【爬虫实战】用python爬小红书任意话题的笔记,以#杭州亚运会#为例
一、爬取目标
您好!我是@马哥python说,一名10年程序猿。
最近的亚运会大家都看了吗。除了振奋人心,还主打一个爱憎分明(主要针对小日子和韩国),看了的小伙伴都懂得!
我用python爬取了小红书上 #杭州亚运会 这个话题下的所有笔记,目标如下:
爬取结果如下:
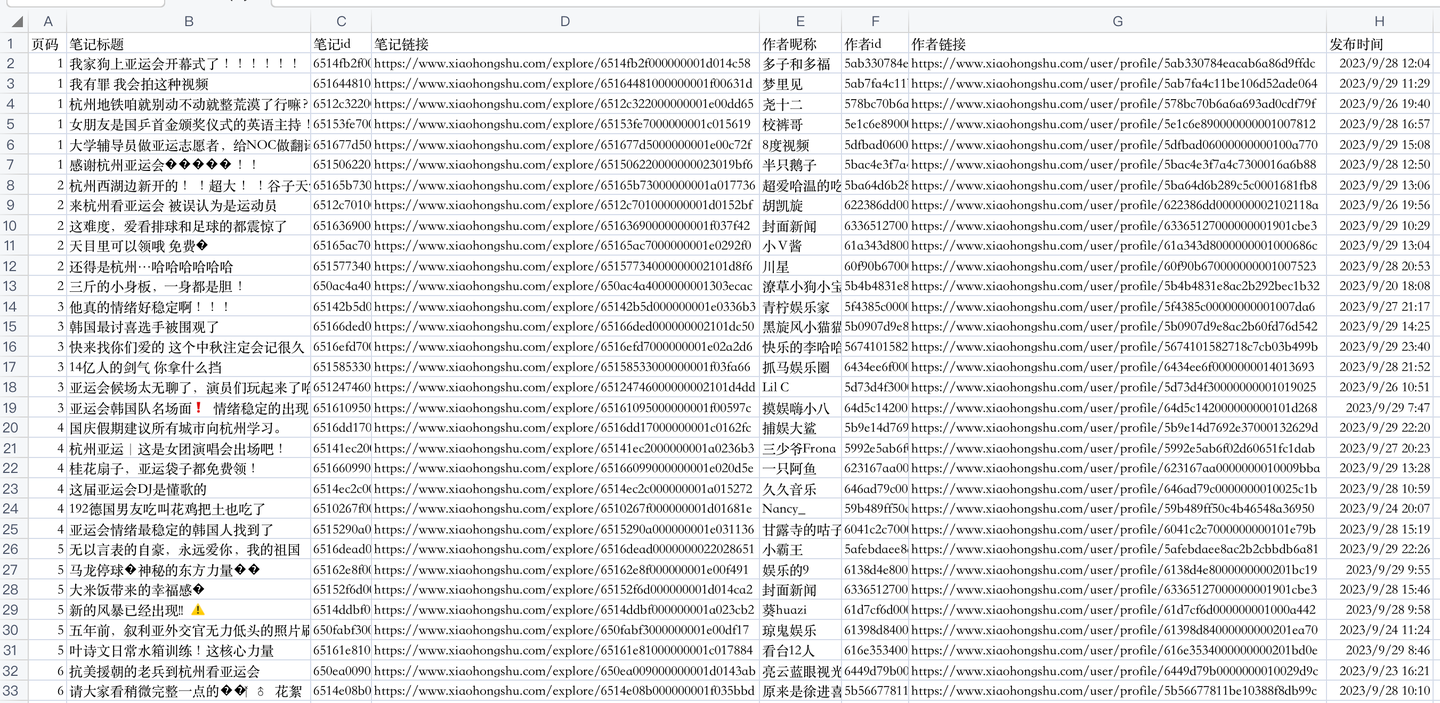
共7个核心字段,含:
笔记标题, 笔记id, 笔记链接, 作者昵称, 作者id, 作者链接, 发布时间。
二、爬虫代码讲解
2.1 分析过程
核心思路,通过网页端分析接口数据实现。
点击手机客户端右上角分享按钮,然后选择复制链接,如下:
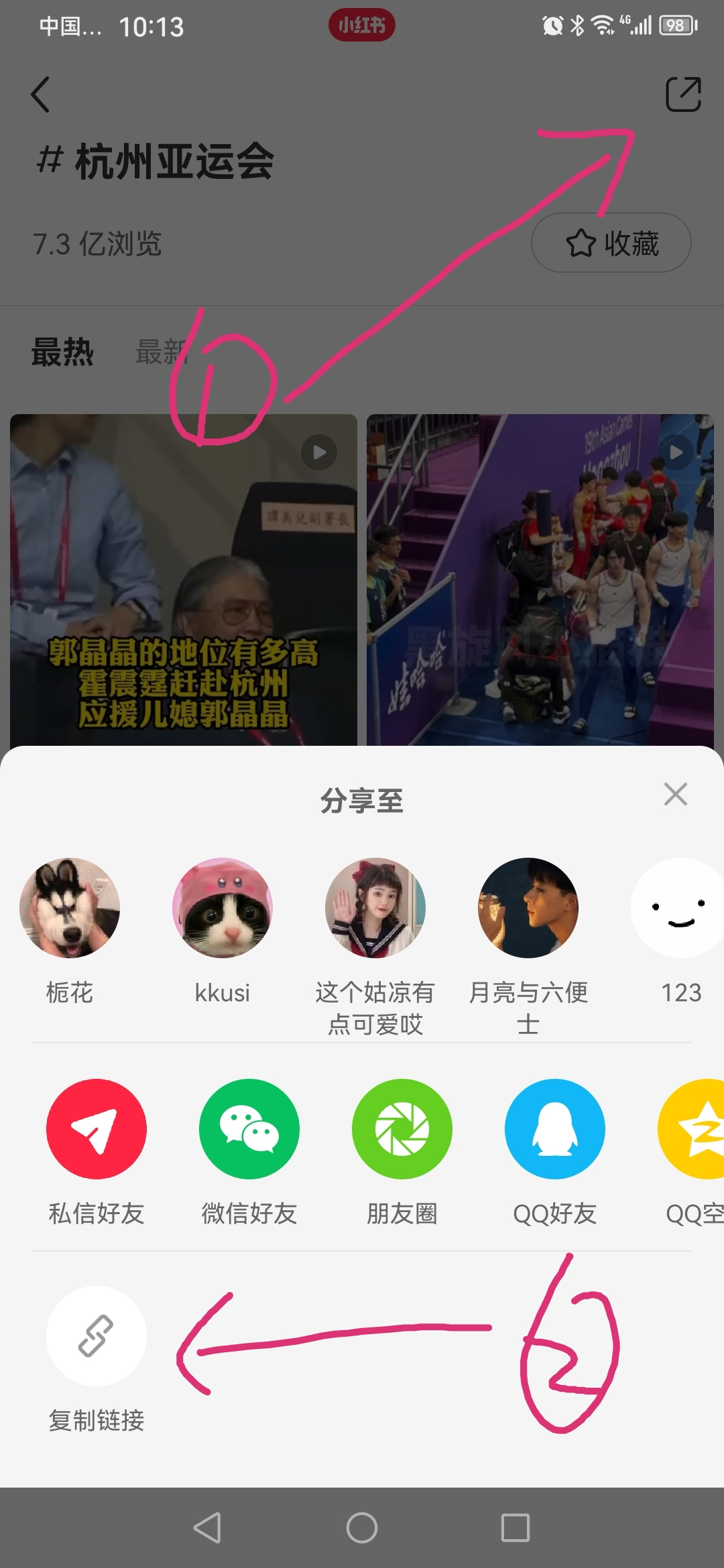
把复制好的链接粘贴到电脑端浏览器,并打开开发者模式,如下:
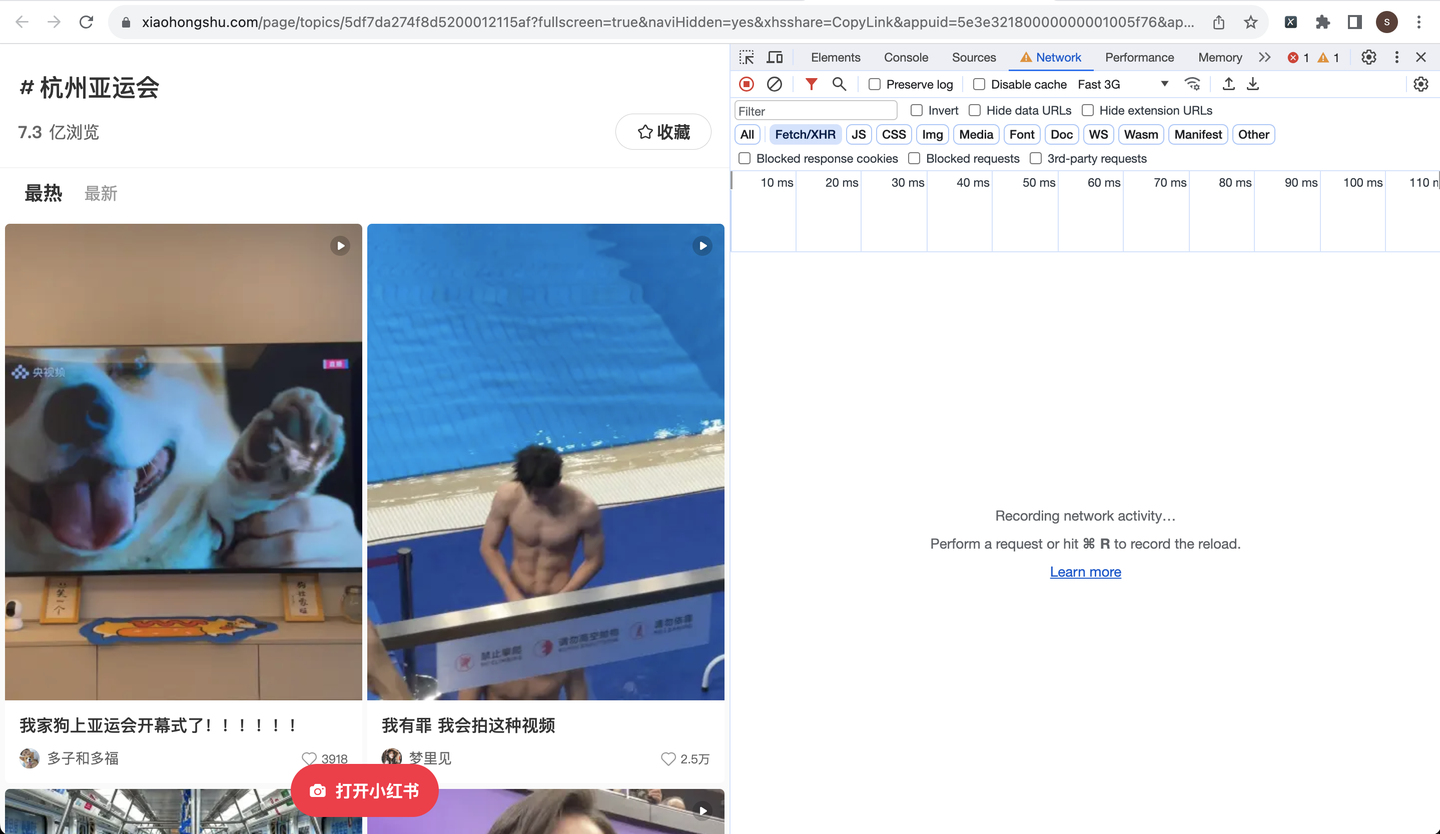
页面往下滚动,刷出更多笔记数据,打开以notes开头的请求链接,查看预览数据:
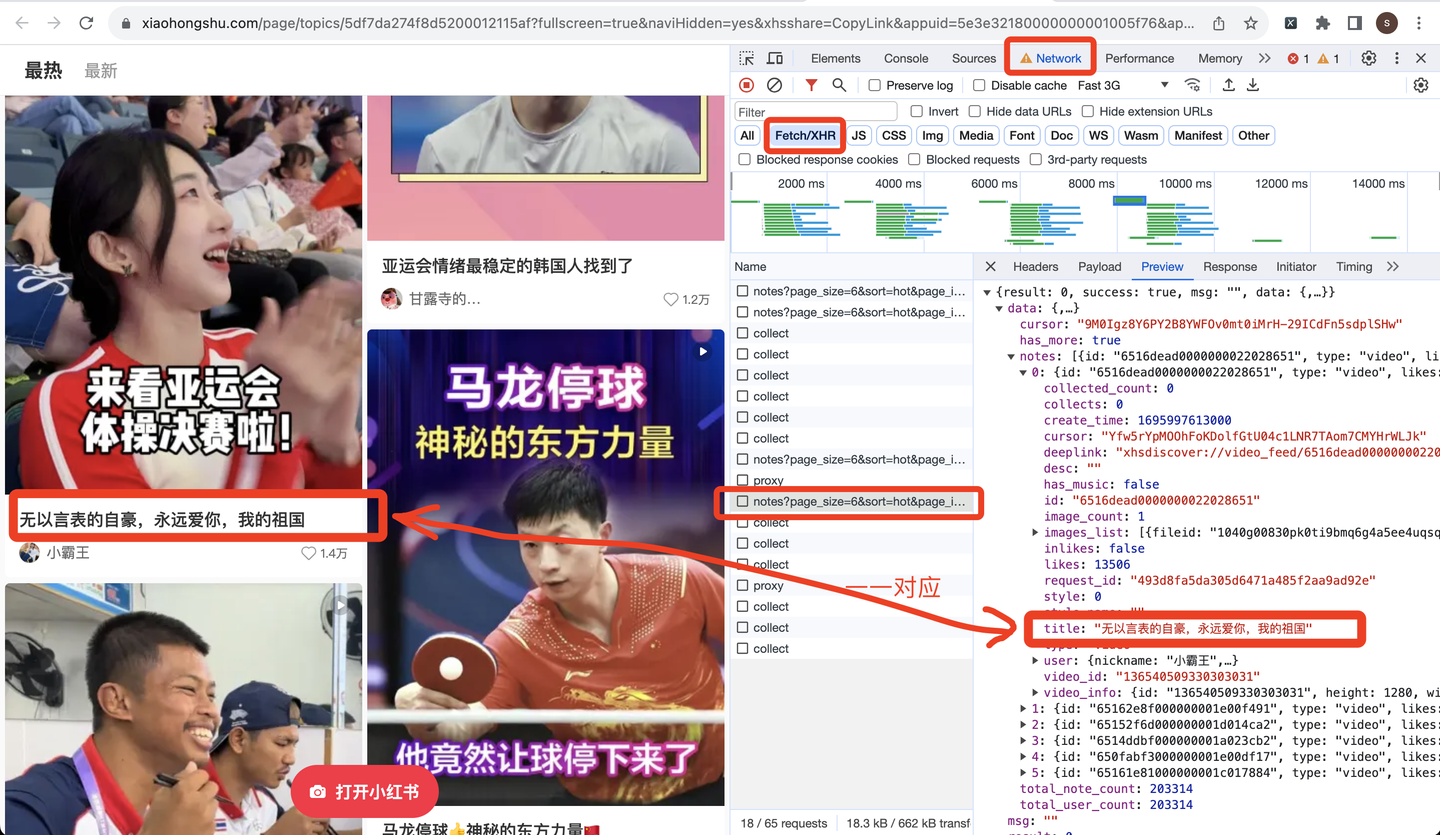
由此便得到了前端请求链接,下面开始开发爬虫代码。
2.2 爬虫代码
首先,导入需要用到的库:
import requests # 发送请求
import random
from time import sleep # 设置等待,防止反爬
import time
import pandas as pd # 保存csv
import datetime
import os
定义一个请求头:
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
}
由于我并不知道一共有多少页,往下翻多少次,所以采用while循环,直到触发终止条件,循环才结束。
那么怎么定义终止条件呢?我注意到,在返回数据里有一个叫做"has_more"的参数,大胆猜测它的含义,是否有更多数据,正常情况它的值是true。如果它的值是false,代表没有更多数据了,即到达最后一页了,也就该终止循环了。
因此,核心代码结构应该是这样(以下是伪代码,主要是表达逻辑,请勿直接copy):
while True:
# 发送请求
r = requests.get(url, headers=h1)
# 解析数据
json_data = r.json()
# 逐条解析
for i in json_data['data']['notes']:
# 笔记标题
title = i['title']
title_list.append(title)
# 保存数据到csv
。。。
# 判断终止条件
next_cursor = json_data['data']['cursor']
if not json_data['data']['has_more']:
print('没有下一页了,终止循环!')
break
page += 1
另外,还有一个关键问题,如何进行翻页。
查看请求参数,如下:
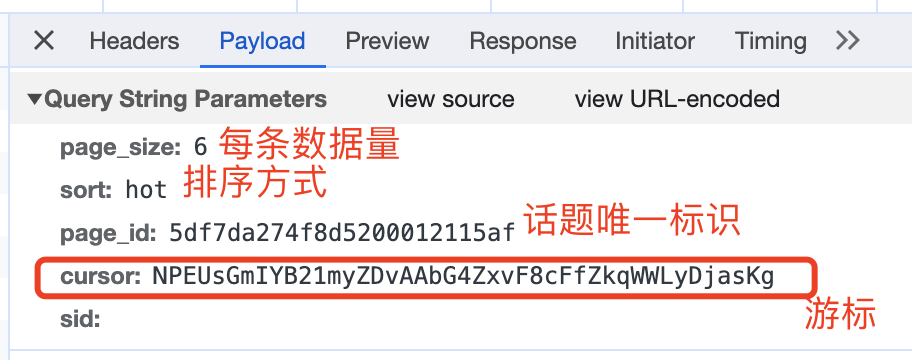
这里的游标,就是向下翻页的依据,因为每次请求的返回数据中,也有一个cursor:
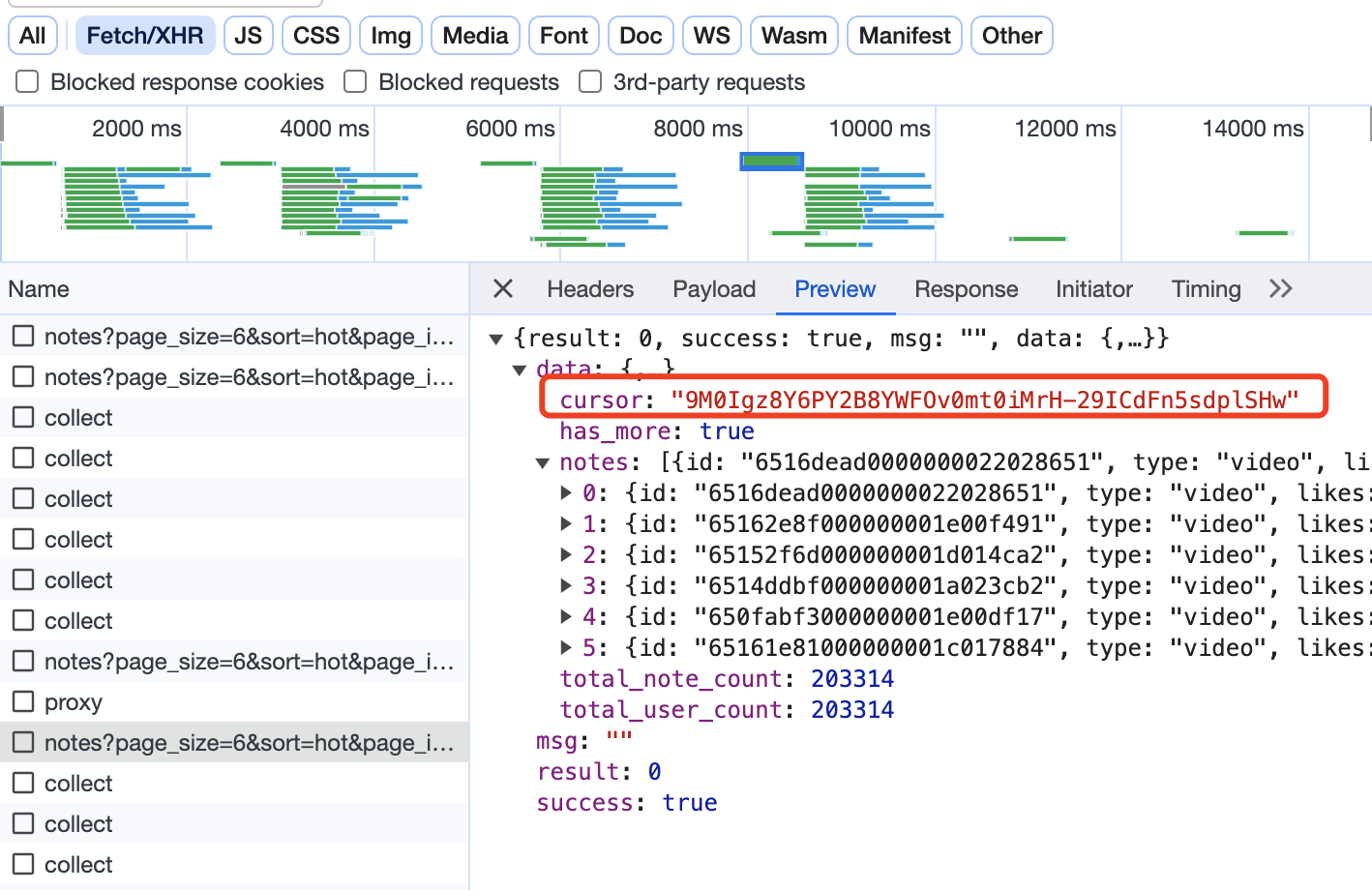
大胆猜测,返回数据中的cursor,就是给下一页请求用的cursor,所以,这部分的逻辑实现应该如下(以下是伪代码,主要是表达逻辑,请勿直接copy):
while True:
# 判断是否首页
if page == 1:
url = 'https://www.xiaohongshu.com/web_api/sns/v3/page/notes?page_size=6&sort=hot&page_id={}&sid='.format(
page_id)
else:
url = 'https://www.xiaohongshu.com/web_api/sns/v3/page/notes?page_size=6&sort=hot&page_id={}&sid=&cursor={}'.format(
page_id, next_cursor)
# 发送请求
r = requests.get(url, headers=h1)
# 解析数据
json_data = r.json()
# 得到下一页的游标
next_cursor = json_data['data']['cursor']
最后,是顺理成章的保存csv数据:
# 保存数据到DF
df = pd.DataFrame(
{
'页码': page,
'笔记标题': title_list,
'笔记id': note_id_list,
'作者昵称': author_name_list,
'作者id': author_id_list,
'发布时间': create_time_list,
}
)
# 保存到csv
df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')
至此,爬虫代码开发完毕。
完整代码中,还包含转换时间戳、随机等待时长、解析关键字段、保存Dataframe数据等逻辑实现,详见文末。
三、演示视频
代码演示:【Python爬虫演示】爬取小红书话题笔记,以#杭州亚运会#为例
四、获取完整代码
爱学习的小伙伴,本次分析过程的完整python源码及结果数据,我已打包好,并上传至我的微信公众号"老男孩的平凡之路",后台回复"爬小红书话题"即可获取。点击直达
我是@马哥python说,一名10年程序猿,持续分享python干货中!
【爬虫实战】用python爬小红书任意话题的笔记,以#杭州亚运会#为例的更多相关文章
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战三之爬取嗅事百科段子
一.前言 俗话说,上班时间是公司的,下班了时间才是自己的.搞点事情,写个爬虫程序,每天定期爬取点段子,看着自己爬的段子,也是一种乐趣. 二.Python爬取嗅事百科段子 1.确定爬取的目标网页 首先我 ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取QQ音乐
一.前言 前段时间尝试爬取了网易云音乐的歌曲,这次打算爬取QQ音乐的歌曲信息.网易云音乐歌曲列表是通过iframe展示的,可以借助Selenium获取到iframe的页面元素, 而QQ音乐采用的是 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战教程:爬取网易新闻
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Amauri PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Python爬虫实战教程:爬取网易新闻;爬虫精选 高手技巧
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. stars声明很多小伙伴学习Python过程中会遇到各种烦恼问题解决不了.为 ...
随机推荐
- KingbaseES V8R3 集群运维案例--sys_rewind恢复备库节点
案例说明: 在KingbaseES V8R3集群执行failover切换后,原主库被人为误(未配置recovery.conf)启动:或者人为promote备库为主库后.需要将操作节点再重新加入集群 ...
- Scala 复杂分词求和(二元组)
1 package chapter07 2 3 object Test18_ComplexWordCount { 4 def main(args: Array[String]): Unit = { 5 ...
- 企业数据清洗项目实践day1
今天先把国标excel表的数据在Python里转化成了字典类型, 暂时定共分为四层,层层分类. 代码 1 def std_excel(): 2 dict={"A":{"0 ...
- C++设计模式 - 享元模式(Flyweight)
对象性能模式 面向对象很好地解决了"抽象"的问题,但是必不可免地要付出一定的代价.对于通常情况来讲,面向对象的成本大都可以忽略不计.但是某些情况,面向对象所带来的成本必须谨慎处理. ...
- #团,构造#洛谷 3524 [POI2011]IMP-Party
题目 有一个 \(3n\) 个点的无向图,保证有一个大小为 \(2n\) 的团,输出一个大小为 \(n\) 的团 分析 每次选择两个不相连的点删掉,那么剩下的 \(n\) 个点一定是团, 因为每次至少 ...
- 5. Determinant
5.1 The Properties of Determinants The determinant of the n by n identity matrix is 1 : \(det I = 1\ ...
- C语言 02 安装
C 语言的编译器有很多,其中最常用的是 GCC,这里以安装 GCC 为例. Windows 这里以 Windows 11 为例 官方下载地址:https://www.mingw-w64.org/ 选择 ...
- HR必备|可视化大屏助HR实现人才资源价值最大化
人力资源管理质量的优劣关系到企业可持续发展目标的实现,在信息化时代背景下,应用信息技术加强人力资源管理过程的优化,利用技术提升人力资源管理质量和效率已是大势所趋. 利用信息技术构建信息化人力资源管理平 ...
- 报表输入页码翻页(润乾 V2018)
报表数据分了太多页,一页一页翻页查看数据嫌麻烦,可以试试这种翻页效果--输入页码翻页. 润乾报表提供了翻页相关的 JS 函数,可以在报表展现的页面中添加 JS 调用翻页函数实现输入页码跳转到对应页. ...
- Matlab绘图(2)通过代码进行局部放大绘图、多文件绘图
Matlab进阶绘图 在这次的绘图练习中,我们需要考虑一次性将所有数据文件逐一读入,然后对每幅图图片进行放大处理. 参数设置 这里包括每幅图的标题,图例,读入文件的名称,等等 title_d = {' ...