机器学习:调整kNN的超参数
一、评测标准
- 模型的测评标准:分类的准确度(accuracy);
- 预测准确度 = 预测成功的样本个数/预测数据集样本总数;
二、超参数
- 超参数:运行机器学习算法前需要指定的参数;
- kNN算法中的超参数:k、weights、P;
- 一般超参数之间也相互影响;
- 调参,就是调超参数;
1)问题
# 以kNN算法为例
- 平票:如果k个点中,不同类型的样本数相等,怎么选取?
- 如果选取的k个点中,数量多的一类样本点距离测试样本较远,数量少的一类样本点距离测试样本较近,此时选取数量较多的类型作为输出结果,不具说服力;
2)kNN算法中,除了K值外的另一个超参数:距离的权重(1/距离)
- k个点中,将不同类的点的权重相加,最大的那一类为目标标签
- scikit-learn库中的KNeighborsClassifier类中,还有一个weights()函数;
- 在__init__()中默认两个参数值:__init__(n_neighbors = 5, weights = 'uniform');
- weights = 'uniform',表示不考虑距离权重这个超参数;
- weights= 'distance',表示考虑距离权重这个超参数;
3)kNN算法的第三个超参数:P,距离参数
- P是有“明科夫斯基距离”得来的(详见“四、距离推导”),
- 只有当kNN算法考虑距离权重超参数(weights)时,才会考虑是否输入距离参数(P);
4)调参的方法
- 调参目的,找到最优的超参数;
- 机器学习算法应用在不同的领域中,不同领域内有其特有的知识
1、通过领域知识得到
# 不同领域内,遇到不同的问题,产参数一般不同;
# 领域:如自然语言处理、视觉搜索等;
2、经验数值
# 一般机器学习算法库中,会封装一些默认的超参数,这些默认的超参数一般都是经验数值;
# kNN算法这scikit-learn库中,k值默认为5,5就是在经验上比较好的数值;
3、通过试验搜索得到
- 思路:将不同的超参数输入模型,选取准确度最高的超参数;
- 试验搜索也称为网格搜索:对不同的超参数,使用对个for语句,逐层搜索;
- 试验搜索过程:以kNN算法为例;
# 在Jupyter NoteBook中实现的代码 import numpy as np
from sklearn import datasets digits = datasets.load_digits()
X = digits.data
y = digits.target from ALG.train_test_split import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_train = 0.2) # 1)按经验选定超参数k = 5
from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(n_neighbors = 5)
knn_clf.fit(X_train, y_train)
knn_clf.score(X_test, y_test) # 2)按试验搜索,获取最优的超参数K,不考虑weights
best_score = 0.0
best_k = -1
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors = k)
knn_clf.fit(X_train, y_train)
knn_score = knn_clf.score(X_test, y_test)
if knn_score > best_score:
best_score = knn_score
best_k = k print("best_k = ", best_k)
print("best_score = ", best_score) # 3)按试验搜索,获取最优的超参数k、weight
best_method = ""
best_score = 0.0
best_k = -1
for method in ["uniform", "distance"]:
for k in range(1, 11):
knn_clf = KNeighborsClassifier(n_neighbors = k)
knn_clf.fit(X_train, y_train)
knn_score = knn_clf.score(X_test, y_test)
if knn_score > best_score:
best_score = knn_score
best_k = k
best_method = method print("best_mrthod = ", best_method)
print("best_k = ", best_k)
print("best_score = ", best_score) # 4)试验搜索,获取最优产参数k、P(weights必须为distance)
%%time best_p = -1
best_score = 0.0
best_k = -1
for k in range(1, 11):
for p in range(1, 6):
knn_clf = KNeighborsClassifier(n_neighbors = k, weights = "distance", p = p)
knn_clf.fit(X_train, y_train)
knn_score = knn_clf.score(X_test, y_test)
if knn_score > best_score:
best_score = knn_score
best_k = k
best_p = p print("best_p = ", best_p)
print("best_k = ", best_k)
print("best_score = ", best_score)
5)其它
- ** 一般不同的超参数决定了不同的分类的准确率,它们之间呈连续变化;如果最终找到的最优的超参数为范围的边界值,意味着可能有更优的取值在边界的外面,所以要拓展搜索范围重新查询最优的超参数;
- 以上代码包含了调用scikit-learn库内的算法:导入模块、实例化、fit、调参(选取最优超参数)、预测
三、模型参数
# 模型参数:算法过程中学习的参数;
# kNN算法中没有模型参数,因为它没有模型;
# 线性回归算法和逻辑回归算法,包含有大量的模型参数;
# 什么是模型选择?
四、距离推导
- 欧拉距离:math.sqrt(np.sum((X1 - X2) ** 2)),向量X1与向量X2的欧拉距离;
- 曼哈顿距离:np.sum(|X1 - X2|),向量X1与向量X2的曼哈顿距离;
- 明科夫斯基距离:由欧拉距离和曼哈顿距离推到出;
- 下图从上至下:曼哈顿距离、欧拉距离、明科夫斯基距离;
- 在明科夫斯基距离中:
- 当P = 1,明科夫斯基距离 == 曼哈顿距离;
- 当P = 2,明科夫斯基距离 == 欧拉距离;
- 当P >= 3,对应的明科夫斯基距离为其它距离;
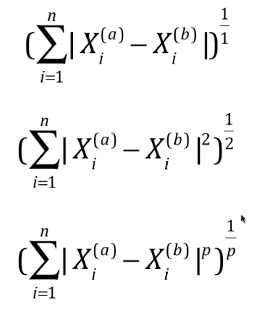
机器学习:调整kNN的超参数的更多相关文章
- 【笔记】KNN之超参数
超参数 超参数 很多时候,对于算法来说,关于这个传入的参数,传什么样的值是最好的? 这就涉及到了机器学习领域的超参数 超参数简单来说就是在我们运行机器学习之前用来指定的那个参数,就是在算法运行前需要决 ...
- 机器学习-kNN-寻找最好的超参数
一 .超参数和模型参数 超参数:在算法运行前需要决定的参数 模型参数:算法运行过程中学习的参数 - kNN算法没有模型参数- kNN算法中的k是典型的超参数 寻找好的超参数 领域知识 经验数值 实验搜 ...
- 【笔记】KNN之网格搜索与k近邻算法中更多超参数
网格搜索与k近邻算法中更多超参数 网格搜索与k近邻算法中更多超参数 网络搜索 前笔记中使用的for循环进行的网格搜索的方式,我们可以发现不同的超参数之间是存在一种依赖关系的,像是p这个超参数,只有在 ...
- 机器学习超参数优化算法-Hyperband
参考文献:Hyperband: Bandit-Based Configuration Evaluation for Hyperparameter Optimization I. 传统优化算法 机器学习 ...
- 机器学习算法中如何选取超参数:学习速率、正则项系数、minibatch size
机器学习算法中如何选取超参数:学习速率.正则项系数.minibatch size 本文是<Neural networks and deep learning>概览 中第三章的一部分,讲机器 ...
- Spark2.0机器学习系列之2:基于Pipeline、交叉验证、ParamMap的模型选择和超参数调优
Spark中的CrossValidation Spark中采用是k折交叉验证 (k-fold cross validation).举个例子,例如10折交叉验证(10-fold cross valida ...
- 机器学习:SVM(scikit-learn 中的 RBF、RBF 中的超参数 γ)
一.高斯核函数.高斯函数 μ:期望值,均值,样本平均数:(决定告诉函数中心轴的位置:x = μ) σ2:方差:(度量随机样本和平均值之间的偏离程度:, 为总体方差, 为变量, 为总体均值, 为总 ...
- TensorFlow从0到1之TensorFlow超参数及其调整(24)
正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值,甚至选择什么样的优化器优化权重和偏 ...
- TensorFlow实现超参数调整
TensorFlow实现超参数调整 正如你目前所看到的,神经网络的性能非常依赖超参数.因此,了解这些参数如何影响网络变得至关重要. 常见的超参数是学习率.正则化器.正则化系数.隐藏层的维数.初始权重值 ...
随机推荐
- Qt配置USBCAN通信
周立功为CAN通信提供了动态库:官方提供了很多相关动态库和lib等,如图 ,其中kerneldlls里还有很多动态库,还有一个配置文件.其实这么多的文件,如果我们只用到USBCAN2通信,只需要ker ...
- codeforces 439D 思维
题意:两个数组a,b,每次操作可将其中一个数组的一个数字加1或减1,求最小操作次数使得a数组的最小值大于等于b数组的最大值. 思路: 解法一:考虑最终状态,假设a为数组a中最小的数,b为数组b中最大的 ...
- ubuntu 的mysql 安装过程和无法远程的解决方案
ubuntu 的mysql 安装过程和无法远程的解决方案 安装完mysql-server启动mysqlroot@ubuntu:# /etc/init.d/mysql start (如果这个命令不可以, ...
- rollingstyle in log4net
https://stackoverflow.com/questions/734963/log4net-rollingfileappender-with-composite-rolling-style- ...
- hdoj1006--Tick and Tick
Problem Description The three hands of the clock are rotating every second and meeting each other ma ...
- 十大监视SQL Server性能的计数器
作为DBA,每个人都会用一系列计数器来监视SQLSERVER的运行环境,使用计数器,既可以衡量当前的数据库的性能,还可以和以前的性能进行对比.我们也可以一直以快速和简单的方法把计数器做了一张图表来 ...
- 关闭 Windows Defender
关闭 Windows Defender Win+R,输入 gpedit.msc 回车,打开组策略编辑器 展开[计算机设置]-[管理模板]-[Windows 组件]-[Windows Defender] ...
- hzau 1202 GCD(矩阵快速幂)
1202: GCD Time Limit: 1 Sec Memory Limit: 1280 MBSubmit: 201 Solved: 31[Submit][Status][Web Board] ...
- 51nod 1272 思维/线段树
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1272 1272 最大距离 题目来源: Codility 基准时间限制:1 ...
- Python中类的约束
如何在python中进行类的约束 使某些类必须有一些方法 1 python 的抽象类实现 === 约束性不高 Python是 解释性语言 from abc import ABCMeta from ab ...