分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装
python及scrapy框架依赖库的安装步骤:
第一步,python的安装
在Windows上安装Python
首先,根据你的Windows版本(64位还是32位)从Python的官方网站下载Python 3.5对应的64位安装程序或32位安装程序(网速慢请移步国内镜像)或者通过输入网址https://www.python.org/downloads/选择要下载的版本,然后,双击运行下载的EXE安装包:

如下图,并按照圈中区域进行设置,切记要勾选打钩的框,然后再点击Customize installation进入到下一步
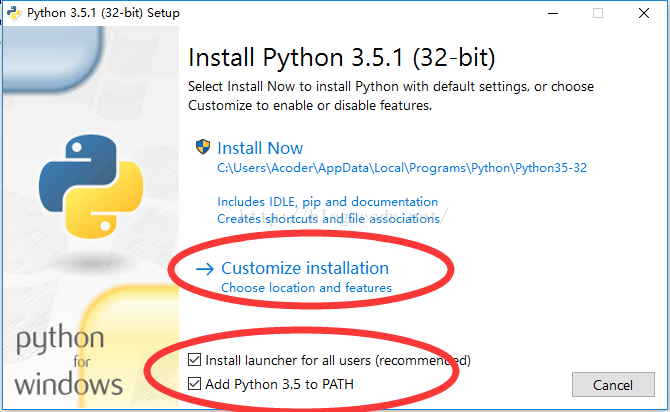
特别要注意勾上Add Python 3.5 to PATH,然后点“Install Now”即可完成安装。
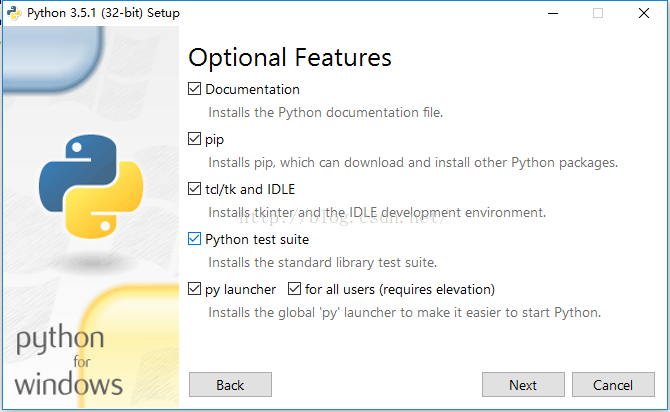
对于上图中,可以通过Browse进行自定义安装路径,也可以直接点击Install进行安装,点击install后便可以完成安装了。
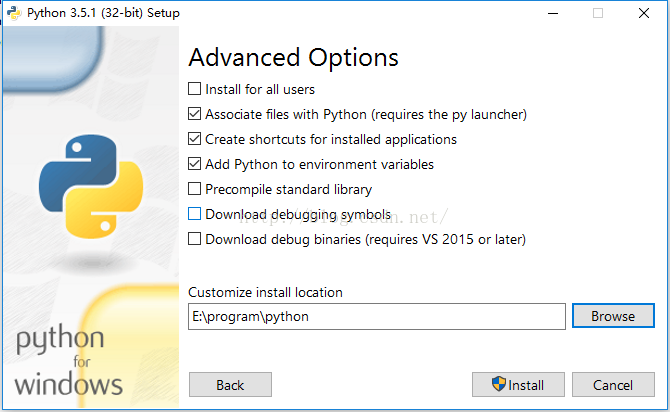
为了检查我们的python是否安装成功,我们运行Python进行检查:
安装成功后,打开命令提示符窗口,敲入python后,会出现两种情况:
情况一:

看到上面的画面,就说明Python安装成功!
情况二:得到一个错误:
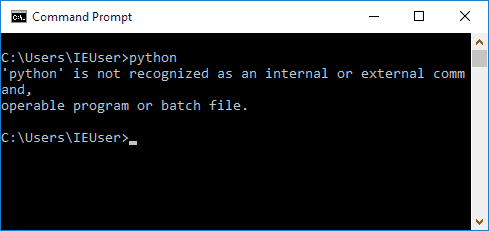
这是因为Windows会根据一个Path的环境变量设定的路径去查找python.exe,如果没找到,就会报错。如果在安装时漏掉了勾选Add Python 3.5 to PATH,那就要手动把python.exe所在的路径添加到Path中。
如果你不知道怎么修改环境变量,建议把Python安装程序重新运行一遍,务必记得勾上Add Python 3.5 to PATH。
以上过程是步骤能执行的前提,请确保python已经正常安装,否则无法进行第二步。
第二步,scrapy框架的建立前提依赖库的完整安装:
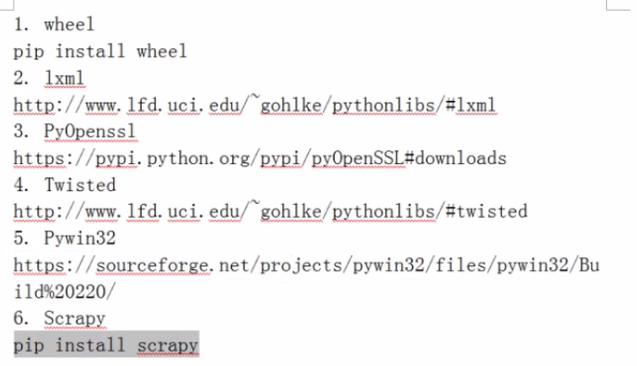
特别说明一下:
lxml,Twisted,PyOpenssl需要下载与安装的python相同版本的,否则会报错。
这里有一种方法可以查看当前本机安装的python的版本:
进入python(IDIE或cmd均可,此处以通用的cmd进行使用)。在cmd中,输入python进入python。
然后输入import pip;print(pip.pep425tags.get_supported()),界面上输出当前python的版本信息--划线部分,(此处提供一个python3.5的图例,其他的一样)

然后根据python版本选择依赖库的版本号。
另外此处提供一个完整安装lxmL的参考地址:https://jingyan.baidu.com/article/ad310e80feaac71849f49e98.html
操作步骤为:
(1)通过以上的链接(手动输入吧)去下载库到本地,例如存本地的绝对路径为url
(2)通过管理员启动命令提示符(这里很重要),然后通过pip install url 分别进行安装lxml,Twisted,PyOpenssl
(3)安装完成
注:windows平台需要依赖pywin32,Pywin32是一个.exe文件,需要在已经安装的python中的scripts中执行安装(next即可),这样会默认配置python。
这里需要说明一下就是上述的安装是在没有使用虚拟环境的前提下进行的,这里附上使用虚拟环境(虚拟环境包管理)后的安装步骤:
第一步:包管理的安装
pip install virtualenvwrapper-win
pip install virtualenv
默认创建的虚拟环境位于C:\Users\username\envs,但是我们有时需要把项目环境存储到其他盘,所以我们可以通过环境变量 WORKON_HOME来定制实现虚拟环境的存储位置。
通过计算机-->属性-->高级系统设置-->环境变量-->在系统变量中新建“变量名”:WORKON_HOME,变量值:“你自定义的路径”。
使用workon可以查看虚拟环境包
第二步:创建一个虚拟环境
mkvirtualenv testscrapy
虚拟环境创建好之后会自动进入到该虚拟环境下
使用deactivate可以退出该虚拟环境,使用workon testscrapy可以进入到虚拟环境中
第三步:scrapy框架的安装 使用豆瓣的镜像
pip install -i https://pypi.douban.com/simple scrapy
对于该步骤有可能会安装出错,原因为一些第三方包的缺失,
这里解决办法为在https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml中下载与我们python对应版本的包,指定下载到某一个目录下,然后在该目录下
打开虚拟环境(指的是路径必须是从当前文件所在盘开始,例如包下载到了D盘,cmd的根目录需要从D开始,如下图):

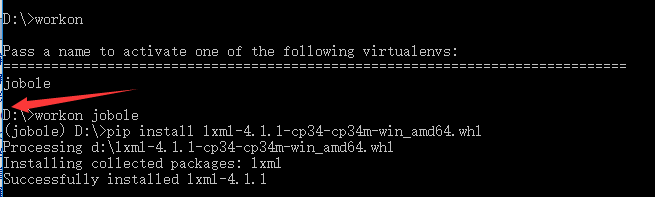
并在该虚拟环境下使用pip install xx 命令来安装所需的第三方的包(对于安装的包需要名称加扩展名)。例如安装lxml
pip install lxml-4.1.-cp34-cp34m-win_amd64.whl
以上步骤成功走完后,我们就可以开心愉快的玩耍了----接下来开启我们scrapy框架之旅
详细我们可以参考:https://www.cnblogs.com/jiuyang/p/7815126.html
分布式爬虫搭建系列 之一------python安装及以及虚拟环境的配置及scrapy依赖库的安装的更多相关文章
- 分布式爬虫搭建系列 之二-----神器PyCharm的安装
这里我们使用PyCharm作为开发工具,以下过程摘抄于:http://blog.csdn.net/qq_29883591/article/details/52664478 作者:陌上行走 Pytho ...
- 分布式爬虫搭建系列 之三---scrapy框架初用
第一,scrapy框架的安装 通过命令提示符进行安装(如果没有安装的话) pip install Scrapy 如果需要卸载的话使用命令为: pip uninstall Scrapy 第二,scrap ...
- 分布式爬虫搭建系列 之四---scrapy分布式框架
带录入SAFCDS
- linux7 安装 zlib依赖库 与安装python 3.6
Linux 安装zlib依赖库 进入src: cd /usr/local/src 下载zlib库: wget http://www.zlib.net/zlib-1.2.11.tar.gz 解压下载的t ...
- 远程安装实施时,如何配置远程服务器的本地 yum 安装源
配置本地 yum 安装源 overview 1.使用 ftp 将OracleLinux-R5-U8-Server-x86_64-dvd.iso 上传到 /home 目录下.再使用 mount 命令挂载 ...
- yum install 安装 下载好的rpm包 会并依赖包一起安装 zoom电话会议的安装
[root@ok-T Downloads]# rpm -ivh zoom_x86_64.rpm error: Failed dependencies: libxcb-image.so.()(64bit ...
- 使用scrapy-redis 搭建分布式爬虫环境
scrapy-redis 简介 scrapy-redis 是 scrapy 框架基于 redis 数据库的组件,用于 scraoy 项目的分布式开发和部署. 有如下特征: 分布式爬取: 你可以启动多个 ...
- 跟繁琐的命令行说拜拜!Gerapy分布式爬虫管理框架来袭!
背景 用 Python 做过爬虫的小伙伴可能接触过 Scrapy,GitHub:https://github.com/scrapy/scrapy.Scrapy 的确是一个非常强大的爬虫框架,爬取效率高 ...
- gerapy的初步使用(管理分布式爬虫)
一.简介与安装 Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy.Scrapyd.Scrapyd-Client.Scrapy-Redis.Scrapyd-API.Sc ...
随机推荐
- 【转】Android PullToRefresh (ListView GridView 下拉刷新) 使用详解
最近项目用到下拉刷新,上来加载更多,这里对PullToRefresh这控件进行了解和使用. 以下内容转载自:http://blog.csdn.net/lmj623565791/article/deta ...
- http 常见的错误码
翻译自:https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html 常见错误码 一.信息 1XX (Information 1xx) ——这一类的状 ...
- BASE64Encoded() 方法报错说方法未定义
代码: String enParams = new BASE64Encoder().encode(strParams.getBytes()); 出错,显示方法未定义 解决方法:项目右键——>pr ...
- Spring Cloud Ribbon实现客户端负载均衡
1.构建microservice-consumer-movie-ribbon项目,在pom.xml中引入ribbon依赖 在引入Eureka依赖的时候,默认里面含有ribbon依赖 2.添加@Load ...
- 集成 ActiveMQ 到应用服务器
本章知识点 集成 ActiveMQ 和 Apache Tomcat 集成 ActiveMQ 和 Jetty 集成 ActiveMQ 和 Apache Geronimo 集成 ActiveMQ 和 JB ...
- Eclipse里面新建servlet 是否需要配置web.xml
在新建的时候可选时候映射,如果选择了映射,那么就会在servle开头的地方有一行@servlet(""),这就完成了映射.注释掉这行就需要在web.xml中设置了
- msdn - Developer Library(包括wpf)重要程度——5星*****
https://msdn.microsoft.com/zh-cn/library/ms754242(v=vs.110).aspx https://msdn.microsoft.com/zh-cn/li ...
- MySQL 大数据量修改表结构问题
前言: 在系统正常运作一定时间后,随着市场.产品汪的需求不断变更,比较大的一些表结构面临不得不增加字段的方式来扩充满足业务需求: 而 MySQL 在体量上了千万.亿级别数据的时候,Alter Tab ...
- 初学者的Node.js学习历程
废话篇: 对于我这个新手的不能再白菜的人来说,nodejs的大名都有耳闻,所以说他是一项不可不克服的技能也是可以说的.但是之前没有搞清楚的情况之下胡乱的猜测,是的我对node.js没有一个具体的概念的 ...
- Rainmeter如何打开控制面板的小程序
控制面板功能都是通过访问cpl文件来关联它们的,假设你的系统盘在C盘,那么它们的本地在C:\Windows\System32\ Rainmeter通过使用这个应用程序C:\Windows\System ...