分享知识-快乐自己:大数据(hadoop)环境搭建
大数据 hadoop 环境搭建:
-----------------------------------------------------------------
1):下载安装 hadoop(这里使用2.8版本:点我下载)
2):通过 (xftp 或 rz 命令)上传到指定目录下并解压到指定目录(根据自行要求进行选择存放位置):以下为小编存放目录
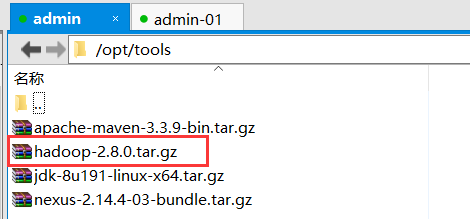

//解压到指定目录
tar -zxvf hadoop-2.8.0.tar.gz -C ../bigData/
3):配置 hadoop 环境变量
vim /etc/profile
export HADOOP_HOME=/opt/bigData/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

之后让文件生效:
source /etc/profile
4):hadoop 集群搭建:
1):进入 hadoop 的配置文件位置:
cd /opt/bigData/hadoop-2.8.0/etc/hadoop/
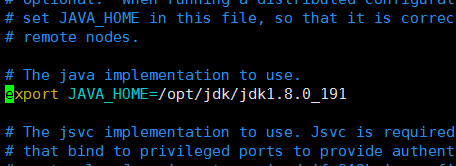
2):配置hadoop-env.sh文件
vim hadoop-env.sh
//在文件中加入[首先查看是否存在此节点,如果有可以直接修改](指定jdk绝对路径)
export JAVA_HOME=/opt/jdk/jdk1.8.0_191
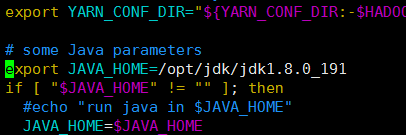
3):配置yarn-env.sh文件
vim yarn-env.sh
//在文件中加入[首先查看是否存在此节点,如果有可以直接修改](指定jdk绝对路径)
export JAVA_HOME=/opt/jdk/jdk1.8.0_191
4):配置slaves文件,增加slave主机名或者IP地址:
vim slaves
//在文件中加入(删除原有的localhost)
192.168.31.207
192.168.31.208

5):配置core-site.xml文件:
vim core-site.xml
//在文件中的configuration节点里加入
<property>
<name>fs.defaultFS</name>
<value>hdfs://admin:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigData/hadoop-2.8.0/tmp</value>
</property>
6):配置hdfs-site.xml文件
vim hdfs-site.xml
//在文件中的configuration节点里加入
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>admin:50090</value>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/bigData/hadoop-2.8.0/hdfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/bigData/hadoop-2.8.0/hdfs/data</value>
</property>
7):配置yarn-site.xml文件
vim yarn-site.xml
//在文件中的configuration节点里加入
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property>
<name>yarn.resourcemanager.address</name>
<value>admin:8032</value>
</property> <property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>admin:8030</value>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>admin:8031</value>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>admin:8033</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>admin:8088</value>
</property>
8):配置mapred-site.xml文件
mapred-site.xml.template 是存在的。
mapred-site.xml 不存在。
注意:先要copy一份。
cp mapred-site.xml.template mapred-site.xml
然后编辑:
vim mapred-site.xml
//新增以下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>admin:10020</value>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>admin:19888</value>
</property>
9):把配置好的hadoop文件复制到其他的子机器中
scp -r /opt/bigData/hadoop-2.8.0 root@admin-01:/opt/bigData/hadoop-2.8.0 scp -r /opt/bigData/hadoop-2.8.0 root@admin-02:/opt/bigData/hadoop-2.8.0
10):把配置好的/etc/profile复制到其他两个子机器中
scp /etc/profile root@admin-01:/etc/profile
scp /etc/profile root@admin-02:/etc/profile
之后在每个子机器中使用 source /etc/profile 使文件生效
11):在master 主机器中运行
hdfs namenode -format //注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。
//所以,格式NameNode时,一定要先删除生成的 name 和 data数据 和log日志,然后再格式化NameNode。
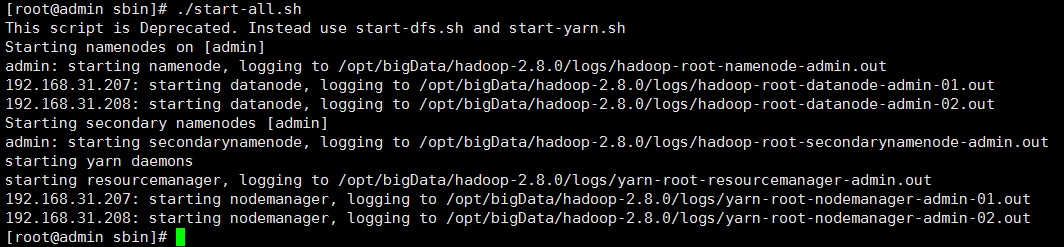
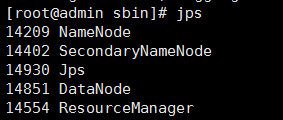
12):在master 主机器中启动hadoop环境:进入/opt/bigData/hadoop-2.8.0/sbin
./start-all.sh 启动hadoop集群 ./stop-all.sh 关闭hadoop集群 jps 查看当前已启动的服务
分享知识-快乐自己:大数据(hadoop)环境搭建的更多相关文章
- windows下大数据开发环境搭建(2)——Hadoop环境搭建
一.所需环境 ·Java 8 二.Hadoop下载 http://hadoop.apache.org/releases.html 三.配置环境变量 HADOOP_HOME: C:\hadoop- Pa ...
- 虚拟机CentOs的安装及大数据的环境搭建
大数据问题汇总 1.安装问题 1.安装步骤,详见文档<centos虚拟机安装指南> 2.vi编辑器使用问题,详见文档<linux常用命令.pd ...
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- windows下大数据开发环境搭建(1)——Java环境搭建
一.Java 8下载 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下载之后 ...
- windows下大数据开发环境搭建(3)——Scala环境搭建
一.所需环境 ·Java 8 二.下载Scala https://www.scala-lang.org/download/ 三.配置环境变量 SCALA_HOME: C:\scala Path: ...
- windows下大数据开发环境搭建(1)——Hadoop环境搭建
所需环境 jdk 8 Hadoop下载 http://hadoop.apache.org/releases.html 配置环境变量 HADOOP_HOME: C:\hadoop-2.7.7 Path: ...
- 大数据_zookeeper环境搭建中的几个坑
文章目录 [] Zookeeper简介 关于zk的介绍, zk的paxos算法, 网上已经有各位大神在写了, 本文主要写我在搭建过程中的几个极有可能遇到的坑. Zookeeper部署中的坑 坑之一 E ...
- 大数据学习环境搭建(CentOS6.9+Hadoop2.7.3+Hive1.2.1+Hbase1.3.1+Spark2.1.1)
node1 192.168.1.11 node2 192.168.1.12 node3 192.168.1.13 备注 NameNode Hadoop Y Y 高可用 DateNode Y Y Y R ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
随机推荐
- PlSql加入数据库链接
Oracle-OraDb10g_home2 -> 配置和移植工具 -> net Manager -> 本地 -> 服务命名 -> 加入(网络服务名自己命名,主机名:要 ...
- IEnumerable, IEnumerator接口
IEnumerable接口 // Exposes the enumerator, which supports a simple iteration over a non-generic collec ...
- 【Unity 3D】学习笔记四十二:粒子特效
粒子特效 粒子特效的原理是将若干粒子无规则的组合在一起.来模拟火焰,爆炸.水滴,雾气等效果. 要使用粒子特效首先要创建,在hierarchy视图中点击create--particle system就可 ...
- iOS 邓白氏编码的申请
http://www.cocoachina.com/ios/20161214/18225.html
- 【译】前端开发者都应知道的 jQuery 小技巧
回到顶部按钮 通过使用 jQuery 中的 animate 和 scrollTop 方法,你无需插件便可创建一个简单地回到顶部动画: // Back to top $('a.top').click(f ...
- CF451E Devu and Flowers(容斥)
CF451E Devu and Flowers(容斥) 题目大意 \(n\)种花每种\(f_i\)个,求选出\(s\)朵花的方案.不一定每种花都要选到. \(n\le 20\) 解法 利用可重组合的公 ...
- 基于SQLAIchemy的Flask目录
预先知识 flask的基本使用 快速搭建开发的目录,以后我们在用Flask开发项目的时候可以直接用这个目录,不需要再自己创建. flask-sqlalchemy flask-sqlalchemy相当于 ...
- Linux中rpm包管理器
包全名: 1.操作的包是没有安装的软件包时,使用全名,而且要注意路径 2.例如:jdk-8u131-linux-x64.rpm包名: 1.操作的是已经安装好的软件包,使用包名,是搜索/var/lib/ ...
- 常见数据挖掘算法的Map-Reduce策略(2)
接着上一篇文章常见算法的mapreduce案例(1)继续挖坑,本文涉及到算法的基本原理,文中会大概讲讲,但具体有关公式的推导还请大家去查阅相关的文献文章.下面涉及到的数据挖掘算法会有:L ...
- R语言数据管理(二):模式与类
最常用的4种数据类型是数值型(numeric).字符型(character)(字符串).日期型(Date)或POSIXct(基于日期的).逻辑型(logical)(TRUE或FALSE). 变量中 ...