吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归
import numpy as np
import matplotlib.pyplot as plt from sklearn import datasets, linear_model
from sklearn.model_selection import train_test_split def load_data():
diabetes = datasets.load_diabetes()
return train_test_split(diabetes.data,diabetes.target,test_size=0.25,random_state=0) #Lasso回归
def test_Lasso(*data):
X_train,X_test,y_train,y_test=data
regr = linear_model.Lasso()
regr.fit(X_train, y_train)
print('Coefficients:%s, intercept %.2f'%(regr.coef_,regr.intercept_))
print("Residual sum of squares: %.2f"% np.mean((regr.predict(X_test) - y_test) ** 2))
print('Score: %.2f' % regr.score(X_test, y_test)) # 产生用于回归问题的数据集
X_train,X_test,y_train,y_test=load_data()
# 调用 test_Lasso
test_Lasso(X_train,X_test,y_train,y_test) def test_Lasso_alpha(*data):
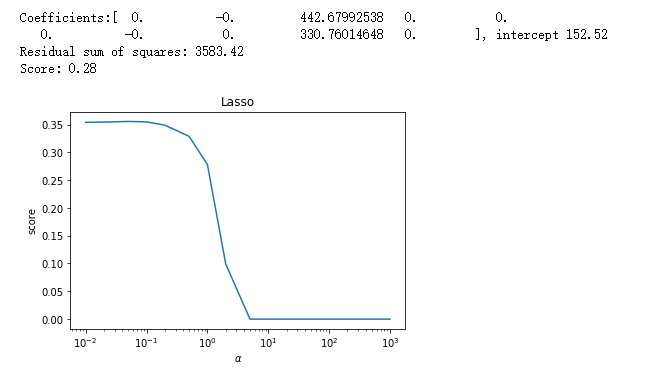
X_train,X_test,y_train,y_test=data
alphas=[0.01,0.02,0.05,0.1,0.2,0.5,1,2,5,10,20,50,100,200,500,1000]
scores=[]
for i,alpha in enumerate(alphas):
regr = linear_model.Lasso(alpha=alpha)
regr.fit(X_train, y_train)
scores.append(regr.score(X_test, y_test))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(alphas,scores)
ax.set_xlabel(r"$\alpha$")
ax.set_ylabel(r"score")
ax.set_xscale('log')
ax.set_title("Lasso")
plt.show() # 调用 test_Lasso_alpha
test_Lasso_alpha(X_train,X_test,y_train,y_test)
吴裕雄--天生自然 人工智能机器学习实战代码:LASSO回归的更多相关文章
- 吴裕雄--天生自然 人工智能机器学习实战代码:线性判断分析LINEARDISCRIMINANTANALYSIS
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然 人工智能机器学习实战代码:ELASTICNET回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据 import matplotlib import matplotlib.pyplot as plt from numpy import * xcord0 = [] ycord0 ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
随机推荐
- java 连接mysql 示例
import java.sql.*; public class Main { // MySQL 8.0 以下版本 - JDBC 驱动名及数据库 URL static final String JDBC ...
- 实体机安装Ubuntu系统
今天windows突然蓝屏了,索性安装个 Ubuntu 吧,这次就总结一下实体机安装 Ubuntu 的具体步骤 note: 本人实体机为笔记本 型号为:小米pro U盘为金士顿:8G 安装系统:Ubu ...
- jenkins-master-slave节点配置总结
一.jenkins分布式简单介绍 Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能 二.jenk ...
- 【iOS入门】UITableView加载图片
学习带图片的列表 官方 LazyTableImages demo http://download.csdn.net/detail/jlyidianyuan/5726749 分析源码是学习的好方法. ...
- PyTorch基础——使用卷积神经网络识别手写数字
一.介绍 实验内容 内容包括用 PyTorch 来实现一个卷积神经网络,从而实现手写数字识别任务. 除此之外,还对卷积神经网络的卷积核.特征图等进行了分析,引出了过滤器的概念,并简单示了卷积神经网络的 ...
- Python - 文件和目录
# -*- coding: utf-8 -*- import os print(os.name) # 获取操作系统类型 # print(os.uname()) # 获取操作系统的详细信息,Win不支持 ...
- java多线程高并发的学习
1. 计算机系统 使用高速缓存来作为内存与处理器之间的缓冲,将运算需要用到的数据复制到缓存中,让计算能快速进行:当运算结束后再从缓存同步回内存之中,这样处理器就无需等待缓慢的内存读写了. 缓 ...
- Codeforces Round #600 (Div. 2)E F
题:https://codeforces.com/contest/1253/problem/E 题意:给定n个信号源,俩个参数x和s,x代表这个信号源的位置,s代表这个信号源的波及长度,即这个信号源可 ...
- 使用js/jquery动态提交表单数据到搜索引擎或者接口
现在一般需要用jquery等方式动态提交到某个接口,比如通过iframe <iframe id="mainIframe" name="mainIframe" ...
- “全隐藏式3D摄像头”亮相,FindX如何将设计与体验融为一体
北京时间6月20日,OPPO在卢浮宫发布暌违四年之久的Find旗舰系列新手机--Find X.在Find X背后,我认为其设计值得深思.尤其是Find X为突破传统设计束缚,首创双轨潜望结构有着重要启 ...