大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation。
首先,我们先要来个直观的印象,这是你以为的Hadoop集群:
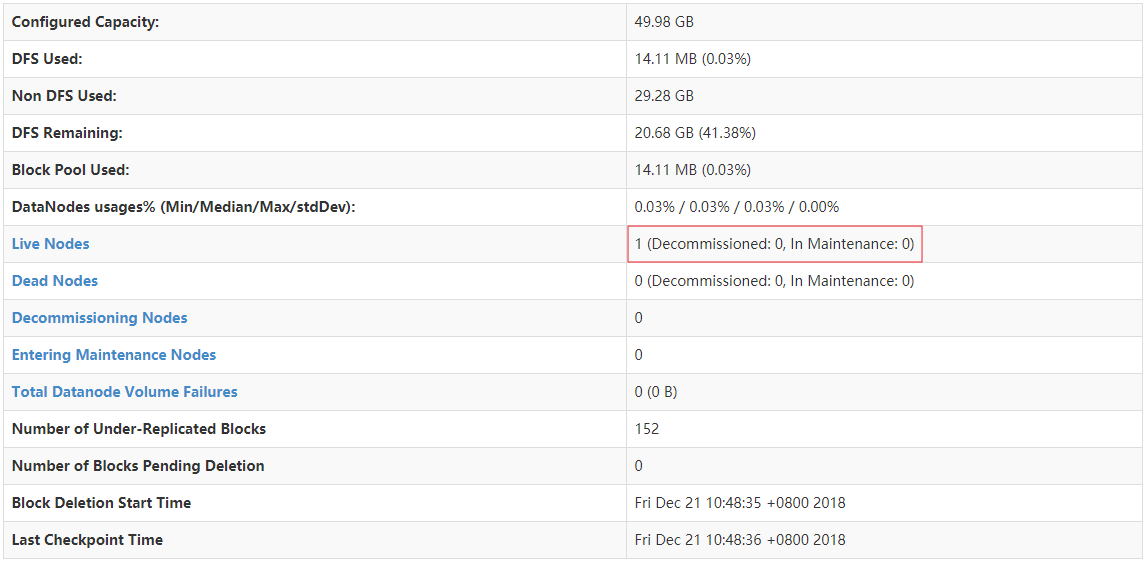
这是真实世界的Hadoop集群:
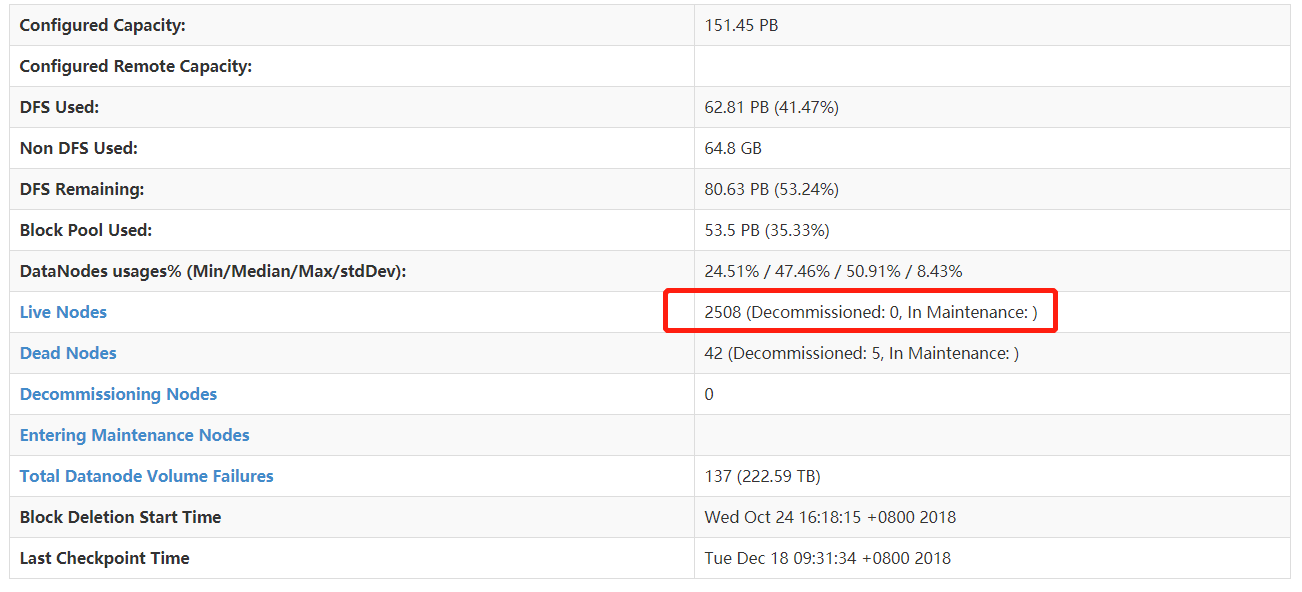
因为,NameNode(下称NN)中的元数据记录了各个数据块的存储位置。
所以,元数据的大小,与数据块的数量成正比。
当集群存储的数据规模到达一定程度时,NN将成为整套系统中的瓶颈所在。NN的存储能力是有限的,不管是磁盘存储还是内存存储。
为了解决这个问题,HDFS中引入了联邦(Federation)的概念。
联邦:由若干具有国家性质的行政区域(有国、邦、州等不同名称)联合而成的统一国家,各行政区域有自己的宪法、立法机关和政府,联邦也有统一的宪法、立法机关和政府。—— 维基百科
体现在HDFS上,就是“集权”到“分权”的过程,引入了多对NN(Active NN + Standby NN这里称为一对),让他们各自实现“区域自治”。
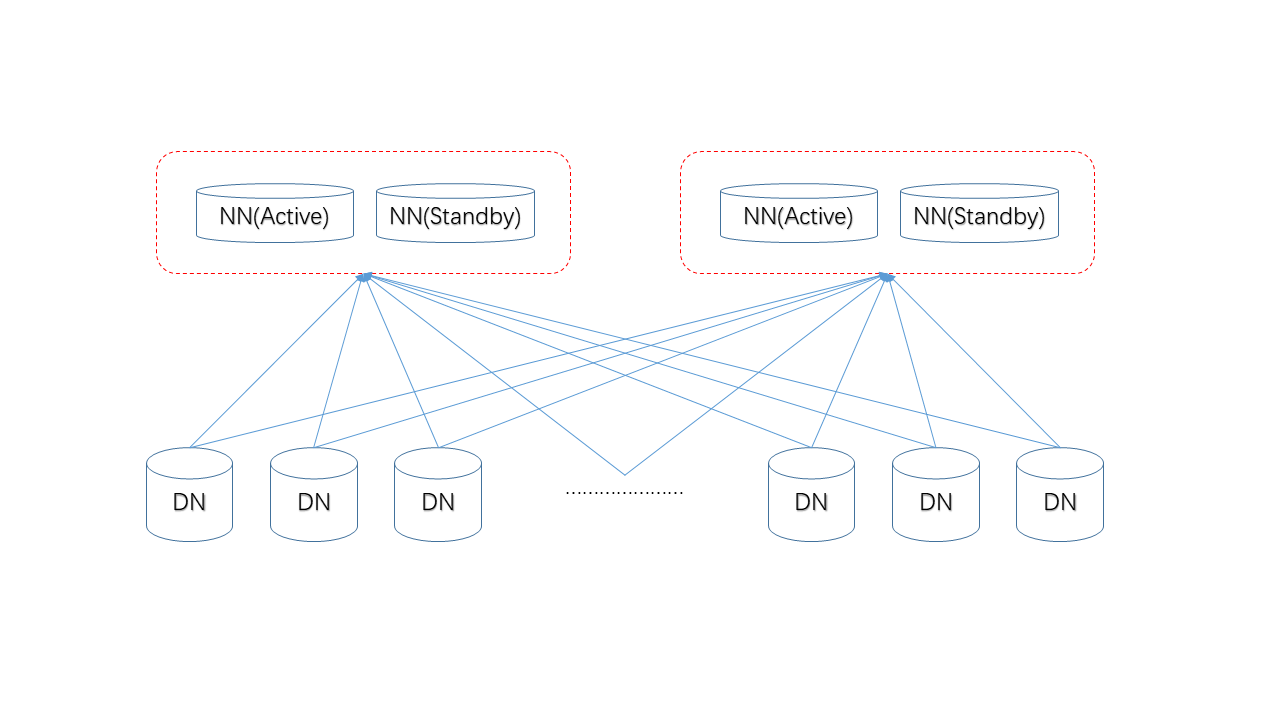
物理上是这样的,所有的DN(DataNode)需向所有的NN汇报状态。
逻辑上是这样的,一对NN只负责管理属于自己名称空间下的目录。
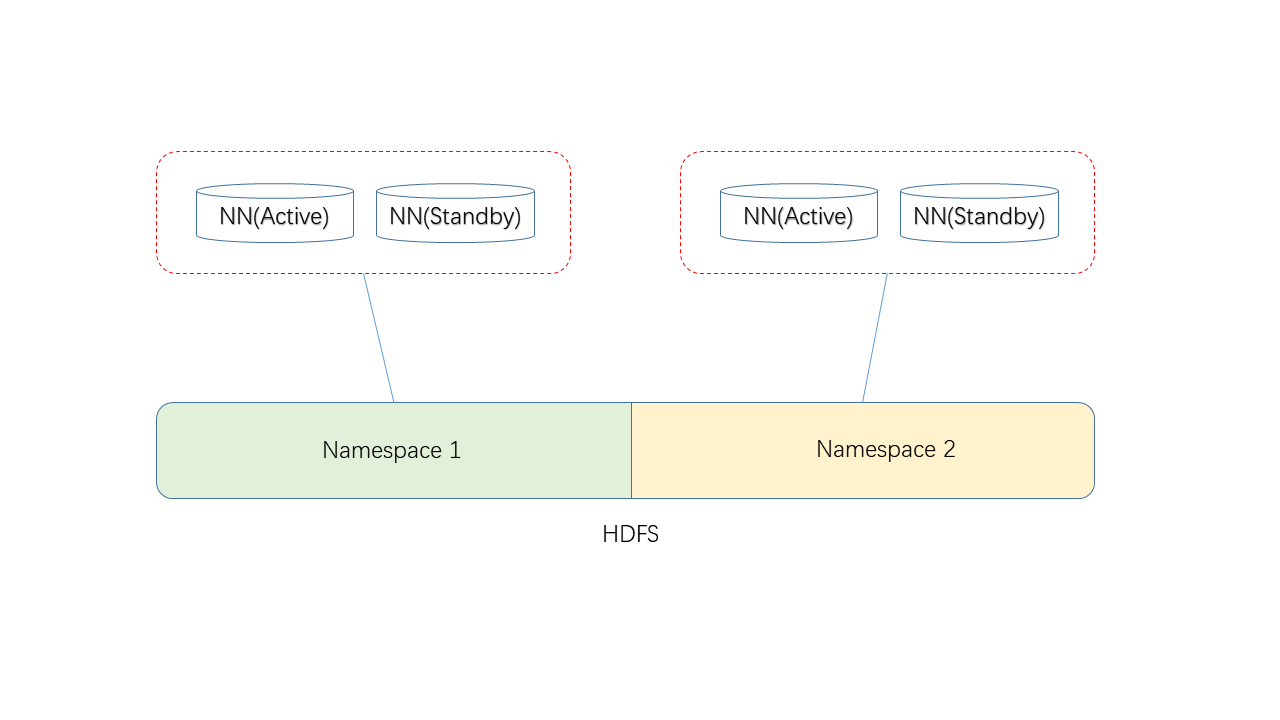
因此,并不是某对NN管理某些DN,而是对HDFS进行划分,即逻辑划分。
上面这样规模的集群,有可能划分出数十个“邦”,各自管理“邦”内的数据,这样就基本实现了NN的水平扩展,同时,还对提高整个系统的可用性有帮助,毕竟,某一对NN宕机,只会对系统产生局部影响。
注:HDFS联邦并不强制要求各NN都做HA,只是通常是这样配置的,即每个“邦”的NN都是成对出现的。
好了,关于HDFS的所有介绍就先到这,那些没讲到的,都不重要(误),下期我们将开始介绍新的内容:MapReduce的基本概念。Cheers!
公众号 程序员杂书馆,大数据内容持续更新中,欢迎关注!

大数据小白系列——HDFS(4)的更多相关文章
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据小白系列——MR(1)
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具. 来了一份大数据,我们写了一个程序准备分析它,需要怎么做? 老式的处理方法不行,数据量太大时,所需的时间 ...
- 大数据小白系列 —— MapReduce流程的深入说明
上一期我们介绍了MR的基本流程与概念,本期稍微深入了解一下这个流程,尤其是比较重要但相对较少被提及的Shuffling过程. Mapping 上期我们说过,每一个mapper进程接收并处理一块数据,这 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
随机推荐
- Es6对象的扩展和Class类的基础知识笔记
/*---------------------对象的扩展---------------------*/ //属性简写 ,属性名为变量名, 属性值为变量的值 export default functio ...
- python(4): regular expression正则表达式/re库/爬虫基础
python 获取网络数据也很方便 抓取 requests 第三方库适合做中小型网络爬虫的开发, 大型的爬虫需要用到 scrapy 框架 解析 BeautifulSoup 库, re 模块 (一) r ...
- Java将文件中的内容转换为sql语句(和并发定时读取文件)
数据文件内容data.txt {USER_TYPE=1,CREATE_USER=ZHANG,UPDATE_USER=li,OPER_NUM=D001,SRC=2,UPDATE_TIME=2018-11 ...
- Oracle unusable index 与unvisible index
1 可见性 索引的可见性(visibility)指的是该索引是否对CBO优化器可见,即CBO优化器在生成执行计划的时候是否考虑该索引,可以看作是索引的一个属性.如果一个索引可见性属性为:invisib ...
- RFC2119:RFC协议动词含义
协议地址:http://www.ietf.org/rfc/rfc2119.txt MUST 必须的.通过它描述的对象,是强制要求的.它与REQUIRED和SHALL含义相同. MUST NOT 不允许 ...
- 记录mysql正在执行的SQL语句
show variables like "general_log%"; SET GLOBAL general_log = 'ON';SET GLOBAL general_log = ...
- Spring data JPA中使用Specifications动态构建查询
有时我们在查询某个实体的时候,给定的条件是不固定的,这是我们就需要动态 构建相应的查询语句,在JPA2.0中我们可以通过Criteria接口查询,JPA criteria查询.相比JPQL,其优势是类 ...
- alpha冲刺8/10
目录 摘要 团队部分 个人部分 摘要 队名:小白吃 组长博客:hjj 作业博客:冲刺倒计时之8 团队部分 后敬甲(组长) 过去两天完成了哪些任务 首页重新设计 课程时间线确定 答辩准备 接下来的计划 ...
- 【AtCoder】ARC073
ARC 073 C - Sentou 直接线段覆盖即可 #include <bits/stdc++.h> #define fi first #define se second #defin ...
- 一起学Hive——总结复制Hive表结构和数据的方法
在使用Hive的过程中,复制表结构和数据是很常用的操作,本文介绍两种复制表结构和数据的方法. 1.复制非分区表表结构和数据 Hive集群中原本有一张bigdata17_old表,通过下面的SQL语句可 ...