大数据笔记(五)——HDFS的高级特性
一.HDFS的回收站: recyclebin
1.HDFS的回收站默认是关闭的
2.启用回收站:去core-site.xml配置
路径:/root/training/hadoop-2.7.3/etc/hadoop
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3.配置完成后删除目录 hdfs dfs -rmr /folder1
日志:
18/02/26 23:08:03 INFO fs.TrashPolicyDefault: Namenode trash configu ration: Deletion interval = 1440 minutes, Emptier interval = 0 minut es.
Moved: 'hdfs://bigdata11:9000/folder1' to trash at: hdfs://bigdata11 :9000/user/root/.Trash/Current
本质:删除数据的时候,实际是一个ctrl+x操作
4.查看回收站:hdfs dfs -lsr /user/root/.Trash/Current

5.恢复:实际就是拷贝 hdfs dfs -cp /user/root/.Trash/Current/input/data.txt /input
6.清空:hdfs dfs -expunge
二.HDFS的快照 snapshot:备份
1.默认:HDFS的快照是禁用的
2.开启快照第一步:管理员开启某个目录的快照功能
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
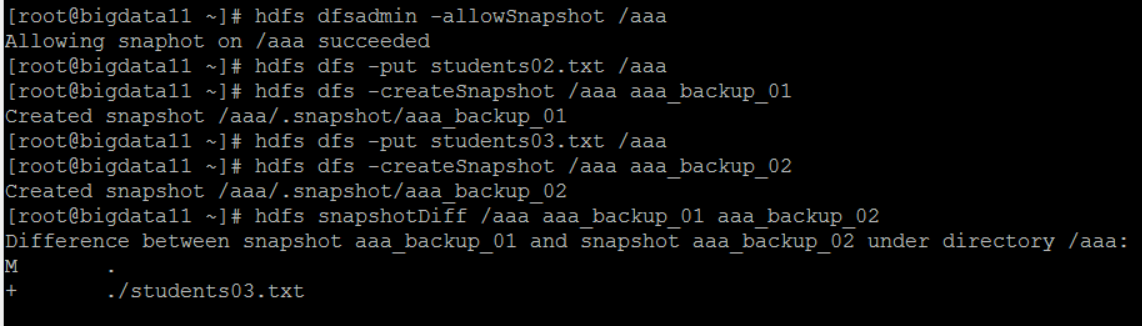
hdfs dfsadmin -allowSnapshot /aaa
3.第二步:使用HDFS的操作命令,创建快照
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
hdfs dfs -createSnapshot /aaa aaa_backup_01
日志:Created snapshot /aaa/.snapshot/aaa_backup_01
本质:将数据拷贝一份到当前目录的一个隐藏目录下
4.对比快照:hdfs snapshotDiff /aaa aaa_backup_01 aaa_backup_02
三.HDFS的配额:quota
1.名称配额: 规定某个目录下,存放文件(目录)的个数
实际的个数:N-1个
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
hdfs dfs -mkdir /quota1
设置该目录的名称配额:3
hdfs dfsadmin -setQuota 3 /quota1
当我们放第三个文件的时候
hdfs dfs -put data.txt /quota1
put: The NameSpace quota (directories and files) of directory /quota1 is exceeded: quota=3 file count=4
2.空间配额: 规定某个目录下,文件的大小
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>]
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
hdfs dfs -mkdir /quota2
设置该目录的空间配额是:10M
hdfs dfsadmin -setSpaceQuota 10M /quota2
正确的做法:hdfs dfsadmin -setSpaceQuota 130M /quota2
放一个小于10M的文件,会出错
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.protocol.DSQuotaExceededException): The DiskSpace quota of /quota2 is exceeded: quota = 10485760 B = 10 MB but diskspace consumed = 134217728 B = 128 MB
注意:尽管数据不到128M,但是占用的数据块依然是128M
切记:当设置空间配额的时候,这个值不能小于128M
四.HDFS的权限
drwxr-xr-x - root supergroup 0 2018-02-26 23:30 /aaa
权限 用户名 组名 文件目录
参考命令链接:http://blog.csdn.net/feeltouch/article/details/46538277
五.HDFS的安全模式
一种保护机制,用于保护数据块的安全性。
大数据笔记(五)——HDFS的高级特性的更多相关文章
- C#可扩展编程之MEF学习笔记(五):MEF高级进阶
好久没有写博客了,今天抽空继续写MEF系列的文章.有园友提出这种系列的文章要做个目录,看起来方便,所以就抽空做了一个,放到每篇文章的最后. 前面四篇讲了MEF的基础知识,学完了前四篇,MEF中比较常用 ...
- 大数据笔记(二十六)——Scala语言的高级特性
===================== Scala语言的高级特性 ========================一.Scala的集合 1.可变集合mutable 不可变集合immutable / ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据入门第六天——HDFS详解
一.概述 1.HDFS中的角色 Block数据: HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
随机推荐
- Dubbo原理学习
Dubbo源码及原理学习 阿里中间件团队博客 Dubbo官网 Dubbo源码解析 Dubbo源码解析-掘金 Dubbo源码解析-赵计刚 Dubbo系列 源码总结+最近感悟
- [转帖]探秘华为(一):华为和H3C(华三)的爱恨情仇史!
探秘华为(一):华为和H3C(华三)的爱恨情仇史! https://baijiahao.baidu.com/s?id=1620703498823290828&wfr=spider&fo ...
- Thinkphp3.2 Redis支持REDIS_AUTH验证
原有的Redis类在Library/Think/Cache/Driver/中 换成下面的: <?php // +----------------------------------------- ...
- 管道(Pipe)----计算机进程间通信
参至他人博客:https://blog.csdn.net/u011583316/article/details/83419805
- 一、JVM — Java内存区域
Java 内存区域详解 写在前面 (常见面试题) 基本问题 拓展问题 一 概述 二 运行时数据区域 2.1 程序计数器 2.2 Java 虚拟机栈 2.3 本地方法栈 2.4 堆 2.5 方法区 2. ...
- css禁止鼠标双击选中文字
div{ -moz-user-select:none;/*火狐*/ -webkit-user-select:none;/*webkit浏览器*/ -ms-user-select:none;/*IE10 ...
- 广播即时通信src和des
package 第十二章; import java.io.IOException; import java.net.DatagramPacket; import java.net.InetAddres ...
- JavaScript是如何工作的:引擎,运行时间以及调用栈的概述
JavaScript是如何工作的:引擎,运行时以及调用栈的概述 原文:How JavaScript works: an overview of the engine, the runtime, and ...
- java 技术分享
http://www.ccblog.cn/99.htm http://www.ccblog.cn/100.htm http://www.ccblog.cn/101.htm http://www.ccb ...
- goaccess实现nginx实现日志可视化
一:goaccess模块 goaccess模块是将nginx的日志定向到goaccess模块里实现,原理很简单,只要将文件定向到那里就可以,goaccess是已经集成好显示数据的一个页面,非常的美观和 ...