【spark】示例:求Top值
我们有这样的两个文件


第一个数字为行号,后边为三列数据。我们来求第二列数据的Top(N)
(1)我们先读取数据,创建Rdd
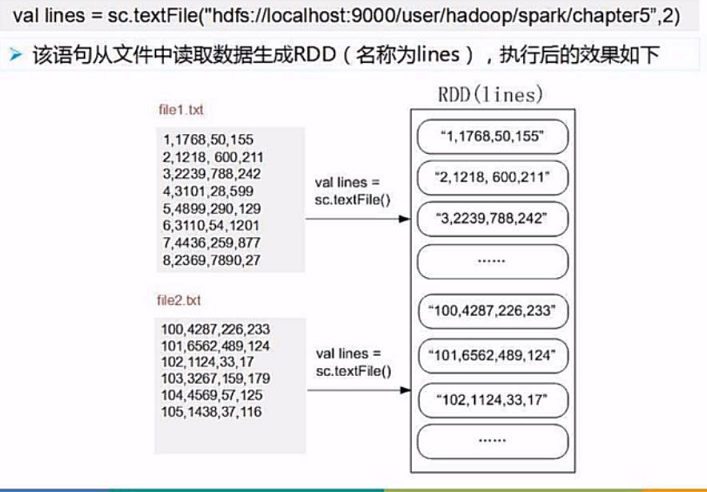
(2)过滤数据,取第二列数据。
我们用filter()来过滤数据
line.trim().length是除去行末尾的空格然后计算长度,长度大于0,并且分能用逗号切分为4个子数据的数据为有效数据。
然后我们来切分取出第二列数据,即arr(2),arr(0)为行号
line.map(_.split(",")(2))
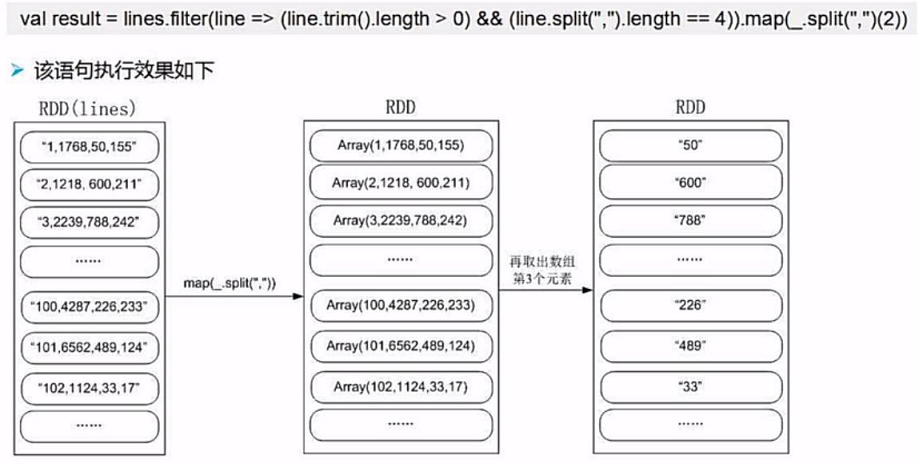
(3)数据类型转换并修改成键值对的形式
我们通过.map(x=>(x.toInt,""))把原来数据(string)修改成为(int,String)类型的键值对
为什么要这么做呢?因为我们要采用orderByKey()方法进行排序。
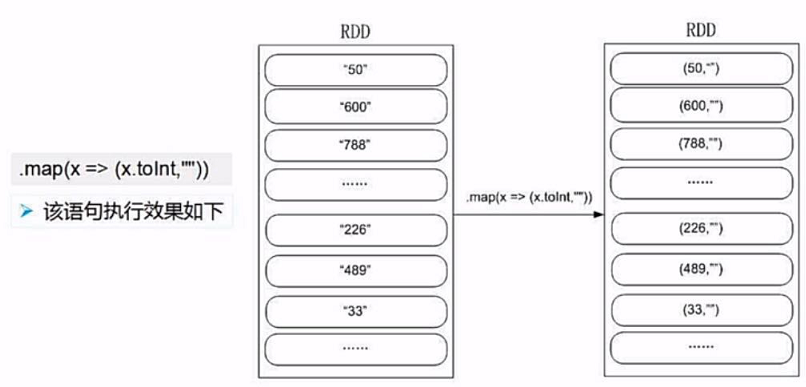
(4)排序取出键值对中的键
我们先调用orderByKey(false)方法对rdd中的每个键值对按照键值进行排序,false参数:是否正序
然后我们通过 x=>x._1 取排序后的键值对的键,最后通过take(N)方法即可实现取TOP(N)的功能
(5)将结果存入文件
通过saveAsTextFile(“file://”)方法将结果存入文件
完整代码
import org.apache.spark.{SparkConf, SparkContext}
object TopN {
//建立SparkContext
val sparkConf = new SparkConf().setAppName("TopN")
val sc = new SparkContext(sparkConf)
//设置日志等级,只显示报错
sc.setLogLevel("ERROR")
//读取数据,分区
val lines = sc.textFile("hdfs://localhost:9000/user/local/spark/data",2)
var num = 0//排名初始化
var result = lines.filter(line => (line.trim.length > 0 && line.split(",").length > 4))//过滤数据
.map(_.split(",")(2)) //拆分文件取第二列数
.map(x =>(x.toInt,"")) //修改数据类型并转化为键值对的形式
.sortByKey(false)//排序
.map(x => x._1)//取键
.take(5)//取前五条数据
.foreach( x =>{ //显示数据
num = num + 1 //排名
println(num+"\t"+x) //显示
})
}
注意,我们在使用sortByKey方法前,数据是分了区的
我们使用了sortByKey方法将分区了的数据进行排序可能会出错,具体原因不是很清楚。
所以有时候我们需要在sortByKey()方法前加一个.partitionBy(new HashPartitioner(1))从新分成一个区来保证正确率。
【spark】示例:求Top值的更多相关文章
- Sql示例说明如何分组后求中间值--【叶子】
原文:Sql示例说明如何分组后求中间值--[叶子] 这里所谓的分组后求中间值是个什么概念呢? 我举个例子来说明一下: 假设我们现在有下面这样一个表: type name price -- ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- [NOI2005]维修数列 Splay tree 区间反转,修改,求和,求最值
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1500 Description Input 输入文件的第1行包含两个数N和M,N表示初始时数 ...
- Spark学习之键值对操作总结
键值对 RDD 是 Spark 中许多操作所需要的常见数据类型.键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式.键值对 RDD ...
- Spark学习笔记——键值对操作
键值对 RDD是 Spark 中许多操作所需要的常见数据类型 键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式. Spark 为包 ...
- 使用Scala编写Spark程序求基站下移动用户停留时长TopN
使用Scala编写Spark程序求基站下移动用户停留时长TopN 1. 需求:根据手机基站日志计算停留时长的TopN 我们的手机之所以能够实现移动通信,是因为在全国各地有许许多多的基站,只要手机一开机 ...
- 堆实战(动态数据流求top k大元素,动态数据流求中位数)
动态数据集合中求top k大元素 第1大,第2大 ...第k大 k是这群体里最小的 所以要建立个小顶堆 只需要维护一个大小为k的小顶堆 即可 当来的元素(newCome)> 堆顶元素(small ...
- NC15052 求最值
NC15052 求最值 题目 题目描述 给你一个长为 \(n\) 的序列 \(a\) 定义 \(f(i,j)=(i-j)^2+g(i,j)^2\) \(g\) 是这样的一个函数 求最小的 \(f(i, ...
随机推荐
- Python获取指定目录下所有子目录、所有文件名
需求 给出制定目录,通过Python获取指定目录下的所有子目录,所有(子目录下)文件名: 实现 import os def file_name(file_dir): for root, dirs, f ...
- 第一节:web 框架本质
1.web请求本质是什么: web请求本质:就是一个socket. 浏览器充当是客户端,python充当一个服务器端 浏览器请求相当一次tcp请求,请求完成断开连接 ,下次去的时候 ...
- rest_framework 响应器
一 作用 根据 用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件.用户请求URL: http://127.0.0.1:8000/test/?format=json http:/ ...
- 我的Android进阶之旅------>Android Listview跳到指定条目位置的两种实现方法
前言 今天实现ListView跳转到第一个条目位置时,使用smoothScrollToPosition(int position)方法跳转实现了,但是交互说不需要这样的动画效果,需要直接跳转到第一项, ...
- Python的3个方法:静态方法(staticmethod),类方法(classmethod)和实例方法
Python的方法主要有3个,即静态方法(staticmethod),类方法(classmethod)和实例方法,如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ...
- unity3d相关资源
http://pan.baidu.com/s/1kTG9DVD GUI源码
- Java-idea-创建maven项目,部署项目,部署服务器,简单测试
spring-boot项目创建 1.项目创建 使用Idea,File→Project→Spring initalizr,点击next,进行基本配置.此时 一个spring boot项目创建完成. 之后 ...
- 008-CentOS添加环境变量
在Linux CentOS系统上安装完php和MySQL后,为了使用方便,需要将php和mysql命令加到系统命令中,如果在没有添加到环境变量之前,执行“php -v”命令查看当前php版本信息时时, ...
- django基础2: 路由配置系统,URLconf的正则字符串参数,命名空间模式,View(视图),Request对象,Response对象,JsonResponse对象,Template模板系统
Django基础二 request request这个参数1. 封装了所有跟请求相关的数据,是一个对象 2. 目前我们学过1. request.method GET,POST ...2. reques ...
- HDU 6356 Glad You Came 2018 Multi-University Training Contest 5 (线段树)
题目中没有明说会爆int和longlong 的精度,但是在RNG函数中不用unsigned int 会报精度,导致队友debug了很久... 根据每次生成的l,r,v对区间更新m次,然后求 i*ai的 ...