Mysql 之分库分表方案
Mysql分库分表方案
为什么要分表
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
大数据量并且访问频繁的表,将其分为若干个表
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表,那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<500万条数据,就直接插入,当已经到达阀值,可以在程序段新创建数据库表(或者已经事先创建好),再执行插入操作。
利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
举例子:
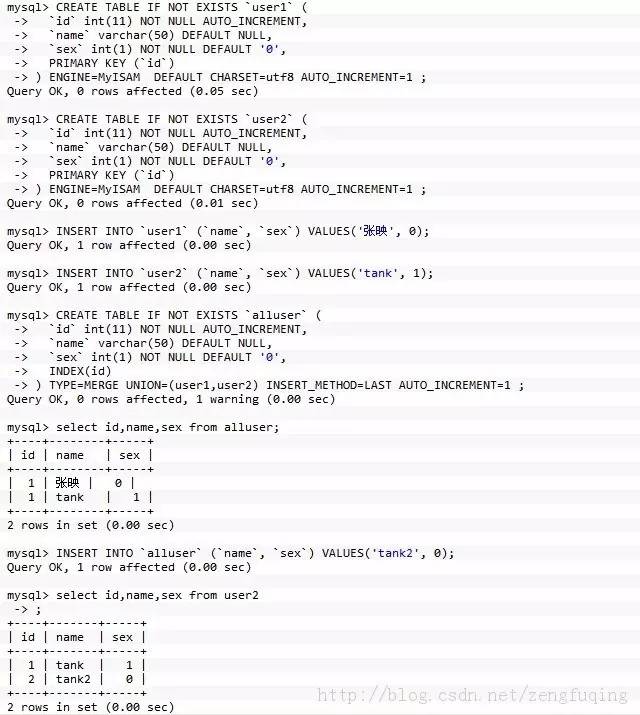
数据库架构
简单的MySQL主从复制:
MySQL的主从复制解决了数据库的读写分离,并很好的提升了读的性能,其图如下: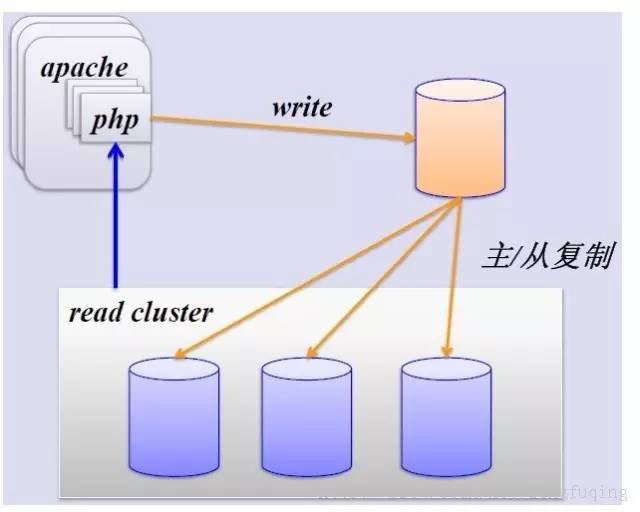
其主从复制的过程如下图所示:
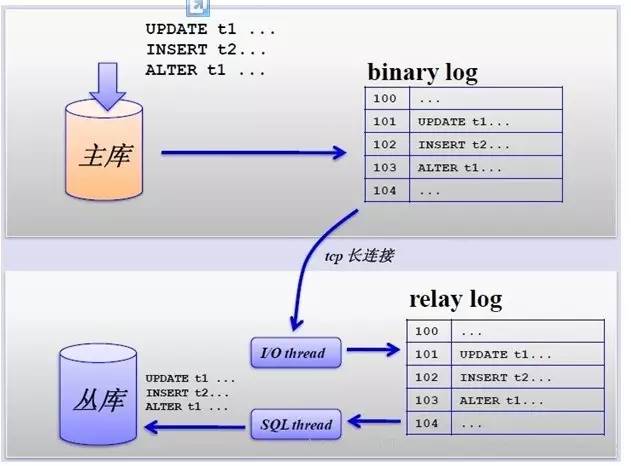
但是,主从复制也带来其他一系列性能瓶颈问题:
1、写入无法扩展
2、写入无法缓存
3、复制延时
4、锁表率上升
5、表变大,缓存率下降
那问题产生总得解决的,这就产生下面的优化方案,一起来看看。
MySQL垂直分区
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库服务器将是一个不错的方案,而且万一其中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的作用,大大提升了数据库的吞吐能力。经过垂直分区后的数据库架构图如下:
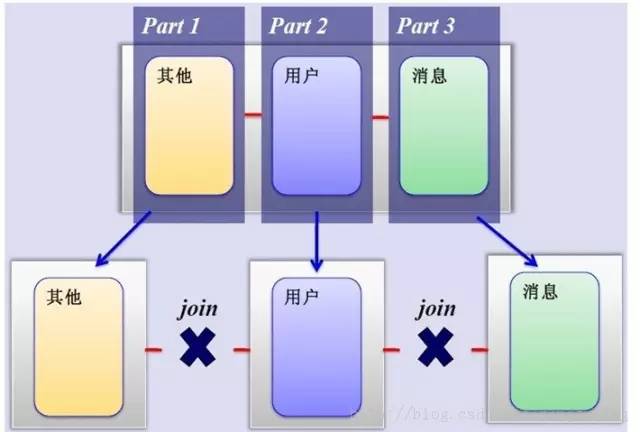
然而,尽管业务之间已经足够独立了,但是有些业务之间或多或少总会有点联系,如用户,基本上都会和每个业务相关联,况且这种分区方式,也不能解决单张表数据量暴涨的问题,因此为何不试试水平分割呢?
MySQL水平分片(Sharding)
这是一个非常好的思路,将用户按一定规则(按id哈希)分组,并把该组用户的数据存储到一个数据库分片中,即一个sharding,这样随着用户数量的增加,只要简单地配置一台服务器即可,原理图如下:
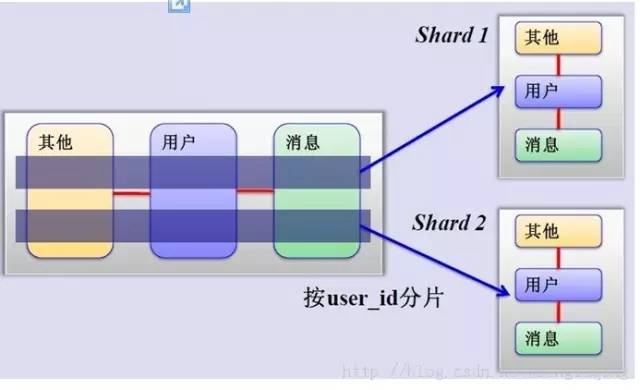
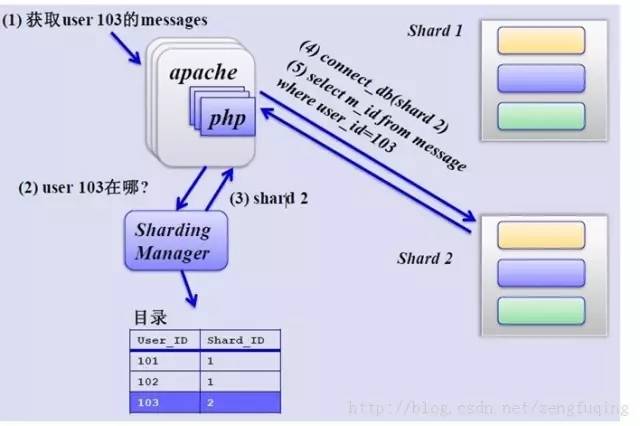
如何来确定某个用户所在的shard呢,可以建一张用户和shard对应的数据表,每次请求先从这张表找用户的shard id,再从对应shard中查询相关数据,如下图所示:
Mysql 之分库分表方案的更多相关文章
- Mysql分库分表方案
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- 【分库、分表】MySQL分库分表方案
一.Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. ...
- MySQL 分库分表方案,总结的非常好!
前言 公司最近在搞服务分离,数据切分方面的东西,因为单张包裹表的数据量实在是太大,并且还在以每天60W的量增长. 之前了解过数据库的分库分表,读过几篇博文,但就只知道个模糊概念, 而且现在回想起来什么 ...
- 基于Mysql数据库亿级数据下的分库分表方案
移动互联网时代,海量的用户数据每天都在产生,基于用户使用数据的用户行为分析等这样的分析,都需要依靠数据都统计和分析,当数据量小时,问题没有暴露出来,数据库方面的优化显得不太重要,一旦数据量越来越大时, ...
- MySQL主从(MySQL proxy Lua读写分离设置,一主多从同步配置,分库分表方案)
Mysql Proxy Lua读写分离设置 一.读写分离说明 读写分离(Read/Write Splitting),基本的原理是让主数据库处理事务性增.改.删操作(INSERT.UPDATE.DELE ...
- Mysql 分库分表方案
0 引言 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. mysql中有一种机制是表锁定和行锁 ...
- mysql 数据库 分表后 怎么进行分页查询?Mysql分库分表方案?
Mysql分库分表方案 1.为什么要分表: 当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间. m ...
- php面试专题---mysql数据库分库分表
php面试专题---mysql数据库分库分表 一.总结 一句话总结: 通过数据切分技术将一个大的MySQLServer切分成多个小的MySQLServer,既攻克了写入性能瓶颈问题,同一时候也再一次提 ...
- 使用ShardingSphere-JDBC完成Mysql的分库分表和读写分离
1. 概述 老话说的好:选择比努力更重要,如果选错了道路,就很难成功. 言归正传,之前我们聊了使用 MyCat 实现Mysql的分库分表和读写分离,MyCat是服务端的代理,使用MyCat的好处显而易 ...
随机推荐
- jQuery -> 基于当前元素的遍历
版权声明:本文为博主原创文章,转载请注明出处 https://blog.csdn.net/FeeLang/article/details/26257549 假设我们已经通过jQuery方法选中了一组元 ...
- css属性的继承性
不可继承属性: 盒子模型属性:width height padding border margin 背景相关属性:background相关(background-image background-si ...
- 设计一个 硬件 实现的 Dictionary(字典)
Dictionary 就是 字典, 是一种可以根据 Key 来 快速 查找 Value 的 数据结构 . 比如 我们在 C# 里用到的 Dictionary<T>, 在 程序设计 里, 字 ...
- touch-action 解决移动端300ms延迟问题
CSS3 新属性, touch-action: manipulation; 可以有效的解决移动端300ms延迟的问题 移动端300ms延迟问题一直都是h5APP的痛点, 有很多库或者方法都可以解决, ...
- Kubernetes 知识点
自己总结的 Kubernetes 的各模块(待补充) 各模块包含关系: namespace => node => pod => container table th:first-of ...
- oauth2 java 代码示例
@RequestMapping("/oauth") @Controller public class OauthController { String clientId = &qu ...
- bzoj 2806 [Ctsc2012]Cheat——广义后缀自动机+单调队列优化DP
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2806 只想着怎么用后缀数据结构做,其实应该考虑结合其他算法. 可以二分那个长度 L .设当前 ...
- 微信小程序学习之for循环
一.使用自定义创建的json数据 1. 创建微信小程序项目后 在wxml文件中增加for循环 <block wx:for="{{posts_key}}" wx:for-ite ...
- Linux重定向及nohup不输出的方法
转载自:http://blog.csdn.net/qinglu000/article/details/18963031 先说一下linux重定向: 0.1和2分别表示标准输入.标准输出和标准错误信 ...
- AM二次开发中选择指定范围内的对象
使用Spatial可以快速选择指定范围内的对象 例如下面的代码可以选择所有在[0,0,0]-[10m,10m,10m]这个盒子之内的对象: 其中ElementsInBox还可以指定对象类型做进一步筛选 ...