大数据入门第二十四天——SparkStreaming(二)与flume、kafka整合
前一篇中数据源采用的是从一个socket中拿数据,有点属于“旁门左道”,正经的是从kafka等消息队列中拿数据!
主要支持的source,由官网得知如下:
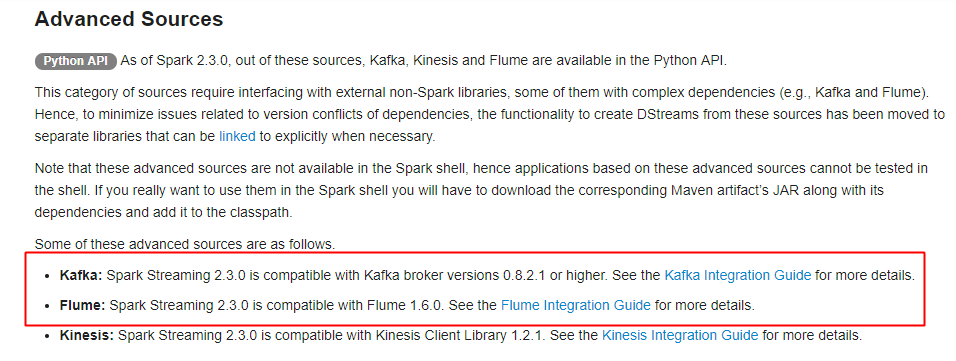
获取数据的形式包括推送push和拉取pull
一、spark streaming整合flume
1.push的方式
更推荐的是pull的拉取方式
引入依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
编写代码:
package com.streaming import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Created by ZX on 2015/6/22.
*/
object FlumePushWordCount { def main(args: Array[String]) {
val host = args(0)
val port = args(1).toInt
val conf = new SparkConf().setAppName("FlumeWordCount")//.setMaster("local[2]")
// 使用此构造器将可以省略sc,由构造器构建
val ssc = new StreamingContext(conf, Seconds(5))
// 推送方式: flume向spark发送数据(注意这里的host和Port是streaming的地址和端口,让别人发送到这个地址)
val flumeStream = FlumeUtils.createStream(ssc, host, port)
// flume中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_, 1)) val results = words.reduceByKey(_ + _)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
flume-push.conf——flume端配置文件:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true # Describe the sink
a1.sinks.k1.type = avro
#这是接收方
a1.sinks.k1.hostname = 192.168.31.172
a1.sinks.k1.port = 8888 # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-push.conf
2.pull的方式
属于推荐的方式,通过streaming来主动拉取flume产生的数据
编写代码:(依赖同上)
package com.streaming import java.net.InetSocketAddress import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} object FlumePollWordCount {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("FlumePollWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//从flume中拉取数据(flume的地址),通过Seq序列,里面可以new多个地址,从多个flume地址拉取
val address = Seq(new InetSocketAddress("172.16.0.11", 8888))
val flumeStream = FlumeUtils.createPollingStream(ssc, address, StorageLevel.MEMORY_AND_DISK)
val words = flumeStream.flatMap(x => new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
配置flume
通过拉取的方式需要flume的lib目录中有相关的JAR(要通过spark程序来调flume拉取),通过官网可以得知具体的JAR信息:
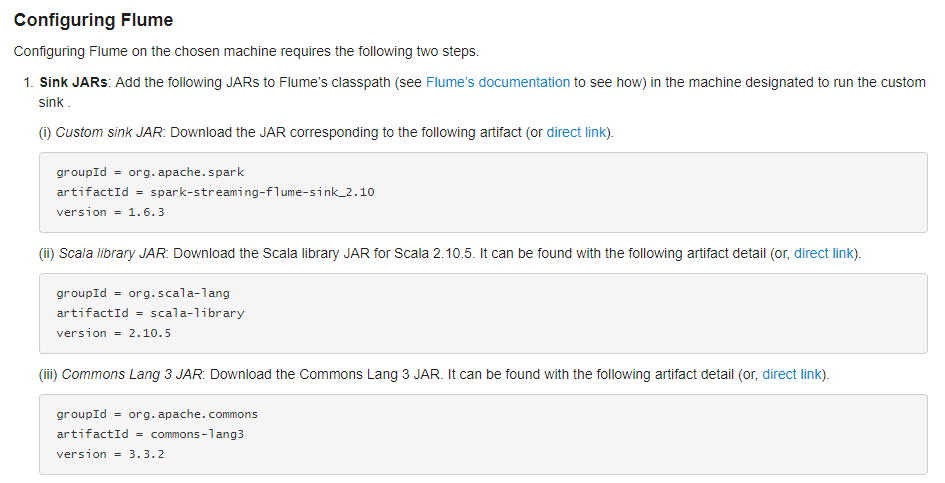
配置flume:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true # Describe the sink(配置的是flume的地址,等待拉取)
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = mini1
a1.sinks.k1.port = 8888 # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume-poll.conf
启动flume,然后启动IDEA中的spark streaming:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
// -D后参数可选
二、spark streaming整合kafka
前导知识,复习kafka:http://www.cnblogs.com/jiangbei/p/8537625.html
1.引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
2.编写代码
package com.streaming
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaWordCount {
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(i => (x, i)) }
}
def main(args: Array[String]): Unit = {
val Array(zkQuorum, group, topics, numThreads) = args
val conf = new SparkConf().setAppName("kafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
// 设置ck
ssc.checkpoint("F:/ck")
// 产生topic的map
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// data是一个DStream
val data = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap, StorageLevel.MEMORY_AND_DISK_SER)
val words = data.map(_._2).flatMap(_.split(" "))
// 使用update进行累加统计
val wordCounts = words.map((_, 1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
// 启动
ssc.start()
ssc.awaitTermination()
}
}
结合kafka也是存在两种拉取数据的形式,包括Receiver和Direct两种形式
更多参考:https://www.cnblogs.com/xlturing/p/6246538.html
但是使用更多的是Direct的直连方式,因为直连方式使用的不需要记录日志,不会影响性能
使用实例,参考:https://blog.csdn.net/ligt0610/article/details/47311771
大数据入门第二十四天——SparkStreaming(二)与flume、kafka整合的更多相关文章
- 大数据入门第二十四天——SparkStreaming(一)入门与示例
一.概述 1.什么是spark streaming Spark Streaming is an extension of the core Spark API that enables scalabl ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 大数据入门第二十五天——logstash入门
一.概述 1.logstash是什么 根据官网介绍: Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据.转换数据,然后将数据发送到您最喜欢的 “存储库” 中.(我们的存储库 ...
- 大数据入门第二十三天——SparkSQL(二)结合hive
一.SparkSQL结合hive 1.首先通过官网查看与hive匹配的版本 这里可以看到是1.2.1 2.与hive结合 spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然 ...
- 大数据入门第二十二天——spark(一)入门与安装
一.概述 1.什么是spark 从官网http://spark.apache.org/可以得知: Apache Spark™ is a fast and general engine for larg ...
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十四天——Hbase详解(一)入门与安装配置
一.概述 1.什么是Hbase 根据官网:https://hbase.apache.org/ Apache HBase™ is the Hadoop database, a distributed, ...
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 大数据入门第二十二天——spark(二)RDD算子(2)与spark其它特性
一.JdbcRDD与关系型数据库交互 虽然略显鸡肋,但这里还是记录一下(点开JdbcRDD可以看到限制比较死,基本是鸡肋.但好在我们可以通过自定义的JdbcRDD来帮助我们完成与关系型数据库的交互.这 ...
随机推荐
- ActiveReports 报表应用教程 (12)---交互式报表之贯穿钻取
在葡萄城ActiveReports报表中提供强大的数据分析能力,您可以通过图表.表格.图片.列表.波形图等控件来实现数据的贯穿钻取,在一级报表中可以通过鼠标点击来钻取更为详细的数据. 本文展示的是20 ...
- MySql 利用mysql&mysqldum导入导出数据
MySql 利用mysql&mysqldum导入导出数据 by:授客 QQ:1033553122 测试环境 Linux下测试,数据库MySql 工具 mysqldump,该命令位于mysq ...
- node socket :10106无法加载或初始化请求的服务提供程序
node socket :10106无法加载或初始化请求的服务提供程序 无端端的,不知道怎么回事,node突然就坏掉 了,应该是某些配置无意中改动了,问题如下: 目前能想到的解决办法就是:重置配置,用 ...
- tinymce4.x 上传本地图片(自己写个插件)
tinymce是一款挺不错的html文本编辑器.但是添加图片是直接添加链接,不能直接选择本地图片. 下面我写了一个插件用于直接上传本地图片. 在tinymce的plugins目录下新建一个upload ...
- 数据分析——Matplotlib图形绘制
创建画布或子图 函数名称 函数作用 plt.figure 创建一个空白画布,可以指定画布大小,像素. figure.add_subplot 创建并选中子图,可以指定子图的行数,列数,与选中图片编号. ...
- cmd 命令总结
1.windows 系统定时关机 定时关机:shutdown -s -t 300 at 18:30 shutdown -s 取消定时:shutdown -a 注意:3 ...
- HTTP 错误 401.3 - Unauthorized asp.net mvc 图片,css,js没有权限访问
一.在服务器上发布了一个asp.net的网站,结果是页面可以显示,但是css,js,images无法访问,报错是没有权限,HTTP 错误 401.3 - Unauthorized 二.根据以往的经验, ...
- 适用于 Windows 的自定义脚本扩展
自定义脚本扩展在 Azure 虚拟机上下载并执行脚本. 此扩展适用于部署后配置.软件安装或其他任何配置/管理任务. 可以从 Azure 存储或 GitHub 下载脚本,或者在扩展运行时将脚本提供给 A ...
- 使用 PowerShell 管理 Azure 磁盘
Azure 虚拟机使用磁盘来存储 VM 操作系统.应用程序和数据. 创建 VM 时,请务必选择适用于所需工作负荷的磁盘大小和配置. 本教程介绍如何部署和管理 VM 磁盘. 学习内容: OS 磁盘和临时 ...
- Linux命令(自学)
1.立刻关机: shutdown -h now 2.立刻重启: shutdown -r now reboot 3.注销: logout 4.进入vi编辑器,写一个hello的java程序: vi he ...