梯度下降(Gradient Descent)法
梯度下降法(Gradient Descent)是求解无约束最优化问题最常用的方法之一,它是一种迭代方法,每一步的主要操作就是求解目标函数的梯度向量,将当前位置的负梯度方向作为搜索方向。
直观的表示可用下图来表示:
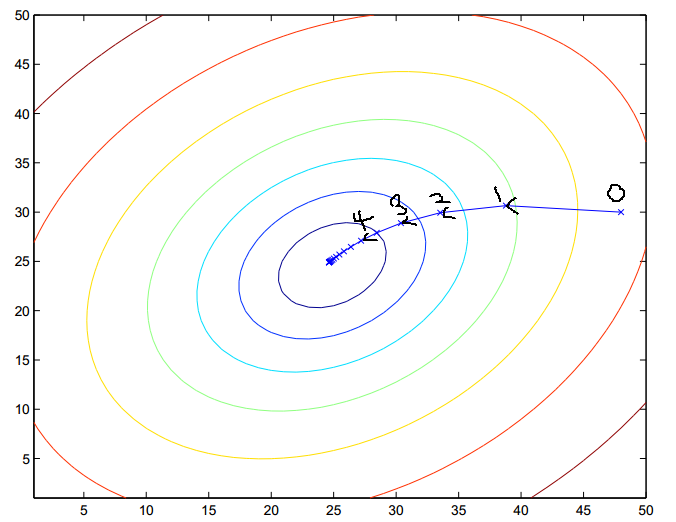
这里每一个圈代表一个函数梯度,最中心表示函数极值点,每次迭代根据当前位置求得的梯度(用于确定搜索方向以及与步长共同决定前进速度)和步长找到一个新的位置,这样不断迭代最终到达目标函数局部最优点(如果目标函数是凸函数,则到达全局最优点)。
梯度下降法其本质就是在不停的求偏导、更新损失函数,直至收敛
1、 梯度
梯度向量求出来有什么意义???从几何意义来讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点\((x_0,y_0)\)沿梯度向量的方向就是\((\frac{\partial f}{\partial x_0},\frac{\partial f}{\partial y_0})^T\)的方向是f(x,y)增加最快的地方。或者说,沿着梯度向量的方向,更容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是\(-(\frac{\partial f}{\partial x_0},\frac{\partial f}{\partial y_0})^T\)的方向,梯度减少最快,也就是更容易找到函数的最小值。
2、梯度下降和梯度上升
在机器学习算法中,在最小化损失函数时,可以通过梯度下降法来一步步的迭代求解,得到最小化的损失函数,和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。
梯度下降法和梯度上升法是可以互相转化的。比如我们需要求解损失函数f(θ)的最小值,这时我们需要用梯度下降法来迭代求解。但是实际上,我们可以反过来求解损失函数 -f(θ)的最大值,这时梯度上升法就派上用场了。
3、梯度下降算法详解
3.1 梯度下降的直观理解
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
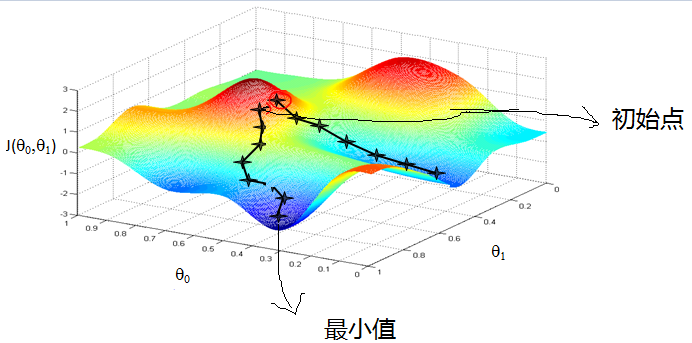
3.2 梯度下降的相关概念
- 步长(learning rate):步长决定梯度下降过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
- 特征(feature):指样本中输入部分,比如2个单特征的样本\((x^{(0)},y^{(0))}),(x^{(1)},y^{(1))})\),则第一个样本特征为\(x^{(0)}\),第一个样本输出为\(y^{(0)}\)
- 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为\(h_\theta(x)\)。比如对于单个特征的m个样本\((x^{(i)},y^{(i)})(i = 1,2,...,m)\)可以采用拟合函数如下:\(h_\theta(x)=\theta_0+\theta_1x。\)
- 损失函数(loss function):为评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于m个样本\((x_i,y_i)(i=1,2,3...,m)\),采用线性回归,损失函数为:
\]
其中,\(x_i表示第i个样本特征,y_i表示第i个样本对应的输出,h_\theta(x_i)\)为假设函数
3.3 梯度下降的详细算法
梯度下降法的代数方法描述
1、先决条件:确定优化模型的假设函数和损失函数
比如对于线性回归,假设函数表示为:\(h_\theta(x_1, x_2, ...x_n) = \theta_0 + \theta_{1}x_1 + ... + \theta_{n}x_{n}\),其中>>\(\theta_i(i=0,1,2,...,n)\)为模型参数,\(x_i(i=0,1,2...,n)\)为每个样本的n个特征值,增加一个特征\(x_0=1\),可简化为:
\[h_\theta(x_0, x_1, ...x_n) = \sum\limits_{i=0}^{n}\theta_{i}x_{i}
\]对应于上面的假设函数,损失函数为:
\[J(\theta_0, \theta_1..., \theta_n) = \frac{1}{2m}\sum\limits_{j=0}^{m}(h_\theta(x_0^{(j)}, x_1^{(j)}, ...x_n^{(j)}) - y_j)^2
\]2、算法相关参数初始化:主要是初始化\(\theta_0, \theta_1..., \theta_n\),算法终止距离\(\varepsilon\)以及步长\(\alpha\)。在没有任何先验知识的时候,喜欢将所有的\(\theta\)初始化为0,将步长初始化为1,。在调优的时候再优化。
3、算法过程:1) 确定当前位置的损失函数的梯度,对于\(\theta_i\)其梯度表达式为:
\[\frac{\partial}{\partial\theta_i}J(\theta_0, \theta_1...,\theta_n)
\]
- 用步长乘以损失函数的梯度,得到当前下降的距离,即\(\alpha\frac{\partial}{\partial\theta_i}J(\theta_0, \theta_1..., \theta_n)\)对应于前面登山例子中的某一步。
- 确定是否所有的\(θ_i\),梯度下降的距离都小于ε,如果小于ε则算法终止,当前所有的\(θ_i(i=0,1,...n)\)即为最终结果。否则进入步骤4.
- 更新所有的θ,对于\(θ_i\),其更新表达式如下。更新完毕后继续转入步骤1.
\[\theta_i = \theta_i - \alpha\frac{\partial}{\partial\theta_i}J(\theta_0, \theta_1..., \theta_n)
\]
以线性回归为例来具体描述梯度下降。
假设样本是:\((x_1^{(0)},x_2^{(0)},...x_n^{(0)},y_0),(x_1^{(1)}, x_2^{(1)},...x_n^{(1)},y_1),...(x_1^{(m)},x_2^{(m)}, ...x_n^{(m)}, y_m)\)
损失函数如前面先决条件所讲的:\(J(\theta_0,\theta_1...,\theta_n)=\frac{1}{2m}\sum\limits_{j=0}^{m}(h_\theta(x_0^{(j)},x_1^{(j)}, ...x_n^{(j)})- y_j)^2\)
则在算法过程步骤1中对于\(θ_i\) 的偏导数计算如下\[\frac{\partial}{\partial\theta_i}J(\theta_0,\theta_1...,\theta_n)=\frac{1}{m}\sum\limits_{j=0}^{m}(h_\theta(x_0^{(j)}, x_1^{(j)}, ...x_n^{(j)}) - y_j)x_i^{(j)}
\]由于样本中没有x0上式中令所有的\(x^j_0\)为1.
步骤4中的\(\theta_i\)的更新表达式如下:\[\theta_i=\theta_i-\alpha\frac{1}{m}\sum\limits_{j=0}^{m}(h_\theta(x_0^{(j)},x_1^{(j)}, ...x_n^{j}) - y_j)x_i^{(j)}
\]从这个例子可以看出当前点的梯度方向是由所有的样本决定的,加\(\frac{1}{m}\) 是为了好理解。由于步长也为常数,他们的乘机也为常数,所以这里>\(\alpha\frac{1}{m}\)可以用一个常数表示。
梯度下降法的矩阵方式描述
- 先决条件: 和3.3.1类似,需要确认优化模型的假设函数和损失函数。
对于线性回归,假设函数\(h_\theta(x_1, x_2, ...x_n)=\theta_0+\theta_{1}x_1+...+\theta_{n}x_{n}\)的矩阵表达式是:
\[h_\mathbf{\theta}(\mathbf{X})=\mathbf{X\theta}
\]其中,假设函数\(h_\mathbf{\theta}(\mathbf{X})\)为m x 1的向量,里面有n+1个代数法的模型参数。X为mx(n+1)维的矩阵。m代表样本的个数,n+1代表样本的特征数。
损失函数表达式为:\(J(\mathbf\theta)=\frac{1}{2}(\mathbf{X\theta}-\mathbf{Y})^T(\mathbf{X\theta}-\mathbf{Y})\),其中Y是样本的输出向量,,维度为mx1
- 算法相关参数初始化:和代数法一样
- 算法过程:
- 确定当前位置的损失函数的梯度,对于\(\theta\)向量,其梯度表达式如下:
\[\frac{\partial}{\partial\mathbf\theta}J(\mathbf\theta)
\]
- 用步长乘以损失函数的梯度,得到当前位置下降的距离,即\(\alpha\frac{\partial}{\partial\theta}J(\theta)\)对于前面登山例子中的某一步
- 确定\(\theta\)向量里面的每个值,梯度下降的距离都小于\(\varepsilon\),如果小于\(\varepsilon\)则算法停止,当前\(\theta\)向量即为最终结果。否则进入第4步
- 更新\(\theta\)向量,其更新表达式如下。更新完毕后继续转步骤1
\[\mathbf\theta=\mathbf\theta-\alpha\frac{\partial}{\partial\theta}J(\mathbf\theta)
\]
以线性回归为例:
损失函数对于\(\theta\)向量的偏导数计算如下:
\[\frac{\partial}{\partial\mathbf\theta}J(\mathbf\theta)=\mathbf{X}^T(\mathbf{X\theta}-\mathbf{Y})
\]步骤4中θ向量的更新表达式如下:
\]
这里面用到了矩阵求导链式法则,和两个个矩阵求导的公式。
\[公式1:\frac{\partial}{\partial\mathbf{x}}(\mathbf{x^Tx}) =2\mathbf{x}\;\;x为向量
\]\[公式2:\nabla_Xf(AX+B) = A^T\nabla_Yf,\;\; Y=AX+B,\;\;f(Y)为标量
\]
3.4 梯度下降的算法调优
在使用梯度下降时,需要进行调优。哪些地方需要调优呢?
- 算法步长选择。
- 算法参数的初始值选择。
- 归一化。于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望\(\overline{x}\)和标准差std(x),然后转化为:
\[\frac{x - \overline{x}}{std(x)}
\]这样特征的新期望为0,新方差为1,迭代速度可以大大加快。
4 梯度下降大家族(BGD,SGD,MBGD)
4.1 批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新,这个方法对应于前面3.3.1的线性回归的梯度下降算法,也就是说3.3.1的梯度下降算法就是批量梯度下降法。
\]
由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据。
4.2 随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是:
\]
随机梯度下降法,和4.1的批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是小批量梯度下降法。
4.3 小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,1<x<m。一般可以取x=10,当然根据样本的数据,可以调整这个x的值。对应的更新公式是:
\]
5 梯度下降法和其他无约束优化算法的比较
在机器学习中的无约束优化算法,除了梯度下降以外,还有前面提到的最小二乘法,此外还有牛顿法和拟牛顿法。
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
参考:https://www.cnblogs.com/pinard/p/5970503.html
梯度下降(Gradient Descent)法的更多相关文章
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)
版权声明: 本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: ...
- 回归(regression)、梯度下降(gradient descent)
本文由LeftNotEasy所有,发布于http://leftnoteasy.cnblogs.com.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 前言: 上次写过一篇 ...
- 吴恩达深度学习:2.3梯度下降Gradient Descent
1.用梯度下降算法来训练或者学习训练集上的参数w和b,如下所示,第一行是logistic回归算法,第二行是成本函数J,它被定义为1/m的损失函数之和,损失函数可以衡量你的算法的效果,每一个训练样例都输 ...
- 梯度下降算法 Gradient Descent
梯度下降算法 Gradient Descent 梯度下降算法是一种被广泛使用的优化算法.在读论文的时候碰到了一种参数优化问题: 在函数\(F\)中有若干参数是不确定的,已知\(n\)组训练数据,期望找 ...
随机推荐
- 使用 Visual Paradigm 的业务流程模型和符号 (BPMN) 综合指南
业务流程模型和符号 (BPMN) 是一种用于建模和记录业务流程的标准化图形符号.它被广泛采用,因为它能够提供一种清晰.通用的语言,所有利益相关者(业务分析师.技术开发人员和管理人员)都能理解.Visu ...
- 解决2023新版Edge浏览器页面加载不出来问题
如果你遇到2023新版Edge浏览器页面无法加载的问题,可以尝试以下几种解决方法: 检查网络连接:确保你的网络连接正常,可以尝试打开其他网页或使用其他应用程序进行网络测试. 清除浏览器缓存:打开Edg ...
- 自动化-Yaml文件写入函数封装
1.文件布局 打开文件修改读取方式为w dump函数写入文件 写入中文 使用allow_unicode=True class ReadConfiYaml: def __init__(self,yaml ...
- kali安装pdtm工具
kali安装pdtm工具 前言 今天想安装一下pdtm工具集的,但过程中一直出现各种错误,找了几篇文章之后并没有找到解决方法,后解决之后写了这样一篇文章希望可以解决大家在安装过程中碰到的部分问题 介绍 ...
- Golang Linux、Windows、Mac 下交叉编译
前言 Golang 支持交叉编译, 即同一份代码,在一个平台上生成,然后可以在另外一个平台去执行. 之前写过一篇 Golang windows下 交叉编译 感觉写的不够全面,这篇作为补充. 交叉编译 ...
- iframe高度自适应 完美解决
前言 一直被iframe的高度自适应的问题困扰着,今天终于找到完美解决方案,加上以下css即可. css iframe { display: block; border: none; height: ...
- 启动workman stream_socket_server() has been disabled for security reasons
启动workman报错 Workerman[start.php] start in DEBUG mode stream_socket_server() has been disabled for se ...
- C# 窗口过程消息处理 WndProc
C# 窗口过程消息处理 WndProc WinForm WndProc 在 WinForm 中一般采用重写 WndProc 的方法对窗口或控件接受到的指定消息进行处理 示例:禁止通过关闭按钮或其他发送 ...
- 第一次3D打印,一个简单的小方块(rhino)
一.建模 打开犀牛,我们选择立方体 我们点击上册的中心点 输入0,然后回车0 而后我们输长度:10,回车确认 同样的,宽度10 高度同样是10 回车确认后,我们得到一个正方形 二.导出模型 我们选择文 ...
- 第八届机械工程与应用复合材料国际会议(MEACM 2025)
第八届机械工程与应用复合材料国际会议(MEACM 2025) 吉隆坡,马来西亚 2025年8月25-27日 会议简介:2025年第八届机械工程与应用复合材料国际会议(MEACM 2025)将于2025 ...