使用Jsoup 爬取网易首页所有的图片
package com.enation.newtest; import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.apache.commons.lang3.StringEscapeUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document; // 爬取网易首页所有图片
public class Jsoup163 { public static void main(String[] args) throws Exception{
String downloadPath = "D:\\360Downloads\\test";
List<String> list = nameList("网易--首页");
getPictures(list,1,downloadPath); //1代表下载一页,一页一般有30张图片
} public static void getPictures(List<String> keywordList, int max,String downloadPath) throws Exception{ // key为关键词,max作为爬取的页数
String gsm=Integer.toHexString(max)+"";
String finalURL = "";
String tempPath = "";
for(String keyword : keywordList){
tempPath = downloadPath;
if(!tempPath.endsWith("\\")){
tempPath = downloadPath+"\\";
}
tempPath = tempPath+keyword+"\\";
File f = new File(tempPath);
if(!f.exists()){
f.mkdirs();
}
int picCount = 1;
for(int page=1;page<=max;page++) {
sop("正在下载第"+page+"页面");
Document document = null;
try {
String url ="http://www.163.com/";
sop(url);
document = Jsoup.connect(url).data("query", "Java")//请求参数
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")//设置urer-agent get();
.timeout(5000)
.get();
String xmlSource = document.toString();
xmlSource = StringEscapeUtils.unescapeHtml3(xmlSource);
//sop(xmlSource);
String reg = "<img.*src=(.*?)[^>]*?>";
String reg2 = "src\\s*=\\s*\"?(.*?)(\"|>|\\s+)";
String reg2datasrc = "data-src\\s*=\\s*\"?(.*?)(\"|>|\\s+)"; Pattern pattern = Pattern.compile(reg);
Pattern pattern2 = Pattern.compile(reg2);
Pattern pattern2datasrc = Pattern.compile(reg2datasrc); Matcher m = pattern.matcher(xmlSource);
while (m.find()){
finalURL = m.group();
System.out.println(finalURL);
Matcher m2 = null;
if(finalURL.indexOf("data-src")>0){
m2 = pattern2datasrc.matcher(finalURL);
}else {
m2 = pattern2.matcher(finalURL);
}
if(m2.find()){
finalURL = m2.group(1);
System.out.println(finalURL);
if(finalURL.startsWith("http")){
sop(keyword+picCount+++":"+finalURL);
download(finalURL,tempPath);
sop(" 下载成功");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
sop("下载完毕");
delMultyFile(downloadPath);
sop("已经删除所有空图");
}
public static void delMultyFile(String path){
File file = new File(path);
if(!file.exists())
throw new RuntimeException("File \""+path+"\" NotFound when excute the method of delMultyFile()....");
File[] fileList = file.listFiles();
File tempFile=null;
for(File f : fileList){
if(f.isDirectory()){
delMultyFile(f.getAbsolutePath());
}else{
if(f.length()==0)
sop(f.delete()+"---"+f.getName());
}
}
}
public static List<String> nameList(String nameList){
List<String> arr = new ArrayList<String>();
String[] list;
if(nameList.contains(","))
list= nameList.split(",");
else if(nameList.contains("、"))
list= nameList.split("、");
else if(nameList.contains(" "))
list= nameList.split(" ");
else{
arr.add(nameList);
return arr;
}
for(String s : list){
arr.add(s);
}
return arr;
}
public static void sop(Object obj){
System.out.println(obj);
}
//根据图片网络地址下载图片
public static void download(String url,String path){
//path = path.substring(0,path.length()-2);
File file= null;
File dirFile=null;
FileOutputStream fos=null;
HttpURLConnection httpCon = null;
URLConnection con = null;
URL urlObj=null;
InputStream in =null;
byte[] size = new byte[1024];
int num=0;
try {
String downloadName= url.substring(url.lastIndexOf("/")+1);
dirFile = new File(path);
if(!dirFile.exists() && path.length()>0){
if(dirFile.mkdir()){
sop("creat document file \""+path.substring(0,path.length()-1)+"\" success...\n");
}
}else{
file = new File(path+downloadName);
fos = new FileOutputStream(file);
if(url.startsWith("http")){
urlObj = new URL(url);
con = urlObj.openConnection();
httpCon =(HttpURLConnection) con;
int responseCode = httpCon.getResponseCode();
if(responseCode == 200){
in = httpCon.getInputStream();
while((num=in.read(size)) != -1){
for(int i=0;i<num;i++)
fos.write(size[i]);
}
}else {
System.out.println("状态码:"+responseCode+" 地址:"+url);
}
}
}
}catch (FileNotFoundException notFoundE) {
sop("找不到该网络图片....");
}catch(NullPointerException nullPointerE){
sop("找不到该网络图片....");
}catch(IOException ioE){
sop("产生IO异常.....");
}catch (Exception e) {
e.printStackTrace();
}finally{
try {
if(fos!=null){
fos.close();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
其中,关键点在于获取图片img标签的正则表达式和图片的链接地址
String reg = "<img.*src=(.*?)[^>]*?>";
String reg2 = "src\\s*=\\s*\"?(.*?)(\"|>|\\s+)";
运行结果:
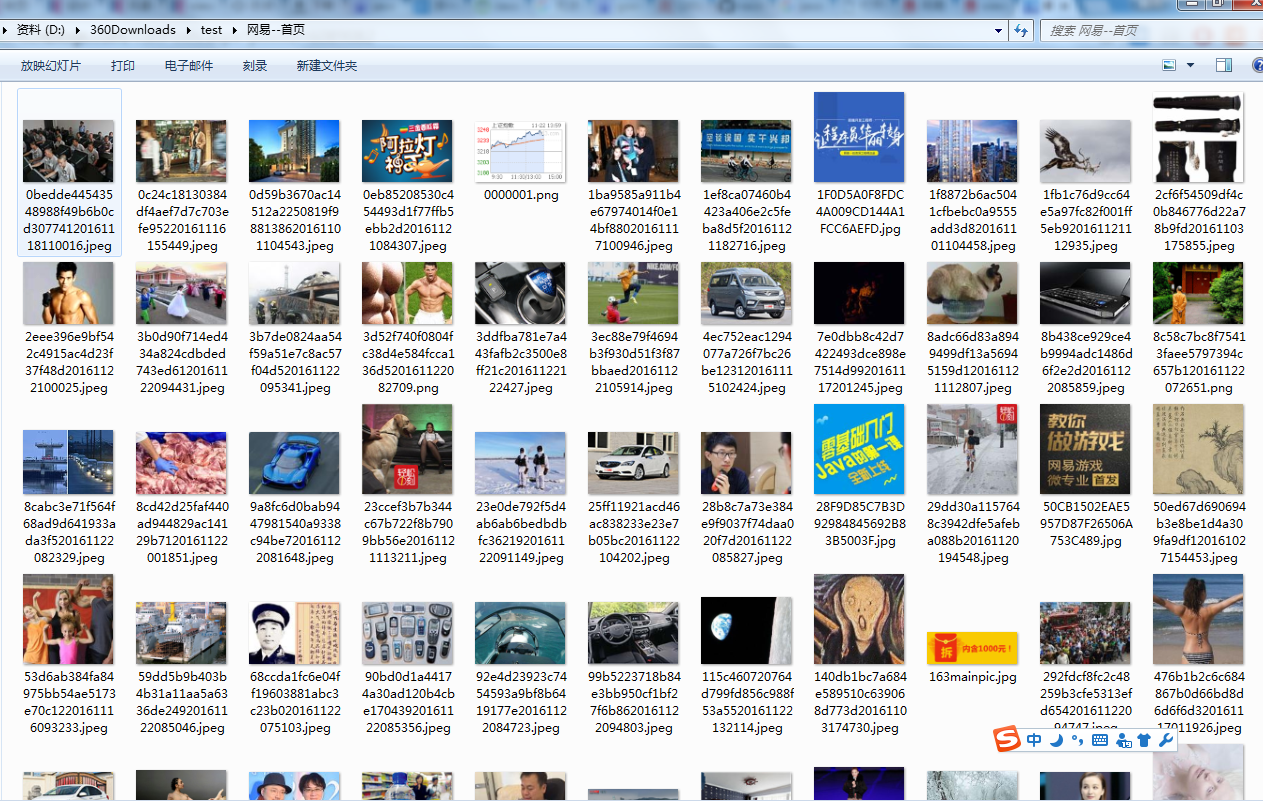
使用Jsoup 爬取网易首页所有的图片的更多相关文章
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- 如何利用python爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: LSGOGroup PS:如有需要Python学习资料的小伙伴可以 ...
- jsoup爬取某网站安全数据
jsoup爬取某网站安全数据 package com.vfsd.net; import java.io.IOException; import java.sql.SQLException; impor ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
- 初识python 之 爬虫:爬取某网站的壁纸图片
用到的主要知识点:requests.get 获取网页HTMLetree.HTML 使用lxml解析器解析网页xpath 使用xpath获取网页标签信息.图片地址request.urlretrieve ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- Python爬取贴吧中的图片
#看到贴吧大佬在发图,准备盗一下 #只是爬取一个帖子中的图片 1.先新建一个scrapy项目 scrapy startproject TuBaEx 2.新建一个爬虫 scrapy genspider ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
随机推荐
- [Delphi编译错误]F2084 Internal Error: U2107
看到这个错误真是头痛,这是一个很旧的项目了,想修改下东西,清理下工程一编译出现这个该死的错误,百度了下,也没解决问题.没办法只好编译所有的BPL了. 这个项目是带包编译的,而且带了几个自己的包. ...
- tar 打包命令
Usage: tar -[cxtzjhmvO] [-X FILE] [-T FILE] [-f TARFILE] [-C DIR] [FILE]... Create, extract, or list ...
- 【转】sudo命令情景分析
文章转自:http://www.cnblogs.com/hazir/p/sudo_command.html Linux 下使用 sudo 命令,可以让普通用户也能执行一些或者全部的 root 命令.本 ...
- pdflatex, xelatex, texstudio中文编码问题
使用xelatex,源文件需要用utf-8编译,pdf文件不会乱码. 使用pdflatex,源文件不能使用utf-8编码,否则pdf文件会乱码. 使用GB2312没问题.
- HTML5的touch事件
HTML5中新添加了很多事件,但是由于他们的兼容问题不是很理想,应用实战性不是太强,所以在这里基本省略,咱们只分享应用广泛兼容不错的事件,日后随着兼容情况提升以后再陆续添加分享.今天为大家介绍的事件主 ...
- Java 入门 代码2浮点数据类型
/** * 基本数据类型之浮点类型 */ public class DataTypeDemo2 { public static void main(String[] args) { double d1 ...
- ubuntu 启动项创建器 选择不了CD镜像,IOS镜像的解决方法
自己系统是ubuntu14.04 , 想使用 ubuntu自带的启动项创建器(usb-creator-gtk)做一个CDLinux的U盘启动项, 打开程序后发现U盘识别了, 在添加镜像的时候,发现怎么 ...
- LLVM 初探<一>
一.安装LLVM LLVM是一个低级虚拟机,全称为Low Level Virtual Machine.LLVM也是一个新型的编译器框架,相关的介绍Wikipedia. 现在LLVM的版本已经有很多,根 ...
- python基础整理笔记(四)
一. python 打开文件的方法 1. python中使用open函数打开文件,需要设定的参数包括文件的路径和打开的模式.示例如下: f = open('a.txt', 'r+') 2. f为打开文 ...
- 从一个Fragment跳转到另一个Fragment
我们知道Activity之间的跳转可以使用 startActivity(intent).但Fragment之间的跳转却不能使用该方法,那该怎么办呢? 直接上代码: 核心代码 @Override//核心 ...