kafka原理与组件
一.什么是kafka
kafka的目标是实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台。是分布式发布-订阅消息系统,是一个分布式的,可划分的,冗余备份的持久性的日志服务。
Kafka使用场景:
1 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
2 消息系统:解耦和生产者和消费者、缓存消息等。
3 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
4 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
5 流式处理:比如spark streaming和storm
Kafka拓扑与流程:
二.Kafka组件
1.主题(topic)
Kafka将一组消息归纳为一个主题(topic),一个主题就是对消息的一个分类。生产者将消息发送到特定的主题,消费者订阅主题或主题的某些分区进行消费。
2.消息
Kafka通信基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。
3.分区与副本
Kafka可以将主题划分为多个分区(Partition),会根据分区规则选择把消息存储到哪个分区中,只要如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。另外,多个订阅者可以从一个或者多个分区中同时消费数据,以支撑海量数据处理能力
Kafka的设计也是源自生活,好比是为公路运输,不同的起始点和目的地需要修不同高速公路(主题),高速公路上可以提供多条车道(分区),流量大的公路多修几条车道保证畅通,流量小的公路少修几条车道避免浪费。收费站好比消费者,车多的时候多开几个一起收费避免堵在路上,车少的时候开几个让汽车并道就好了
分区数可以大于节点数,但是副本数不能大于节点数量。创建主题是分区数量最好为代理数量的整数倍。
每分区有一个或多个副本(replica),从存储角度上分析,每个副本在逻辑上抽象为一个日志(log)对象,即分区的副本与日志对象是一一对应的,Kafka会给每个分区找一个节点当带头大哥(Leader),以及若干个节点当随从(Follower)。消息写入分区时,带头大哥除了自己复制一份外还会复制到多个随从。如果随从挂了,Kafka会再找一个随从从带头大哥那里同步历史消息。
Kafka保证一个分区内消息是有序的,不能保证跨分区消息有序性,每条消息被追加到相应的分区,是顺序写磁盘,因此效率很高。
segment对应一个文件(实现上对应2个文件,一个数据文件,一个索引文件),一个partition对应一个文件夹,一个partition里理论上可以包含任意多个segment。
4.偏移量(offset)
kafka作为一个消息队列,每次读取消息时,需要指定从哪里读取,否则就会从默认位置读取。
那么为什么不将位置偏移量储存在kafka中呢?原因是,如果在位置偏移量记录在kafka, 当kafka组件故障重启时,就无法获取位置偏移量。zookeeper作为常用组件管理工具,成为记录kafka位置偏移量推荐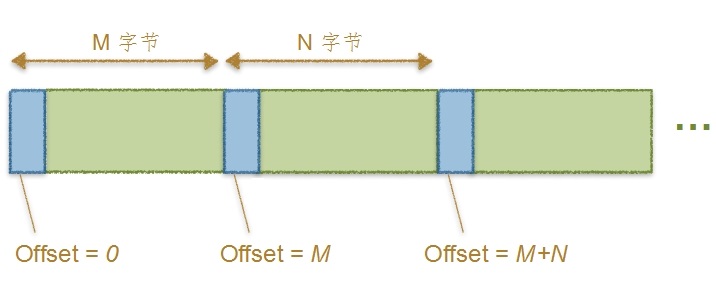
从上图可以看出,每条消息存在磁盘的偏移量是其距离文件开头的绝对偏移量。比如上面第一条消息的偏移量是0;第二条消息的偏移量是第一条消息的总长度;第三条消息是其前两条消息总长度;以此类推。这种方式存储消息的偏移量很好理解,处理起来也很方便。
需要注意,消息存储到磁盘的偏移量是由 Broker 处理完成的,原因很简单,因为只有 Broker 端才知道现在 Log 的最新偏移量; Producer 端是无法获取的
5.代理(broker)
Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
1 Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。
2 Broker不保存订阅者的状态,由订阅者自己保存。
3 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),Kafka采用基于时间的SLA(服务保证),消息保存一定时间(通常7天)后会删除。
4消费订阅者可以rewind back(回卷)到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息
6.生产者(producer)
生产者负责将消息发送给代理,也就是向kafka代理发送消息的客户端。
7.消费者(comsumer)和消费组
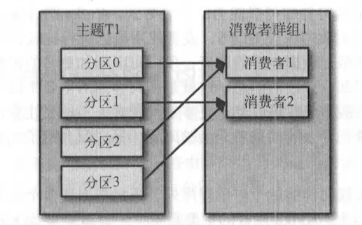
假设我们有一个应用程序需要从-个 Kafka主题读取消息并验证这些消息,然后再把它们 保存起来。应用程序需要创建一个消费者对象,订阅主题并开始接收消息,然后验证消息 井保存结果。过了 一阵子,生产者往主题写入消息的速度超过了应用程序验证数据的速度,这个时候该怎么办?如果只使用单个消费者处理消息,应用程序会远跟不上消息生成的速度。显然,此时很有必要对消费者进行横向伸缩。就像多个生产者可以向相同的 主题 写入消息一样,我们也可以使用多个消费者从同一个主题读取消息,对消息进行分流。
Kafka 消费者从属于消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者 接收主题一部分分区的消息。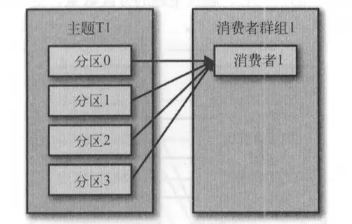
8.ISR
kafka同步机制
同步复制:只有所有的follower把数据拿过去后才commit,一致性好,可用性不高。
异步复制:只要leader拿到数据立即commit,等follower慢慢去复制,可用性高,立即返回,一致性差一些。
不是完全同步:是一种ISR机制:
1. leader会维护一个与其基本保持同步的Replica列表,该列表称为ISR(in-sync Replica),每个Partition都会有一个ISR,而且是由leader动态维护
2. 如果一个flower比一个leader落后太多,或者超过一定时间未发起数据复制请求,则leader将其重ISR中移除
3. 当ISR中所有Replica都向Leader发送ACK时,leader才commit
把滞后的follower移除ISR主要是避免写消息延迟。设置ISR主要是为了broker宕掉之后,重新选举partition的leader从ISR列表中选择。
kafka原理与组件的更多相关文章
- Kakfa揭秘 Day1 Kafka原理内幕
Spark Streaming揭秘 Day32 Kafka原理内幕 今天开始,会有几天的时间,和大家研究下Kafka.在大数据处理体系中,kafka的重要性不亚于SparkStreaming.可以认为 ...
- kafka原理简介并且与RabbitMQ的选择
kafka原理简介并且与RabbitMQ的选择 kafka原理简介,rabbitMQ介绍,大致说一下区别 Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和 ...
- atitit.文件上传带进度条的实现原理and组件选型and最佳实践总结O7
atitit.文件上传带进度条的实现原理and组件选型and最佳实践总结O7 1. 实现原理 1 2. 大的文件上传原理::使用applet 1 3. 新的bp 2 1. 性能提升---分割小文件上传 ...
- kafka原理和实践(一)原理:10分钟入门
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(二)spring-kafka简单实践
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(六)总结升华
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(三)spring-kafka生产者源码
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(四)spring-kafka消费者源码
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- kafka原理和实践(五)spring-kafka配置详解
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
随机推荐
- 025_Excel知识汇总
一.Excel相对引用和绝对应用的区别 加上了绝对地址符“$”的列标和行号为绝对地址,在公式向旁边复制时不会发生变化,没有加上绝对地址符号的列标和行号为相对地址,在公式向旁边复制时会跟着发生变化. 具 ...
- 【winform】主窗体多线程给子窗体传值
1.主窗体多线程给子窗体传值 解决方案:主要使用委托,因为会出现跨线程错误 主窗体 public FormMain() { InitializeComponent(); //background th ...
- Mac下epub电子书制作编辑器 : Sigil
官方博客:https://sigil-ebook.com github项目地址:https://github.com/Sigil-Ebook V0.9.10下载:https://github.com/ ...
- egg.js 相关
egg sequelize 建表规范 CREATE TABLE `wx_member` ( `id` ) NOT NULL AUTO_INCREMENT COMMENT 'primary key' ...
- Learning Face Age Progression: A Pyramid Architecture of GANs-1-实现人脸老化
Learning Face Age Progression: A Pyramid Architecture of GANs Abstract 人脸年龄发展有着两个重要的需求,即老化准确性和身份持久性, ...
- RedisTemplate 获取redis中以某些字符串为前缀的KEY列表
// *号 必须要加,否则无法模糊查询 String prefix = "ofc-pincode-"+ pincode + "-*"; // 获取所有的key ...
- [转]使用apt安装nodejs10
使用apt安装nodejs10 链接地址:https://blog.csdn.net/sunhaobo1996/article/details/80340513
- node + promise 实现文件读写
const fs = require('fs'); const promise = new Promise((resolve, reject) => { fs.open('./c.txt ...
- KMP操作大全与kuangbin kmp套题题解
先搬运,比赛后整理 https://blog.csdn.net/vaeloverforever/article/details/82024957
- 《TCP/IP - OSI和TCP/IP分层模型》
一:分层模型 - - OSI 更强调:通信协议必要的功能是什么 - TCP/IP 更强调:在计算机上实现协议应该开发哪种程序 二:为什么会产生协议标准化 (分层模型的产生)? - 由于各个厂商生产 ...