xgboost 算法总结
xgboost有一篇博客写的很清楚,但是现在网址已经失效了,之前转载过,可以搜索XGBoost 与 Boosted Tree。
现在参照这篇,自己对它进行一个总结。
xgboost是GBDT的后继算法,也是采用boost算法的cart 树集合。
一、基学习器:分类和回归树(CART)
cart树既可以 进行分类,也可以进行回归,但是两种情况下,采用的切分变量选择方式不同。
CART在进行回归的时候,选择最优切分变量和切分点采用的是如下的标准
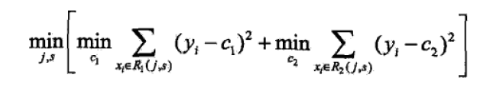
其中,c1 和c2满足下式,即为该段变量取值的均值
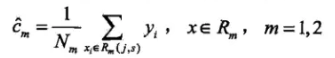
CART采用暴力的遍历方式来确定最优切分变量和切分点,具体算法如下:

CART分类树的算法类似,由于分类无法计算均值,CART分类树采用的是计算基尼指数,通过遍历所有特征和他们的可能切分点,选择基尼指数最小的特征及切分点作为最优特征和最优切分点,并重复调用,直到生成CART分类树。
二、Tree Ensemble
如果单棵树的过于简单无法有效地预测,因此一个更加强力的模型叫做tree ensemble,也就是分类树的集成算法。如果采用boost集成,也就是加法集成,可以写成如下
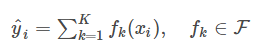
其中每个f是一个在函数空间里面的函数,而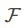 对应了所有regression tree的集合。
对应了所有regression tree的集合。
目标函数如下:
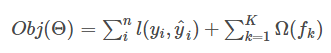
前半部分是误差函数,后半部分是正则化项。
三、模型学习 additive training
因为现在我们的参数可以认为是在一个函数空间里面,我们不能采用传统的如SGD之类的算法来学习我们的模型,因此我们会采用一种叫做additive training的方式。。每一次保留原来的模型不变,加入一个新的函数ff到我们的模型中。

现在还剩下一个问题,我们如何选择每一轮加入什么f呢?答案是非常直接的,选取一个f来使得我们的目标函数尽量最大地降低
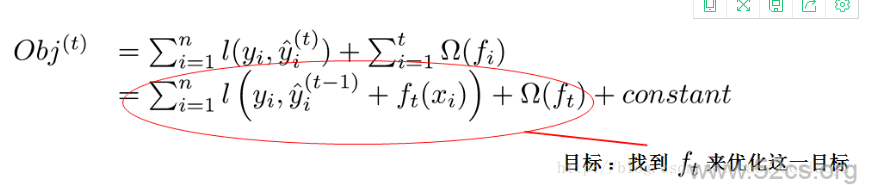
这个公式可能有些过于抽象,我们可以考虑当ll是平方误差的情况。这个时候我们的目标可以被写成下面这样的二次函数
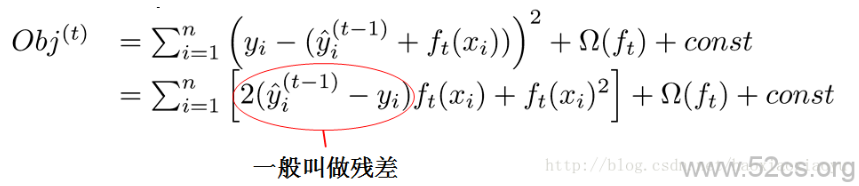
更加一般的,对于不是平方误差的情况,我们会采用如下的泰勒展开近似来定义一个近似的目标函数,方便我们进行这一步的计算

当我们把常数项移除之后,我们会发现如下一个比较统一的目标函数。这一个目标函数有一个非常明显的特点,它只依赖于每个数据点的在误差函数上的一阶导数和二阶导数
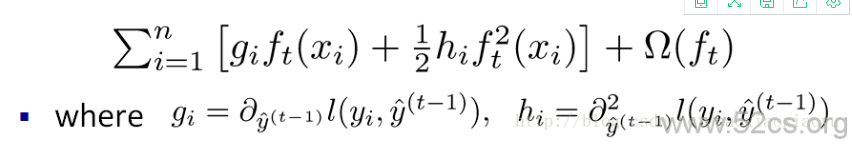
四、树的复杂度
到目前为止我们讨论了目标函数中训练误差的部分。接下来我们讨论如何定义树的复杂度。我们先对于f的定义做一下细化,把树拆分成结构部分q和叶子权重部分w。下图是一个具体的例子。结构函数q把输入映射到叶子的索引号上面去,而w给定了每个索引号对应的叶子分数是什么

当我们给定了如上定义之后,我们可以定义一棵树的复杂度如下。这个复杂度包含了一棵树里面节点的个数,以及每个树叶子节点上面输出分数的L2模平方。当然这不是唯一的一种定义方式,不过这一定义方式学习出的树效果一般都比较不错。

五、关键步骤
这是xgboost最巧妙处理的部分,在这种新的定义下,我们可以把目标函数进行如下改写,其中 被定义为每个叶子上面样本集合
被定义为每个叶子上面样本集合

这样目标函数可以如下变化,使用步骤四中的方式来表示误差函数和复杂度,如下
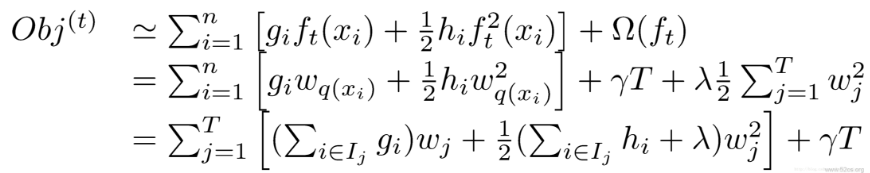
这一个目标包含了T个相互独立的单变量二次函数。我们可以定义
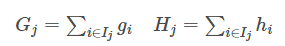
则
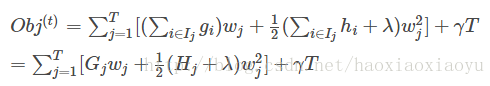
这是一个关于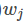 的二次函数,可以知道最值如下:
的二次函数,可以知道最值如下:
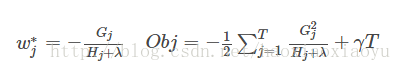
六、打分函数计算举例
最后一部分是算法计算的简化。
第五部分中提到的Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做结构分数(structure score)。你可以认为这个就是类似吉尼系数一样更加一般的对于树结构进行打分的函数。下面是一个具体的打分函数计算的例子

七、枚举所有不同树结构的贪心法
xgboost算法不断地枚举不同树的结构,利用这个打分函数来寻找出一个最优结构的树,加入到我们的模型中,再重复这样的操作。不过枚举所有树结构这个操作不太可行,所以常用的方法是贪心法,每一次尝试去对已有的叶子加入一个分割。对于一个具体的分割方案,我们可以获得的增益可以由如下公式计算

对于每次扩展,我们还是要枚举所有可能的分割方案,如何高效地枚举所有的分割呢?我假设我们要枚举所有 x小于a 这样的条件,对于某个特定的分割a我们要计算a左边和右边的导数和。

我们可以发现对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL和GR。然后用上面的公式计算每个分割方案的分数就可以了。
观察这个目标函数,大家会发现第二个值得注意的事情就是引入分割不一定会使得情况变好,因为我们有一个引入新叶子的惩罚项。优化这个目标对应了树的剪枝, 当引入的分割带来的增益小于一个阀值的时候,我们可以剪掉这个分割。大家可以发现,当我们正式地推导目标的时候,像计算分数和剪枝这样的策略都会自然地出现,而不再是一种因为heuristic而进行的操作了。
八、最后:
xgboost的github地址: https://github.com/dmlc/xgboost 。xgboost是大规模并行boosted tree的工具,它是目前最快最好的开源boosted tree工具包,比常见的工具包快10倍以上。
xgboost 算法总结的更多相关文章
- XGBoost算法--学习笔记
学习背景 最近想要学习和实现一下XGBoost算法,原因是最近对项目有些想法,准备做个回归预测.作为当下比较火的回归预测算法,准备直接套用试试效果. 一.基础知识 (1)泰勒公式 泰勒公式是一个用函数 ...
- 机器学习总结(一) Adaboost,GBDT和XGboost算法
一: 提升方法概述 提升方法是一种常用的统计学习方法,其实就是将多个弱学习器提升(boost)为一个强学习器的算法.其工作机制是通过一个弱学习算法,从初始训练集中训练出一个弱学习器,再根据弱学习器的表 ...
- Python机器学习笔记:XgBoost算法
前言 1,Xgboost简介 Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器.因为Xgboost是一种提升树模型,所以它是将许多 ...
- 说说xgboost算法
xgboost算法最近真是越来越火,趁着这个浪头,我们在最近一次的精准营销活动中,也使用了xgboost算法对某产品签约行为进行预测和营销,取得了不错的效果.说到xgboost,不得不说它的两大优势, ...
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- 转载:XGBOOST算法梳理
学习内容: CART树 算法原理 损失函数 分裂结点算法 正则化 对缺失值处理 优缺点 应用场景 sklearn参数 转自:https://zhuanlan.zhihu.com/p/58221959 ...
- xgboost算法教程(两种使用方法)
标签: xgboost 作者:炼己者 ------ 欢迎大家访问我的简书以及我的博客 本博客所有内容以学习.研究和分享为主,如需转载,请联系本人,标明作者和出处,并且是非商业用途,谢谢! ------ ...
- XGBoost算法
一.基础知识 (1)泰勒公式 泰勒公式是一个用函数在某点的信息描述其附近取值的公式.具有局部有效性. 基本形式如下: 由以上的基本形式可知泰勒公式的迭代形式为: 以上这个迭代形式是针对二阶泰勒展开,你 ...
- XGBoost算法原理小结
在两年半之前作过梯度提升树(GBDT)原理小结,但是对GBDT的算法库XGBoost没有单独拿出来分析.虽然XGBoost是GBDT的一种高效实现,但是里面也加入了很多独有的思路和方法,值得单独讲一讲 ...
- 04-09 XgBoost算法
目录 XgBoost算法 一.XgBoost算法学习目标 二.XgBoost算法详解 2.1 XgBoost算法参数 2.2 XgBoost算法目标函数 2.3 XgBoost算法正则化项 2.4 X ...
随机推荐
- .Net Core 2.2 发布IIS遇到的那些坑
这两天在研究.Net Core 发布iis总结一下. 我主要是参照官方文档: https://docs.microsoft.com/zh-cn/aspnet/core/host-and-deploy/ ...
- 《linux就该这么学》课堂笔记03 命令初识 echo、date、reboot、poweroff、wget...
Linux进程的六种状态(R.S.D.T.Z.X): R --- TASK_RUNNING(可执行状态) S --- TASK_INTERRUPTIBLE(可中断的睡眠状态) D --- TASK_U ...
- virsh console 登录CentOS7系统
一.在kvm虚拟机中执行如下命令 systemctl start serial-getty@ttyS0.service systemctl enable serial-getty@ttyS0.serv ...
- django项目中使用KindEditor富文本编辑器。
先从官网下载插件,放在static文件下 前端引入 <script type="text/javascript" src="/static/back/kindedi ...
- Exploit Kit——hacker入侵web,某iframe中将加载RIG EK登录页面,最终下载并执行Monero矿工
RIG Exploit Kit使用PROPagate注入技术传播Monero Miner from:https://www.4hou.com/technology/12310.html 导语:Fire ...
- The Role of View Controllers
https://developer.apple.com/library/content/featuredarticles/ViewControllerPGforiPhoneOS/index.html# ...
- PostgreSQL 慢查询SQL跟踪
PostgreSQL 开启慢SQL捕获在排查问题时是个很有效的手段.根据慢SQL让我在工作中真正解决了实际问题,很有帮助. PostgreSQL 日志支持的输出格式有 stderr(默认).csvlo ...
- form设计批量赋值
data: { list:[], cards: { cardname: "", cardtitle: "", cardtel: "", ca ...
- 《Java虚拟机JVM故障诊断与性能优化》读书笔记(未完待续)
前言: 对于JVM学习用处的理解:我们程序员写的代码,虽说是放在服务器(linux)系统上的.但是很多时候,受JVM的影响,其实程序并没有发挥出服务器的最大性能.这时候,JVM就成为了瓶颈了.有瓶颈就 ...
- java并发编程(四) 线程池 & 任务执行、终止源码分析
参考文档 线程池任务执行全过程:https://blog.csdn.net/wojiaolinaaa/article/details/51345789 线程池中断:https://www.cnblog ...