十九 Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
css选择器
1、

2、
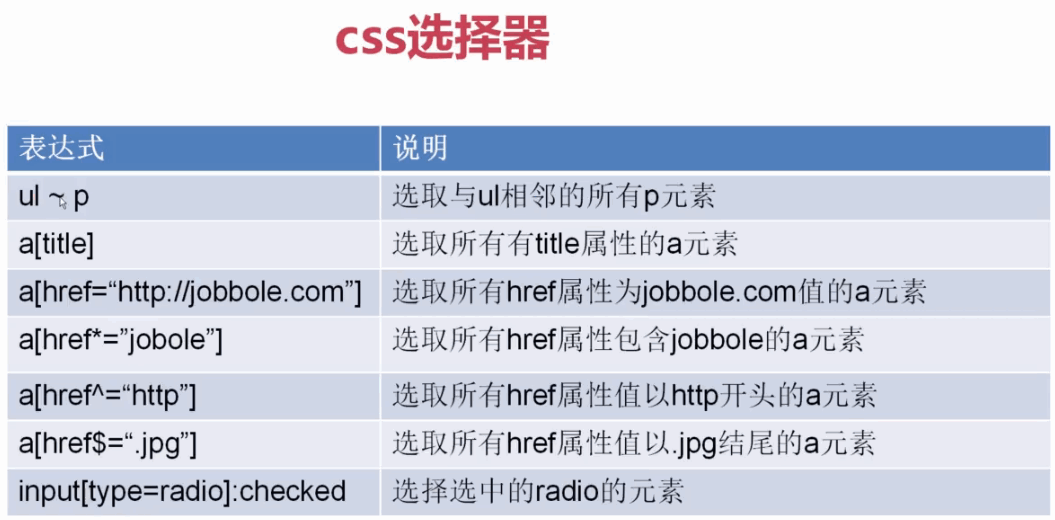
3、
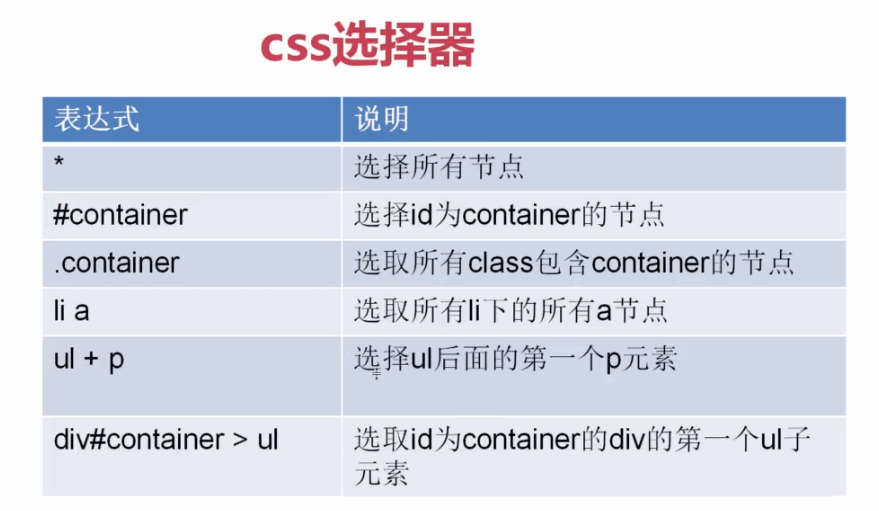
::attr()获取元素属性,css选择器
::text获取标签文本
举例:
extract_first('')获取过滤后的数据,返回字符串,有一个默认参数,也就是如果没有数据默认是什么,一般我们设置为空字符串
extract()获取过滤后的数据,返回字符串列表

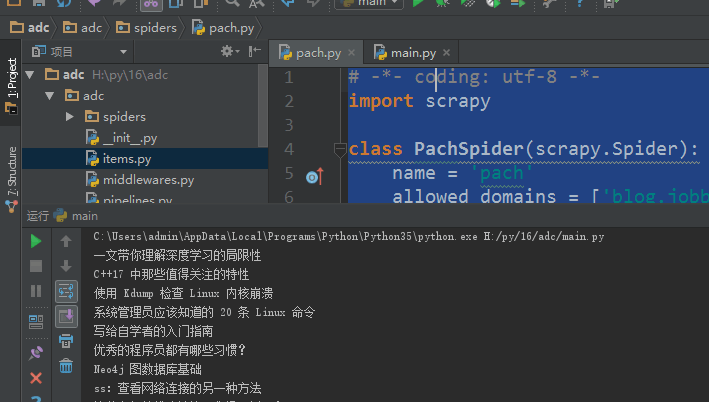
# -*- coding: utf-8 -*-
import scrapy class PachSpider(scrapy.Spider):
name = 'pach'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): asd = response.css('.archive-title::text').extract() #这里也可以用extract_first('')获取返回字符串
# print(asd) for i in asd:
print(i)
十九 Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器的更多相关文章
- 第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器
第三百四十节,Python分布式爬虫打造搜索引擎Scrapy精讲—css选择器 css选择器 1. 2. 3. ::attr()获取元素属性,css选择器 ::text获取标签文本 举例: extr ...
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 四十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
逻辑处理函数 计算搜索耗时 在开始搜索前:start_time = datetime.now()获取当前时间 在搜索结束后:end_time = datetime.now()获取当前时间 last_t ...
- 三十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫微角色的名字 3.分片:将索引(相当于数据库)划 ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
随机推荐
- 最新zencart支付宝插件(支持1.5)
最新zencart支付宝插件(支持1.5) 最新zencart支付宝插件(支持1.5) 支付宝接口的兼容性真不错,时至今日还能用,想利用zencart来做国内时长还真是方便多了,朋友们可以试试. ...
- gitHub新项目的上传
github作为一个开源托管平台,除了有机会学习各位大神的开源项目,还能托管自己写的一些小Demo,作为github新进菜鸟,今天就整理下上传Demo所需的命令和操作步骤,防止我这谜一样的记忆力. 1 ...
- [转]VMware-Transport(VMDB) error -44:Message.The VMware Authorization Service is not running解决方案
转自:http://blog.sina.com.cn/s/blog_70c9c4b40101i01v.html 1.VMware Workstation中新建的虚拟机在开机的时候出现这种错误:Tran ...
- 今天刚接触lua 写写环境配置和基本设置
首先是安装开发工具: Quick: http://www.tairan.com/engines-download 引擎 Sublime Text的下载地址为:http://www.sublimetex ...
- linux 常用命令总结(三)
1. setup // 进入相应配置界面,按空格键选择相关功能 2. ll // 列出当前目录下详细内容 :等价与ls -all 3. clear // 清理当前 ...
- maven 介绍(一)
本文内容主要摘自:http://www.konghao.org/index 内部视频 http://www.ibm.com/developer ...
- CentOS6.5安装Qt4.8.6+QtCreator2.6.1
工作中需要用到Qt在Linux下做开发,公司提供的电脑安装的CentOS6.2,但是为了和windows下自己使用的QT版本一直,于是也选择安装了Qt5.1.0.但是在CentOS下刚开始是无法启动, ...
- linux下 安装php的gettext模块
安装php的模块有两种方式: 一.重新编译php,加上--with-gettext 二.动态安装 现在说下第二个动态安装 1.下载同版本的php原包,解压后进入ext目录,目录下便是模块 2.进入ge ...
- python 数据分析----matplotlib
Matplotlib是一个强大的Python绘图和数据可视化的工具包. 安装方法:pip install matplotlib 引用方法:import matplotlib.pyplot as plt ...
- Koa源码解析
Koa是一款设计优雅的轻量级Node.js框架,它主要提供了一套巧妙的中间件机制与简练的API封装,因此源码阅读起来也十分轻松,不论你从事前端或是后端研发,相信都会有所收获. 目录结构 首先将源码下载 ...