第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH
一.首先,先搭建三台小集群,虚拟机的话,创建三个
下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去,我这三台的用户名都是hadoop,主机名随意起
192.168.0.20-----master(主机),nameNode,jobtracker----master(主机名)
192.168.0.21-----slave1(从机),dataNode,tasktracker-----slave1(主机名)
192.168.0.22-----slave2(从机),dataNode,tasktracker-----slave2(主机名)
如果用户名不一致,你就要创建一个用户组,把用户放到用户组下面:
sudo addgroup hadoop 创建hadoop用户组
sudo adduser -ingroup hadoop one 创建一个one用户,归到hadoop组下
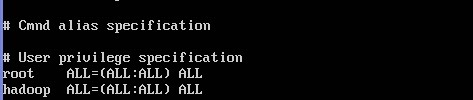
二.由于用户是普通用户,没有root一些权限,所以修改hadoop用户权限
用root权限,修改sudoers文件
nano /etc/sudoers 打开文件,修改hadoop用户权限,如果你创建的是one用户,就one ALL=(ALL:ALL) ALL
三.在这三台机子上分别设置/etc/hosts及/etc/hostname
hosts这个文件用于定于主机名与IP地址之间的对用关系
sudo -i 获取最高权限
nano /etc/hosts:

ctrl+o:保存,然后回车,ctrl+x:退出
hostname 这个文件用于定义主机名的,
注意:主机是主机名,从机就是从机名,例如:slave1在这里就是slave1

然后你可以输入:ping slave1,看能不能ping通
重启IP地址:/etc/init.d/networking restart
四.要在这三台机子上均安装jdk,ssh,并配置好环境变量,三台机子都是这个操作::
做好准备工作,下载jdk-7u3-linux-i586.tar 这个软件包
1.sudo apt-get install openssh-server 下载SSH
ssh 查看,代表安装成功
2. tar zxvf jdk-7u3-linux-i586.tar.gz 解压jdk
3.sudo nano /etc/profile,在最下面加入这几句话,保存,这是配置java环境变量

4.source /etc/profile 使其配置生效
验证jdk是否安装成功,敲命令
5.java -version 可以看到JDK版本信息,代表安装成功

6:配置SSH 免密码登陆,记住,这是在hadoop用户下执行的
ssh-keygen -t rsa 之后一路回 车(产生秘钥,会自动产生一个.ssh文件

8.cd .ssh 进入ssh文件
cp id_rsa.pub authorized_keys 把id_rsa.pub 追加到授权的 key 里面去
9. ssh localhost 此时已经可以进行ssh localhost的无密码登陆

或者 ls .ssh/ 看看有没有那几个文件
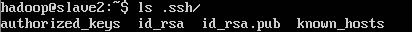
10.拷贝id_dsa.pub文件到其他机器
192.168.0.20 操作:
scp .ssh/id_rsa.pub 192.168.0.21:/home/hadoop/.ssh/20.pub
scp .ssh/id_rsa.pub 192.168.0.22:/home/hadoop/.ssh/20.pub
192.168.0.21 操作:
scp .ssh/id_rsa.pub 192.168.0.20:/home/hadoop/.ssh/21.pub
scp .ssh/id_rsa.pub 192.168.0.22:/home/hadoop/.ssh/21.pub
192.168.0.22 操作:
scp .ssh/id_rsa.pub 192.168.0.20:/home/hadoop/.ssh/22.pub
scp .ssh/id_rsa.pub 192.168.0.21:/home/hadoop/.ssh/22.pub
11.公钥都追加到 那个授权文件里
在192.168.0.20机子上操作:
cat .ssh/21.pub >> .ssh/authorized_keys
cat .ssh/22.pub >> .ssh/authorized_keys
在192.168.0.21机子上操作:
cat .ssh/20.pub >> .ssh/authorized_keys
cat .ssh/22.pub >> .ssh/authorized_keys
在192.168.0.22机子上操作:
cat .ssh/20.pub >> .ssh/authorized_keys
cat .ssh/21.pub >> .ssh/authorized_keys
验证ssh 192.168.0.21 hostname
会出现主机名:slave1
配置hadoop集群2.2.0版本
1.我把hadoop文件放在 /home/hadoop路径下,首先先进行解压
tar zxvf hadoop-2.2.0.tar.gz
2.hadoop配置过程,
配置之前,需要在hadoop本地文件系统创建以下文件夹:
/dfs/name
/dfs/data
/tmp
给这些文件要赋予权限
sudo chmod 777 tmp/
sudo chmod 777 dfs/
这里要涉及到的配置文件有7个:
~/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
~/hadoop-2.2.0/etc/hadoop/yarn-env.sh
~/hadoop-2.2.0/etc/hadoop/slaves
~/hadoop-2.2.0/etc/hadoop/core-site.xml
~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml
~/hadoop-2.2.0/etc/hadoop/mapred-site.xml
~/hadoop-2.2.0/etc/hadoop/yarn-site.xml
以上个别文件默认不存在的,可以复制相应的template文件获得。
例如mapred-site.xml不存在
cd /home/hadoop/hadoop-2.2.0/etc/hadoop 进入到hadoop配置文件的目录中
cp mapred-site.xml.template mapred-site.xml 复制相应的模板文件
3.配置hadoop-env.sh
sudo nano /home/hadoop/hadoop-2.2.0/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03 配置jdk
4.配置yarn-env.sh
sudo nano /home/hadoop/hadoop-2.2.0/etc/hadoop/yarn-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03 配置jdk
5.配置slaves,写入一下内容
slave1
slave2
6.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
7.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
8.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
9.配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
master配置完以后,可是直接把hadoop文件复制到从机,这样可以节省时间
命令是在hadoop用户下进行:这个只需要在主机运行就可以了
scp -r /home/hadoop/hadoop-1.1.2 hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/hadoop-1.1.2 hadoop@slave2:/home/hadoop/
10.hadoop集群启动与测试:这个只需要在主机上运行就可以了
sudo -i 获取root权限
chown -R hadoop:hadoop /home/hadoop/hadoop-1.2.1 给hadoop用户赋予权限
命令在hadoop用户下进行:
su hadoop 切换hadoop用户
cd /home/hadoop/hadoop-1.1.2
bin/hadoop namenode -format 格式化文件,格式化文件只能格式化一次
/sbin/start-dfs.sh 启动所有的节点
11.测试 http://192.168.0.20:50070
搭建Zookeeper集群
1.下载zookeeper-3.4.5版本:zookeeper-3.4.5.tar.gz,我是放在/home/hadoop下面
tar zxvf zookeeper-3.4.5.tar.gz 直接进行解压
2.配置etc/profile
sudo nano etc/profile 在末尾加入下面配置
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.5
export PATH=$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf:$PATH
3.配置zookeeper-3.4.5/conf/zoo.cfg文件,这个文件本身是没有的,有个zoo_sample.cfg模板
cd zookeeper-3.4.5/conf 进入conf目录
cp zoo_sample.cfg zoo.cfg 拷贝模板
sudo nano zoo.cfg 修改zoo.cfg文件,红色是修改部分
---------------------------------------------------------------------------------------------------
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/zookeeper-3.4.5/data
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
------------------------------------------------------------------------------------------------------
注意:创建dataDir参数指定的目录,创建data文件夹,在这个文件夹下,还要创建一个文本myid
cd /home/hadoop/zookeeper-3.4.5
mkdir data 创建data
cd /home/hadoop/zookeeper-3.4.5/data 进入data文件夹下
touch myid 创建文本myid,在这个文本内写入1,因为server.1=master:2888:3888 server指定的是1,
如果一会在从机配置,slave1下面的myid是2,slave2下面myid是3,这些都是根据server来的
4.主机配置完以后,把zookeeper复制给从机
scp -r zookeeper-3.4.5 hadoop@slave1:/home/hadoop/
scp -r zookeeper-3.4.5 hadoop@slave1:/home/hadoop/
记住修改从机的myid.从机也要配置etc/profile
5.启动zookeeper,先hadoop集群启动
zkServer.sh start 这个启动是主机从机都要输入启动命令
bin/zkServer.sh status在不同的机器上使用该命令,其中二台显示follower,一台显示leader
zkCli.sh -server 192.168.0.21:2181 启动客户端脚本
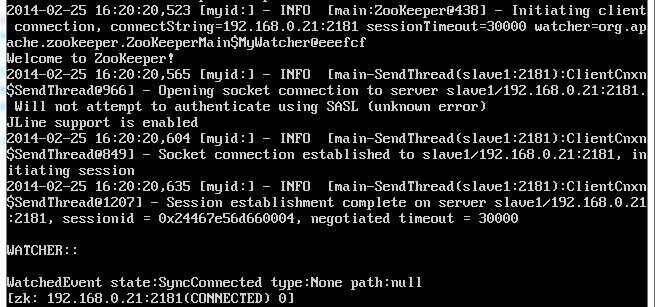
quit 退出
help 可是查看帮助命令
这样zookeeper集群就配置完了
搭建hbase集群
1.下载并解压hbase-0.98.0-hadoop2-bin.tar.gz到/home/hadoop下面
tar zxvf hbase-0.98.0-hadoop2-bin.tar.gz
2.修改 hbase-env.sh ,hbase-site.xml,regionservers 这三个配置文件如下:
2.1修改 hbase-env.sh
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2 /conf/hbase-env.sh
export JAVA_HOME=/home/hadoop/jdk1.7.0_03
export HBASE_HOME=/home/hadoop/hbase-0.98.0-hadoop2
export HADOOP_HOME=/home/hadoop/hadoop-2.2.0
export PATH=$PATH:/home/hadoop/hbase-0.98.0-hadoop2/bin
export HBASE_MANAGES_ZK=false
注意:如果hbase想用自身的zookeeper, HBASE_MANAGES_ZK属性变为true.
2.2修改 hbase-site.xml
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>
注意:hbase.zookeeper.property.clientPort配置的这个端口号必须跟zookeeper配置的clientPort端口号一致。
2.3修改 regionservers
sudo nano /home/hadoop/ hbase-0.98.0-hadoop2/conf/regionservers
写入以下内容:
slave1
slave2
chown -R hadoop:hadoop /home/hadoop/ hbase-0.98.0-hadoop2 给hbase赋予权限
复制hbase到从机
scp -r /home/hadoop/hbase-0.98.0-hadoop2 hadoop@slave1:/home/hadoop/
scp -r /home/hadoop/ hbase-0.98.0-hadoop2 hadoop@slave2:/home/hadoop/
然后启动hbase,输入命令,记住:一定要先启动hadoop集群,才能启动hbase
bin/start-hbase.sh
我们也可以通过WEB页面来管理查看HBase数据库。
HMaster:http://192.168.0.20:60010/master.jsp
可以输入jps查看HMaster

然后输入如下命令进入hbase的命令行管理界面:quit 退出
bin/hbase shell

bin/stop-hbase.sh 关闭hbase
启动顺序:hadoop---zookeeper----hbase
第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群的更多相关文章
- 搭建伪分布式 hadoop3.1.3 + zookeeper 3.5.7 + hbase 2.2.2
安装包 Hadoop 3.1.3 Zookeeper 3.5.7 Hbase 2.2.2 所需工具链接: 链接:https://pan.baidu.com/s/1jcenv7SeGX1gjPT9RnB ...
- Redis集群研究和实践(基于redis 3.0.5)
前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的2.x的稳定版本是2.8.19,也是我们项目中普遍用到的版本. redis在年初发布了3.0. ...
- dis集群研究和实践(基于redis 3.0.5) 《转载》
https://www.cnblogs.com/wxd0108/p/5798498.html 前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- HBase-0.98.0和Phoenix-4.0.0分布式安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 相关端口 2 4. 下载HBase 2 5. 安装步骤 2 5.1. 修改conf/regionservers 2 5.2. 修改conf/hba ...
- CentOS6.5下nginx-1.8.1.tar.gz的单节点搭建(图文详解)
不多说,直接上干货! [hadoop@djt002 local]$ su root Password: [root@djt002 local]# ll total drwxr-xr-x. root r ...
- hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的集群搭建(单节点)
前言 本人呕心沥血所写,经过好一段时间反复锤炼和整理修改.感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接.http://www.cnblogs.com/zlslch/p/ ...
- hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改.感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接.http://www.cnblogs.com/zlslch/p/584 ...
随机推荐
- 2018.11.13 N4010A 通信设置
设置电脑之IP地址及Subnet mask. IP address: 192.168.1.2 Subnet mask: 255.255.255.0, 其它选项为默认. 然后点击OK ...
- New Concept English Two 34 game over
$课文95 纯属虚构 1049. When the Ambassador or Escalopia returned home for lunch, his wife got a shock. 当艾 ...
- node 垃圾回收
一些思考 回收 nodejs垃圾回收 跟浏览器js不同, 以下代码会找出内存泄露 var theThing = null var replaceThing = function () { var o ...
- PHP错误Parse error: syntax error, unexpected end of file in test.php on line 12解决方法
出现这个错误的原因就是语法错误,肯定是PHP程序的书写不规范造成,PHP语句标识符错了,没有在php.ini中开启短标签!八成是这个原因,啊啊啊! 今天在写PHP程序的时候总是出现这样的错误:Pars ...
- JAVA交换两个变量的值-(不使用第三变量)
以下方法的根本原理就是: 借助第三个变量 c = a; a = b; b = c; 运算符-不借助第三变量: a = a+b; b = a-b; a = a-b; 为运算符-不借助第三个变量: (此种 ...
- TF随笔-10
#!/usr/bin/env python# -*- coding: utf-8 -*-import tensorflow as tf x = tf.constant(2)y = tf.constan ...
- Leetcode 894. All Possible Full Binary Trees
递归 # Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val = x # ...
- day3 文件系统 内核模块 ctags
nfs网络文件系统 smb 修改配置文件 sudo vim /etc/samba/smb.conf 重启服务 /etc/init.d/samba restart 自制小的文件系统 1 ...
- BZOJ2555 SubString【后缀自动机+LCT】
Description 懒得写背景了,给你一个字符串init,要求你支持两个操作 (1):在当前字符串的后面插入一个字符串 (2):询问字符串s在当前字符串中出现了几次?(作为连续子串) 你必须在线支 ...
- 字符串处理scanf("%d%*c",&n);
"*"表示该输入项读入后不赋予任何变量,即跳过该输入值.这在减小内存开支上面还是有一点用处的,不需要的字符直接跳过,免得申请没用的变量空间 你的例子中的%*c的作用是读入'\n', ...