深度学习/NLP中的Attention注意力机制
首先是整体认知,Attention的位置:

传送门1:Attention 机制
传送门2:Attention用于NLP的一些小结
一句话概括:Attention就是从关注全局到关注重点。
借鉴了人类视觉的选择性注意力机制,核心目标也是从众多信息中选择出更关键的信息。
Attention的思路就是:带权求和。
Attention机制本身并不依赖于特定的框架。
具体的介绍看这篇文章,写的很详细,传送门3:深度学习中的注意力机制
在关于使用Encoder-Decoder框架中,进行机器翻译的Attention机制,这篇文章有句话:
“目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。
就是生成的概率分布就是作为实际应用中由输入得到结果的概率分布。
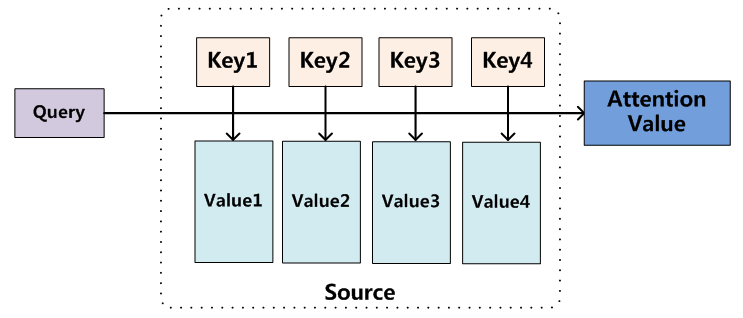
参考上面链接的文章,Attention机制就是:
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。
个人理解:Attention就是从关注全局到关注重点。体现在权重系数的分配上,分配的值越大,说明关注度越高,也就是越重要。
链接文章的作者说,Attention机制算是一种寻址操作,个人理解感觉有点像遍历一个存了<key,value>的数组,通过条件查询key值,然后对对应的value值进行加权求和,最后得到结果。

Attention注意力机制
用图片很详细的介绍了机器翻译中,Attention的机制,主要介绍了以下内容:
seq2seq + attention
seq2seq with bidirectional encoder + attention
seq2seq with 2-stacked encoder + attention
GNMT — seq2seq with 8-stacked encoder (+bidirection+residual connections) + attention
传送门5:入门 | 什么是自注意力机制?
传动门6:Attention机制简单总结
传送门7:自然语言处理中的Attention机制总结 这篇写的很有逻辑
深度学习/NLP中的Attention注意力机制的更多相关文章
- AAAI2018中的自注意力机制(Self-attention Mechanism)
近年来,注意力(Attention)机制被广泛应用到基于深度学习的自然语言处理(NLP)各个任务中.随着注意力机制的深入研究,各式各样的attention被研究者们提出,如单个.多个.交互式等等.去年 ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 深度剖析java中JDK动态代理机制
https://www.jb51.net/article/110342.htm 本篇文章主要介绍了深度剖析java中JDK动态代理机制 ,动态代理避免了开发人员编写各个繁锁的静态代理类,只需简单地指定 ...
- 如何可视化深度学习网络中Attention层
前言 在训练深度学习模型时,常想一窥网络结构中的attention层权重分布,观察序列输入的哪些词或者词组合是网络比较care的.在小论文中主要研究了关于词性POS对输入序列的注意力机制.同时对比实验 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- 寻找下一款Prisma APP:深度学习在图像处理中的应用探讨(阅读小结)
原文链接:https://yq.aliyun.com/articles/61941?spm=5176.100239.bloglist.64.UPL8ec 某会议中的一篇演讲,主要讲述深度学习在图像领域 ...
- Attention注意力机制介绍
什么是Attention机制 Attention机制通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素.其中重要程度的判断取决于应用场景,拿个现实生活中的例子,比如1000个人眼中有100 ...
- 深度学习网络中numpy多维数组的说明
目前在计算机视觉中应用的数组维度最多有四维,可以表示为 (Batch_size, Row, Column, Channel) 以下将要从二维数组到四维数组进行代码的简单说明: Tips: 1) 在nu ...
- 深度学习-Caffe中启用MatlabSupport编译出错的解决方案
一.如果编译前打算生成支持Matlab的库,则设置MatlabSupport为true之后. 二.记得添加Matlab的安装路径.我的是:D:\Application\DevTools\Matlab ...
- 如何使用网格搜索来优化深度学习模型中的超参数(Keras)
https://machinelearningmastery.com/grid-search-hyperparameters-deep-learning-models-python-keras/ Ov ...
随机推荐
- js 异步 任务 题目解析(chatgpt bug了?)
最近遇到一道题如下,求输出结果 感觉还是蛮有意思的,找chatgpt做了一下 我是题 async function async1(){ console.log('1'); await async2() ...
- git http(s) 保存用户密码
git 常用配置 git记住密码 1.设置记住密码(默认15分钟): git config --global credential.helper cache 2.如果想自己设置时间,可以这样做: gi ...
- Django+forms+html
在Django中,Form类通常通过继承django.forms.Form或django.forms.ModelForm来定义.当你定义一个表单类时,通常使用Form或ModelForm类,并使用各种 ...
- JMeter 逻辑控制之IF条件控制器
逻辑控制之IF条件控制器 测试环境 JMeter-5.4.1 循环控制器介绍 添加While Controller 右键线程组->添加->逻辑控制器->While控制器 控制器面板介 ...
- 题解:CF1971D Binary Cut
题解:CF1971D Binary Cut 题意 给予你一个 \(01\) 字符串,你可以将它分割,分割后必须排成先 \(0\) 后 \(1\) 的格式. 求最少分割为几部分. 思路 将 \(0\) ...
- springsecurity使用:登录与校验
首先是引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- Python和RPA网页自动化-异常处理Try方法
我们在跑自动化时为了捕获和处理异常,会增加异常处理Try方法.下面来看看Python和RPA网页自动化中异常处理Try的用法 1.Python中异常处理try的用法 try: test = " ...
- Jmeter函数助手3-RandomString
RandomString函数用于生成指定内容范围的指定长度随机字符. Random string length:限制生成的长度,比如输入6则会生成6位字符 Chars to use for rando ...
- 【C3】01 概述
CSS (层叠样式表) 让你可以创建好看的网页,但是它具体是怎么工作的呢? 这篇文章通过一些很简单的例子,告诉我们什么是 CSS, 同时还会涉及一些和 CSS 相关的专业术语. 预备知识: 基本的计算 ...
- 【H5】15 表单 其四 数据发送
一旦在客户端上验证了表单数据,就可以提交表单了. 并且,由于我们在上一篇文章中介绍了验证,因此我们准备提交! 本文着眼于用户提交表单时会发生什么-数据将流向何处,以及到达表单后如何处理? 我们还将研究 ...