入门大数据---Hive是什么?
这篇文章主要介绍Hive的概念。
简介:
Hive中文名叫数据仓库管理系统,之前我们操作MapReduce必须通过编写代码或者通过特殊命令来实现,有了Hive我们通过常用的SQL语句就能操作MapReduce集群了。是不是感觉很方便。 这也是方便不懂MapReduce原理,懂SQL语句的人用的。
有好几个公司都推出了自己的Hive,其中比较出名的是Apache Hive,CDH Hive,HDP Hive和MapR Hive,大家刚开始学习大部分都用的Apache Hive,但是公司中却很少使用它,因为它的版本太杂乱,里面的BUG也很多,没法快速投入生产,所以大部分都采用第三方Hive,也就是CDH或MapR Hive,这些Hive由专门组织开发,调理清晰,BUG较少,当然人家也是靠这个服务赚钱啦。博主因为也是学习阶段,所以先介绍Apache Hive了,后续会介绍和搭建其它版本的。
结构:
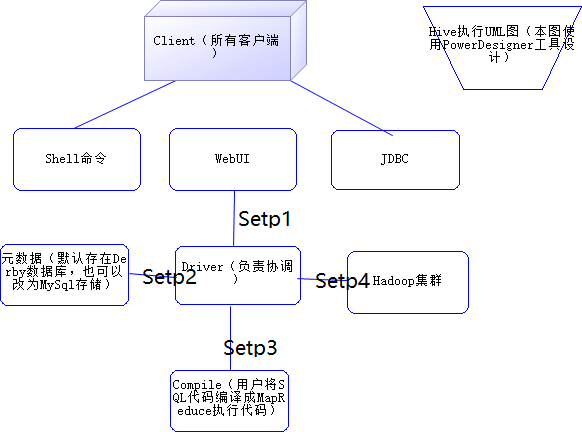
Setp1: 用户通过Shell命令,WebUI或JDBC调用Driver
Setp2: Driver会先去数据库查询有没有这个表的信息,没有的话直接返回,有的话进行第三步
Setp3:将SQL转行为MapReduce执行命令
Setp4:分发到MapReduce去执行
关于 Hive SQL 的详细执行流程可以参考美团技术团队的文章:Hive SQL 的编译过程
Hive数据类型:
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数 SMALLINT—2 字节的有符号整数 INT—4 字节的有符号整数 BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型 DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列 VARCHAR—具有最大长度限制的字符序列 CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
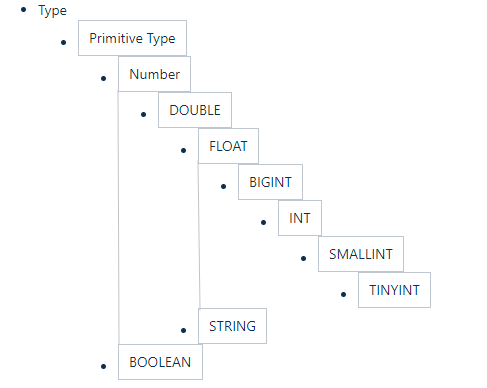
隐式转换:
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。
复杂类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用 名称.字段名 方式进行访问 |
STRUCT ('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用 名称[key] 的方式访问对应的值 |
map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用 名称[index] 访问对应的值 |
ARRAY('a', 'b', 'c', 'd') |
示例:
如下给出一个基本数据类型和复杂数据类型的使用示例:
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, --学科
score MAP<STRING,FLOAT>, --各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> --家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
内容格式:
当数据存储在文本文件中,必须按照一定格式区别行和列,如使用逗号作为分隔符的 CSV 文件 (Comma-Separated Values) 或者使用制表符作为分隔值的 TSV 文件 (Tab-Separated Values)。但此时也存在一个缺点,就是正常的文件内容中也可能出现逗号或者制表符。
所以 Hive 默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在文件中。Hive 默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以可以使用换行符来分割记录 |
| ^A (Ctrl+A) | 分割字段 (列),在 CREATE TABLE 语句中也可以使用八进制编码 \001 来表示 |
| ^B | 用于分割 ARRAY 或者 STRUCT 中的元素,或者用于 MAP 中键值对之间的分割, 在 CREATE TABLE 语句中也可以使用八进制编码 \002 表示 |
| ^C | 用于 MAP 中键和值之间的分割,在 CREATE TABLE 语句中也可以使用八进制编码 \003 表示 |
使用示例如下:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
存储格式
-支持的存储格式
| 格式 | 说明 |
|---|---|
| TextFile | 存储为纯文本文件。 这是 Hive 默认的文件存储格式。这种存储方式数据不做压缩,磁盘开销大,数据解析开销大。 |
| SequenceFile | SequenceFile 是 Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用 Hadoop 的标准的 Writable 接口实现序列化和反序列化。它与 Hadoop API 中的 MapFile 是互相兼容的。Hive 中的 SequenceFile 继承自 Hadoop API 的 SequenceFile,不过它的 key 为空,使用 value 存放实际的值,这样是为了避免 MR 在运行 map 阶段进行额外的排序操作。 |
| RCFile | RCFile 文件格式是 FaceBook 开源的一种 Hive 的文件存储格式,首先将表分为几个行组,对每个行组内的数据按列存储,每一列的数据都是分开存储。 |
| ORC Files | ORC 是在一定程度上扩展了 RCFile,是对 RCFile 的优化。 |
| Avro Files | Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro 提供的机制使动态语言可以方便地处理 Avro 数据。 |
| Parquet | Parquet 是基于 Dremel 的数据模型和算法实现的,面向分析型业务的列式存储格式。它通过按列进行高效压缩和特殊的编码技术,从而在降低存储空间的同时提高了 IO 效率。 |
-指定存储格式
通常在创建表的时候使用 STORED AS 参数指定:
CREATE TABLE page_view(viewTime INT, userid BIGINT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
STORED AS SEQUENCEFILE;
各个存储文件类型指定方式如下:
STORED AS TEXTFILE
STORED AS SEQUENCEFILE
STORED AS ORC
STORED AS PARQUET
STORED AS AVRO
STORED AS RCFILE
参考资料:
入门大数据---Hive是什么?的更多相关文章
- 入门大数据---Hive计算引擎Tez简介和使用
一.前言 Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎.至于为什么提高了计算速度,可以参考下图: 用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Re ...
- 入门大数据---Hive数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载. 1.1 员工表 -- 建表语句 ...
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Hive常用DDL操作
一.Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SC ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive视图和索引
一.视图 1.1 简介 Hive 中的视图和 RDBMS 中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条 SELECT 语句的结果集.视图是纯粹的逻辑对象,没有关联的存储 (Hive 3.0 ...
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
- [Hadoop大数据]——Hive初识
Hive出现的背景 Hadoop提供了大数据的通用解决方案,比如存储提供了Hdfs,计算提供了MapReduce思想.但是想要写出MapReduce算法还是比较繁琐的,对于开发者来说,需要了解底层的h ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
随机推荐
- 【已解决】Ubuntu U盘启动出现“Failed to load ldlinux.c32”问题
利用UltraISO制作了Ubuntu的U盘启动,在USB启动时出现了 Failed to load ldlinux.c32 Boot failed: please change disks and ...
- JSON.parse() 的实现
目录 1. JSON.parse() 2. 前置知识 2.1 JSON格式中的数据类型 2.2 转义字符的处理 2.2 判断对象是否相等 2.3 寻找匹配的字符串 2.4 基础的递归思想 3. 实现流 ...
- CSS3新增伪类有那些?
p:first-of-type 选择属于其父元素的首个元素 p:last-of-type 选择属于其父元素的最后元素 p:only-of-type 选择属于其父元素唯一的元素 p:only-child ...
- (Java实现) 蓝桥杯 国赛 重复模式
标题:重复模式 作为 drd 的好朋友,技术男 atm 在 drd 生日时送给他一个超长字符串 S .atm 要 drd 在其中找出一个最长的字符串 T ,使得 T 在 S 中至少出现了两次,而他想说 ...
- Java实现 LeetCode 120 三角形最小路径和
120. 三角形最小路径和 给定一个三角形,找出自顶向下的最小路径和.每一步只能移动到下一行中相邻的结点上. 例如,给定三角形: [ [2], [3,4], [6,5,7], [4,1,8,3] ] ...
- 从源码研究如何不重启Springboot项目实现redis配置动态切换
上一篇Websocket的续篇暂时还没有动手写,这篇算是插播吧.今天讲讲不重启项目动态切换redis服务. 背景 多个项目或微服务场景下,各个项目都需要配置redis数据源.但是,每当运维搞事时(修改 ...
- 如何安装vue脚手架?
前提(已经安装好node,可以正常使用npm) 一.cmd输入 npm install vue-cli -g ---- 全局安装vue-cli工具 安装好过后,再输入指令 vue --version ...
- 关于宝塔面板ftp+sublime
如果sublime通过ftp上传文件传不上去,我的问题在于应该把sftp-config.json中"remote_path": "/",设置成这样.一下午.哎呀 ...
- Chrome扩展移植到Edge浏览器教程
微软在推出Edge浏览器之初,就把能够使用扩展(extension)作为一个重要功能.在Win10一周年更新版(1607)中,这项功能正式向广大用户推出(当然,Insider用户早就测试了一段时间了) ...
- SQL Msg 18054, Level 16, State 1
今天接到一个看起来很简单的任务--修改数据库中的一项数据.听起来很简单吧. 在网上搜索了一下,很快就拼凑出了相应的 SQL 语句: UPDATE [suivi].[dbo].[numSerie]SET ...