Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版)
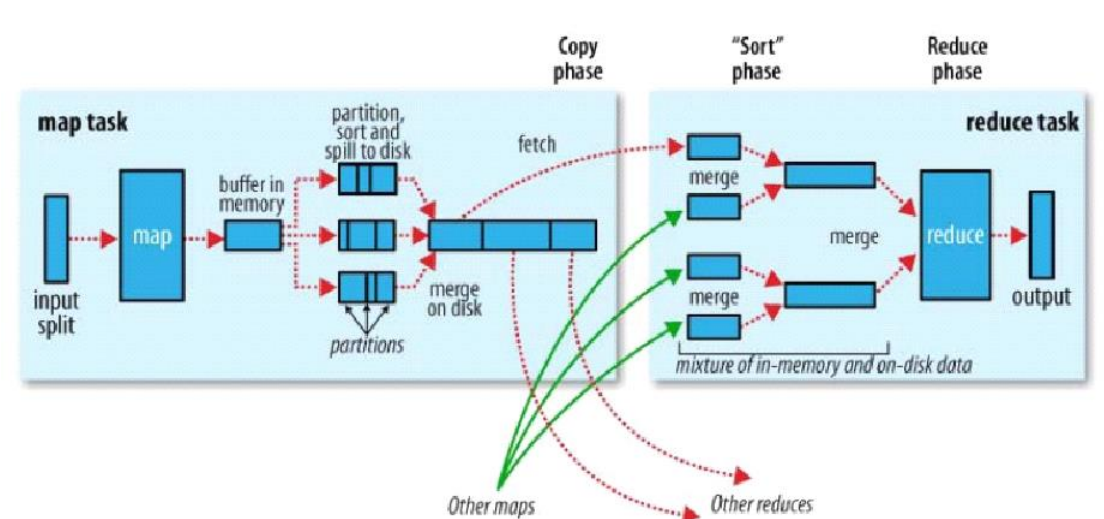
实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解
1eg 数据如下 2014010114 标识20140101日的温度为14度,需求为统计每年温度的最最高值
2014010114
2014010216
2014010317
2014010410。。。
Partition 实际是根据map 任务的key,以及reduce任务的数量来决定最终来由那个reduce来处理,默认指定reduce的方法是key的hash 对reduce的数量取模来决定由那个reduce处理,map端将年作为key,温度作为value ,不指定reduce任务的情况下 默认的reduce数量为1,按照上面的规则 hashcode%1 =0(任何数对1求模对为0) 所以看到最后输出到HDFS中的文件名为part-r-0000 证明只有1个reduce 来处理任务
为了验证上面的猜想,自己重写了Partition规则, year%2 作为规则,偶数年为reduce1 处理, 奇数年由reduce2 处理,结果发现part-r-0000
2014 17
2012 32
2010 17
2008 37
part-r-0001
2015 99
2013 29
2007 99
2001 29
其中自己在reduce端做了二次排序,二次排序的概念就是 针对这组相对的key 怎么来输出结果,默认的牌勋规则是字典排序,按照英文字母的顺序,当然自己可以重写输出的规则,自己按照年的倒序输出,试验后基本明白了 shuffle 的partion 和reduce端的二次排序
partition重写负责如下
public class WDPartition extends HashPartitioner<Text,IntWritable> {
@Override
public int getPartition(Text text, IntWritable value, int numReduceTasks) {
// TODO Auto-generated method stub
int year = Integer.valueOf(text.toString());
return year%2;
}
}
reduce 的二次排序如下
public class WDSort extends WritableComparator{
public WDSort(){
super(Text.class, true);
}
//按照key 来降序排序
public int compare(WritableComparable a, WritableComparable b) {
String t1 = a.toString();
String t2 = b.toString();
return -Integer.compare(Integer.valueOf(t1), Integer.valueOf(t2));
}
}
Haoop MapReduce 的Partition和reduce端的二次排序的更多相关文章
- MapReduce在Map端的Combiner和在Reduce端的Partitioner
1.Map端的Combiner. 通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner... 只附录部分代码: /** * 以文本 * hello you * he ...
- 第2节 mapreduce深入学习:15、reduce端的join算法的实现
reduce端的join算法: 例子: 商品表数据 product: pidp0001,小米5,1000,2000p0002,锤子T1,1000,3000 订单表数据 order: pid ...
- Hadoop.2.x_高级应用_二次排序及MapReduce端join
一.对于二次排序案例部分理解 1. 分析需求(首先对第一个字段排序,然后在对第二个字段排序) 杂乱的原始数据 排序完成的数据 a,1 a,1 b,1 a,2 a,2 [排序] a,100 b,6 == ...
- 深入理解Spark 2.1 Core (十一):Shuffle Reduce 端的原理与源代码分析
http://blog.csdn.net/u011239443/article/details/56843264 在<深入理解Spark 2.1 Core (九):迭代计算和Shuffle的原理 ...
- hadoop的压缩解压缩,reduce端join,map端join
hadoop的压缩解压缩 hadoop对于常见的几种压缩算法对于我们的mapreduce都是内置支持,不需要我们关心.经过map之后,数据会产生输出经过shuffle,这个时候的shuffle过程特别 ...
- MapReduce中一次reduce方法的调用中key的值不断变化分析及源码解析
摘要:mapreduce中执行reduce(KEYIN key, Iterable<VALUEIN> values, Context context),调用一次reduce方法,迭代val ...
- MapReduce启动的Map/Reduce子任务简要分析
对于Hadoop来说,是通过在DataNode中启动Map/Reduce java进程的方式来实现分布式计算处理的,那么就从源码层简要分析一下hadoop中启动Map/Reduce任务的过程. ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
随机推荐
- 关于股票最佳买卖时机的lintcode代码
class Solution {public: /** * @param prices: Given an integer array * @return: Maximum pr ...
- poj3261 Milk Patterns 后缀数组求可重叠的k次最长重复子串
题目链接:http://poj.org/problem?id=3261 思路: 后缀数组的很好的一道入门题目 先利用模板求出sa数组和height数组 然后二分答案(即对于可能出现的重复长度进行二分) ...
- WinRAR5.01注册码附注册机
把下面的注册码复制到"记事本"中,另存为"rarreg.key"文件,放到WinRAR安装目录即完成注册.RAR registration datakjcy8U ...
- Linux 下按时间顺序批量删除文件
ls -lrt| awk '{print $9}'| head -n 10 | xargs rm -rf 1.文件按时间排序: 2.获取文件名字: 3.取前10个文件 4.删除文件
- 关于MySQL数据库的一些操作
启动:net start MySQL 关闭:net stop MySQL (也可以用quit:) 登录到MySQL:mysql -u root -p -u : 所要登录的用户名; -p : 告诉服务器 ...
- Linux如何安装VMware Tools
第一步:安装VMware Tools 桌面上会出现一个光盘,并且会弹出一个框框,里面是VMware Tools的安装包,将其拖到桌面上 就像下面这样 进入终端,将文件拷贝到/tmp目录下面,并解压(也 ...
- Web攻防系列教程之跨站脚本攻击和防范技巧详解
摘要:XSS跨站脚本攻击一直都被认为是客户端Web安全中最主流的攻击方式.因为Web环境的复杂性以及XSS跨站脚本攻击的多变性,使得该类型攻击很 难彻底解决.那么,XSS跨站脚本攻击具体攻击行为是什么 ...
- 关于图的顶点染色问题的各种算法的C++实现之初探(一)——引言与简介
我是一个数学工作者,专业方向是图论.研究图论已经十年有余.一个月前,一个偶然的机会让我萌生了一个念头,那就是我想尝试用C++写出我所学过的图论方面的算法.作为一个数学工作者,过去一直是纸上谈兵,我之前 ...
- Promise (1) 初步接触
总想着王者荣耀排位赛再提升个等级就弃掉游戏好好学习,然而打了两个周也没升上去,看来是应该换个方向发挥了. 最近看了<javascript Promise迷离书>,对Promise的理解颇有 ...
- python 获取utc时间转化为本地时间
import datetime timenow = (datetime.datetime.utcnow() + datetime.timedelta(hours=8)) timetext = time ...