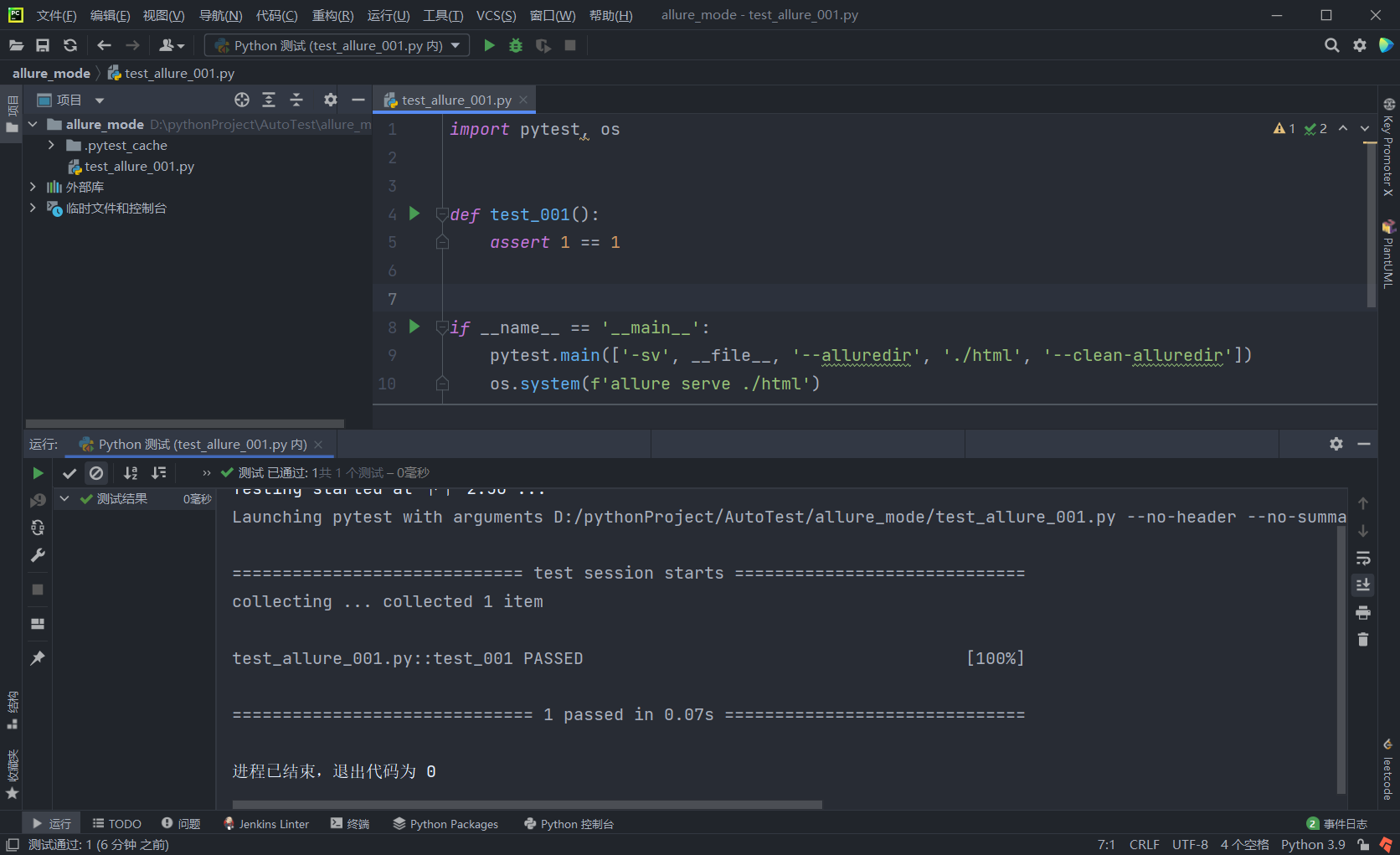
- 用例看着没问题,但问题来了。
- pytest.main那一行的作用是测试该代码(好像测了),--alluredir参数的意思是会生成一个allure报告所需的json到当前目录下的html文件夹下,然后清空上次的内容。现在看很奇怪的是执行了部分?压根就没有生成allure报告所需的内容
- os.system这一行的作用是打开html目录中的文件,生成一个allure的报告(启动一个web 服务器)。压根就没做。
测试
在pytest.main之前加一句打印
...
if __name__ == '__main__':
print('发生了什么')
pytest.main..
os.system
结果是:print也不会打印
证明了:if这个判断似乎就不成立?
跟我们以前学的python基础略有冲突,因为我们当前文件的__name__就是等于__main__的
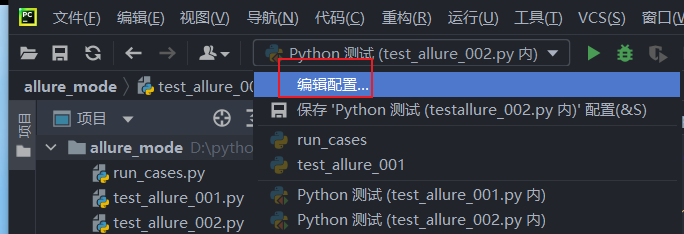
你认识的没有问题,一切都是因为现在的这个模式,第一张图。你现在是pytest在运行你的测试用例,它并不会关心if这个判断下的内容(为啥?不知道了。)
所以我们都会让你修改模式
修改pycharm的运行模式
- 文件->设置->工具->Python 集成工具-> 测试- > 默认测试运行程序:改为unittest(注意自动检测是pytest的)
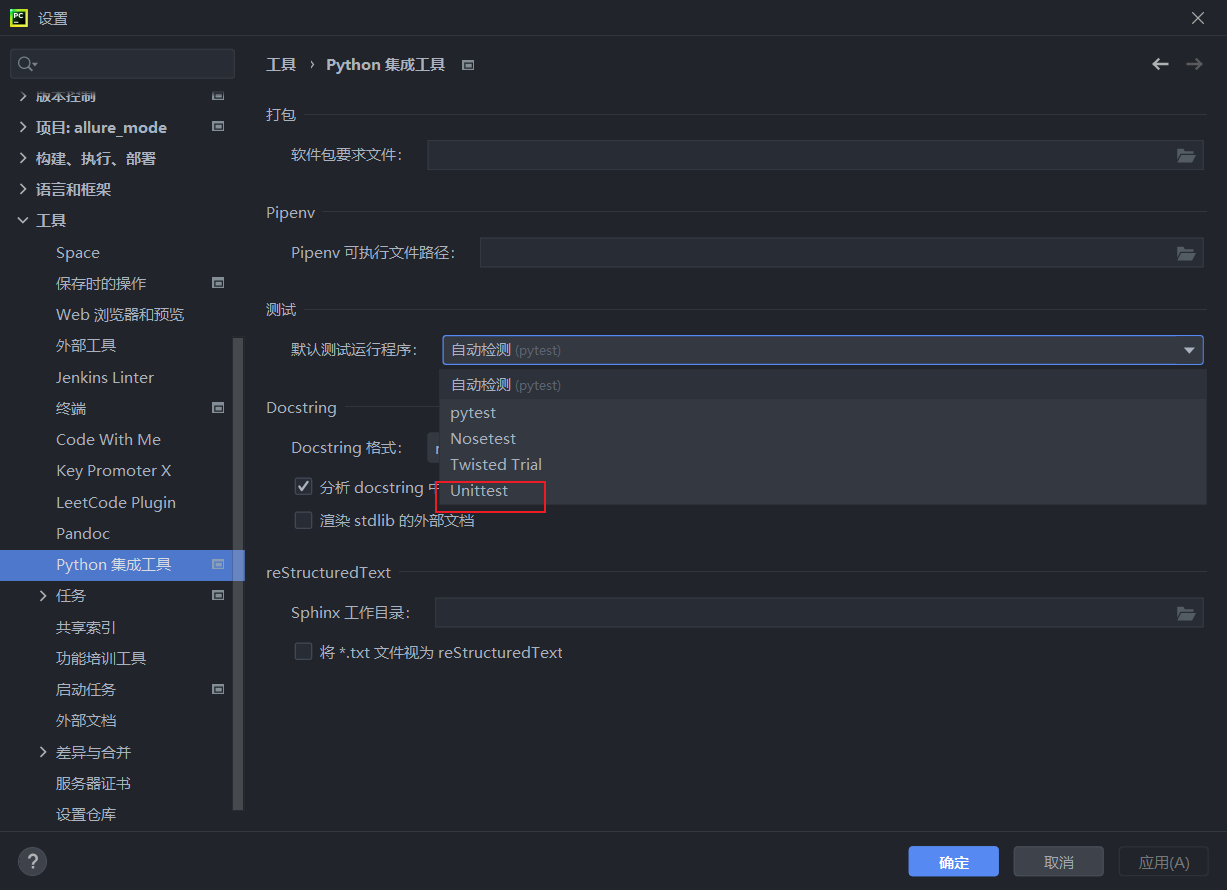
- 注意此时的右键运行菜单
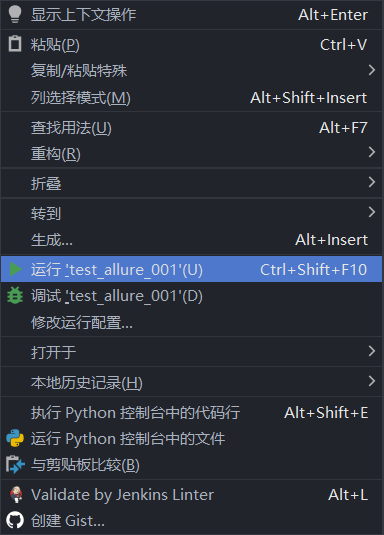
运行效果:注意左侧的测试结果没有了(上图2,所以如果我看到图2的内容,我就知道你的模式并不对)
D:\Python39\python.exe D:/pythonProject/AutoTest/allure_mode/test_allure_001.py
发生了什么
============================= test session starts =============================
platform win32 -- Python 3.9.6, pytest-7.1.2, pluggy-1.0.0 -- D:\Python39\python.exe
cachedir: .pytest_cache
metadata: {'Python': '3.9.6', 'Platform': 'Windows-10-10.0.19044-SP0', 'Packages': {'pytest': '7.1.2', 'py': '1.11.0', 'pluggy': '1.0.0'}, 'Plugins': {'allure-pytest': '2.9.45', 'anyio': '3.5.0', 'Faker': '13.3.4', 'assume': '2.4.3', 'base-url': '1.4.2', 'dependency': '0.5.1', 'forked': '1.4.0', 'html': '3.1.1', 'instafail': '0.4.2', 'metadata': '1.11.0', 'ordering': '0.6', 'repeat': '0.9.1', 'rerunfailures': '10.2', 'sugar': '0.9.4', 'timeout': '2.1.0', 'xdist': '2.5.0'}, 'JAVA_HOME': 'D:\\Java\\jdk1.8.0_301\\', 'Base URL': ''}
rootdir: D:\pythonProject\AutoTest\allure_mode
plugins: allure-pytest-2.9.45, anyio-3.5.0, Faker-13.3.4, assume-2.4.3, base-url-1.4.2, dependency-0.5.1, forked-1.4.0, html-3.1.1, instafail-0.4.2, metadata-1.11.0, ordering-0.6, repeat-0.9.1, rerunfailures-10.2, sugar-0.9.4, timeout-2.1.0, xdist-2.5.0
collecting ... collected 1 item test_allure_001.py::test_001 PASSED ============================== 1 passed in 0.06s ==============================
Generating report to temp directory...
Report successfully generated to C:\Users\SONGQI~1\AppData\Local\Temp\6816591429229290427\allure-report
Starting web server...
2022-08-23 15:17:07.287:INFO::main: Logging initialized @1991ms to org.eclipse.jetty.util.log.StdErrLog
Server started at <http://192.168.10.147:2587/>. Press <Ctrl+C> to exit输出了print的内容
当前目录下也有了html目录,及里面的内容
- 报告也自动打开了
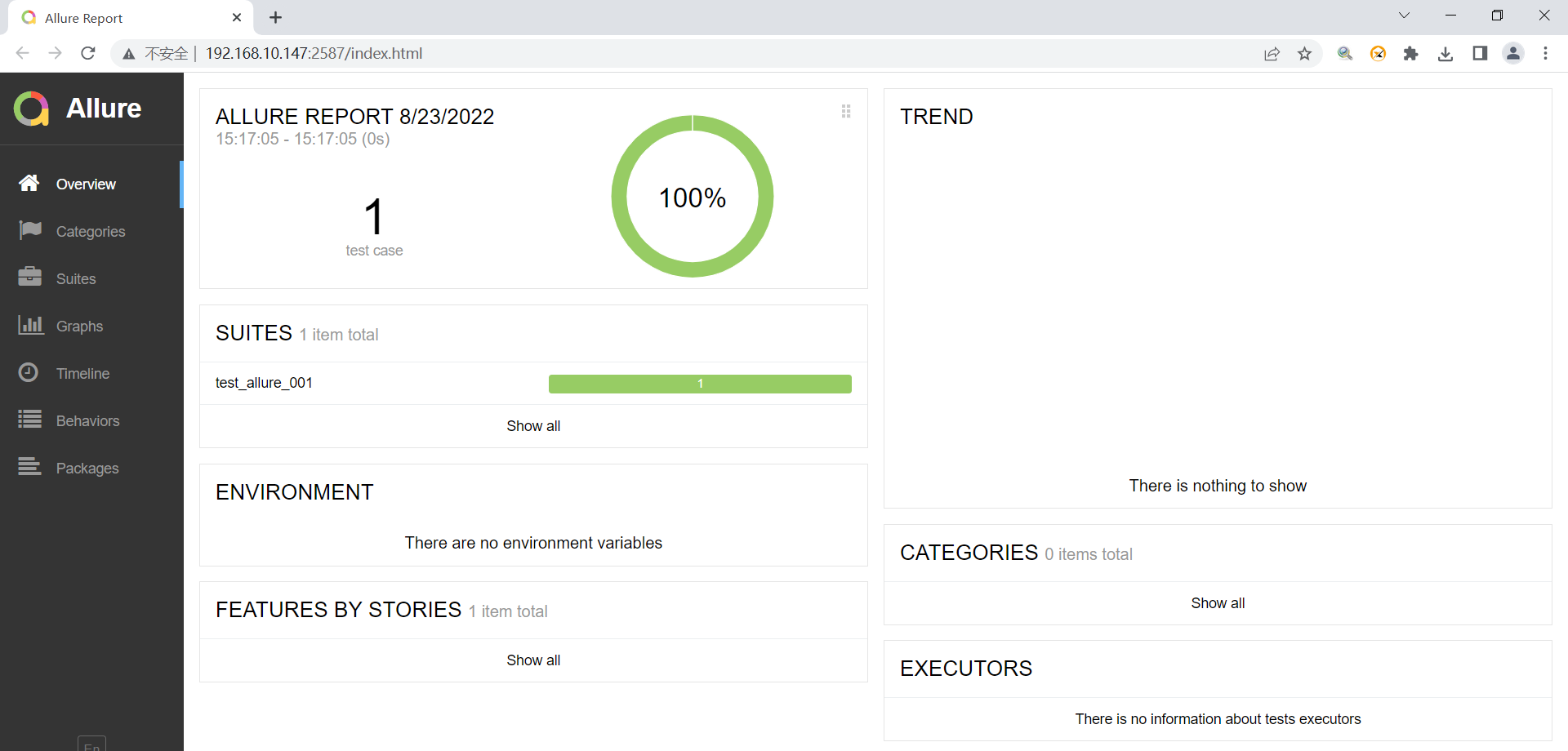
- 结论:当时unittest模式的情况下,if下面的语句能正常执行,不会被抛弃,所以都生效了(print语句,pytest.main,os.system等)
还没完
是的,上面似乎已经解决了你的问题。但pycharm会这么low吗?默认检测的不对?而且如果是新建的项目,你可能还要再次设置。
你可以做以下测试
- 删除新生成的html目录
- 把if语句及其下面的都去掉
- 模式改回pytest
- 复制一个001为002
像这样:很简单
编写一个run_cases.py,命名并无要求,意思就是运行所有的case
import pytest
import os pytest.main(['-sv', '--alluredir', './html', '--clean-alluredir'])
os.system(f'allure serve ./html')
- 注意去掉了__file__
- 没有if main啥的了
注意右键菜单
执行效果:很好,就是pytest,allure报告也生成了,就不截图了
D:\Python39\python.exe D:/pythonProject/AutoTest/allure_mode/run_cases.py
============================= test session starts =============================
platform win32 -- Python 3.9.6, pytest-7.1.2, pluggy-1.0.0 -- D:\Python39\python.exe
cachedir: .pytest_cache
metadata: {'Python': '3.9.6', 'Platform': 'Windows-10-10.0.19044-SP0', 'Packages': {'pytest': '7.1.2', 'py': '1.11.0', 'pluggy': '1.0.0'}, 'Plugins': {'allure-pytest': '2.9.45', 'anyio': '3.5.0', 'Faker': '13.3.4', 'assume': '2.4.3', 'base-url': '1.4.2', 'dependency': '0.5.1', 'forked': '1.4.0', 'html': '3.1.1', 'instafail': '0.4.2', 'metadata': '1.11.0', 'ordering': '0.6', 'repeat': '0.9.1', 'rerunfailures': '10.2', 'sugar': '0.9.4', 'timeout': '2.1.0', 'xdist': '2.5.0'}, 'JAVA_HOME': 'D:\\Java\\jdk1.8.0_301\\', 'Base URL': ''}
rootdir: D:\pythonProject\AutoTest\allure_mode
plugins: allure-pytest-2.9.45, anyio-3.5.0, Faker-13.3.4, assume-2.4.3, base-url-1.4.2, dependency-0.5.1, forked-1.4.0, html-3.1.1, instafail-0.4.2, metadata-1.11.0, ordering-0.6, repeat-0.9.1, rerunfailures-10.2, sugar-0.9.4, timeout-2.1.0, xdist-2.5.0
collecting ... collected 2 items test_allure_001.py::test_001 PASSED
test_allure_002.py::test_002 PASSED ============================== 2 passed in 0.06s ==============================
Generating report to temp directory...
Report successfully generated to C:\Users\SONGQI~1\AppData\Local\Temp\2213206012790709893\allure-report
Starting web server...
2022-08-23 15:29:58.558:INFO::main: Logging initialized @3280ms to org.eclipse.jetty.util.log.StdErrLog
Server started at <http://192.168.10.147:4502/>. Press <Ctrl+C> to exit多数情况下你测试你的cases的时候并不会去写if main,那是调试一个case的一种方式,你要批量运行的,所以pycharm的模式并没有问题。
我偏要测试一个文件,还要用pytest模式,可以吗?
真倔哎(自说自话)
答案:当然是可以!这本来就是可以的。
前面我们已经证明了,if语句下的在pytest模式下并不会运行,改为unittest模式可以了。
那就不要if!
import pytest,os
def test_001():
assert 1 == 1 pytest.main(['-sv', __file__,'--alluredir', './html', '--clean-alluredir'])
os.system(f'allure serve ./html')执行的话也能看到报告
但是!你不可能就一个case的,你如果要多用例一起调用,这个case里面的这2行(pytest.main和os.system)就不应该有。
所以...
说在最后
- 也可以通过修改pytest项目的配置来解决这个问题,此处不表
实践是最好的理解方式,老师给你的往往是他的理解,其实也未必就100%对,当然现在这种做法我也只是探究了部分,也有不太理解的方式,没必要深究,能完成你的任务就ok了吧。
结论:单文件,建议修改模式;多文件(项目),写一个单独的文件来运行cases,模式不重要。
FAQ 关于allure和pycharm的运行模式的更多相关文章
- Django---Http协议简述和原理,HTTP请求码,HTTP请求格式和响应格式(重点),Django的安装与使用,Django项目的创建和运行(cmd和pycharm两种模式),Django的基础文件配置,Web框架的本质,服务器程序和应用程序(wsgiref服务端模块,jinja2模板渲染模块)的使用
Django---Http协议简述和原理,HTTP请求码,HTTP请求格式和响应格式(重点),Django的安装与使用,Django项目的创建和运行(cmd和pycharm两种模式),Django的基 ...
- selenium - pycharm三种案例运行模式
1.unittest 运行单个用例 (1)将鼠标放到对应的用例,右键运行即可 2.unittest运行整个脚本案例 将鼠标放到if __name__ == "__main__": ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 脚本可执行,但无HTML测试报告文件生成,其造成的原因是在PyCharm的执行模式错误
定义测试报告两种写法: 1)测试报告直接在本地绝对路径下生成 # 导入HTMLTestRunner模块 import HTMLTestRunner # 通过open()方法以二进制写模式('wb')打 ...
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- Spark运行模式与Standalone模式部署
上节中简单的介绍了Spark的一些概念还有Spark生态圈的一些情况,这里主要是介绍Spark运行模式与Spark Standalone模式的部署: Spark运行模式 在Spark中存在着多种运行模 ...
- PHP运行模式
1.运行模式 关于PHP目前比较常见的五大运行模式: 1)CGI(通用网关接口 / Common Gateway Interface) 2)FastCGI(常驻型CGI / Long-Live CGI ...
- 【转】Tomcat 的三种(bio,nio.apr) 高级 Connector 运行模式
转载地址:http://www.oschina.net/question/54100_16195 tomcat的运行模式有3种.修改他们的运行模式.3种模式的运行是否成功,可以看他的启动控制台,或 ...
- Tomcat Connector三种运行模式(BIO, NIO, APR)的比较和优化
Tomcat Connector的三种不同的运行模式性能相差很大,有人测试过的结果如下: 这三种模式的不同之处如下: BIO: 一个线程处理一个请求.缺点:并发量高时,线程数较多,浪费资源. Tomc ...
- javascript运行模式:并发模型 与Event Loop
看了阮一峰老师的JavaScript 运行机制详解:再谈Event Loop和[朴灵评注]的文章,查阅网上相关资料,把自己对javascript运行模式和EVENT loop的理解整理下,不一定对,日 ...
随机推荐
- ubuntu20.04修改静态ip不生效问题
一.前言 最近从头开始配置hadoop的时候,由于想切换到NAT模式下配置hadoop,但在修改ip的时候发现设置了静态ip,但ip不生效,查了很多资料,发现由于配置信息写错了. 二.解决问题 ifc ...
- 重大发现,AQS加锁机制竟然跟Synchronized有惊人的相似
在并发多线程的情况下,为了保证数据安全性,一般我们会对数据进行加锁,通常使用Synchronized或者ReentrantLock同步锁.Synchronized是基于JVM实现,而Reentrant ...
- perl大小写转换函数uc和lc
$side = uc $attrs[0]; #把attrs[0]转换成大写,然后给side变量赋值. $gender = lc $attrs[1]; #把attrs[1]转换成小写,然后给gender ...
- gorm-sqlite
package mainimport ( "encoding/json" "fmt" "github.com/jinzhu/gorm" &q ...
- leetcode学习记录2.13
[13] 罗马数字转整数 import java.util.HashMap; import java.util.Map; /* * * [13] 罗马数字转整数 * * https://leetcod ...
- 20、求解从1到20000内的所有水仙花数:每位数字的n次方之和等于其本身,n是这个数的位数。
/* 求解从1到20000内的所有水仙花数:每位数字的n次方之和等于其本身,n是这个数的位数. 共五位数,设置一个数组用来保存数字的每一位,数组的有效长度就是该数的位数.最后读取数组的每位数字来判断水 ...
- 区分mbr与gpt分区
查看分区类型 [root@localhost ~]# parted -l|egrep 'dev/|Part' Warning: Unable to open /dev/sr0 read-write ( ...
- IDEA提交任务到spark standalone集群
参考文章: 在idea里面怎么远程提交spark任务到yarn集群 代码 注意setJars,提交的代码,要提前打好包.否则会报找不到类的错误 个人理解就相当于运行的main方法是起了一个spark- ...
- Promise基础知识
Promise 1.Promise的前置小知识 进程(厂房) 程序的运行环境 线程(工人) 线程是实际进行运算的东西 同步 通常情况代码都是自上向下一行一行执行的 前边的代码不执行后边的代码也不会执行 ...
- 【Java SE】Day06 类与对象、封装和构造方法
一.面向对象思想 1.概述:调用对象的行为实现功能,无需一步一步实现(从执行者变成指挥者) 2.类和对象 类是属性和行为的集合,可以看成描述事物的模板 对象是事物的具体体现,是类的一个实例,具备该类的 ...