利用weka和clementine数据挖掘举例
1.数据概述
本报告中采用的数据集来自于UCI经典数据集Adult,最初来源是由1994年Barry Becker的统计数据集,该数据集本来最初的主要任务是根据数据集中的相关属性预测某个人的年收入是大于50K还是小于等于50K。本数据集一共有14个属性用来预测个人的年收入,包括了年龄、工作阶层、教育程度、职业、性别、种族、家庭状况等情况。这14个基本属性中有一项属性为fnlwgt,即final weight,具有相同背景的人的fnlwgt应该类似。同时本数据集一共有32561个样本案例,属性的数据类型有数值型数据和分类型数据。根据每一个属性和最终收入的关系的统计结果如下图所示:
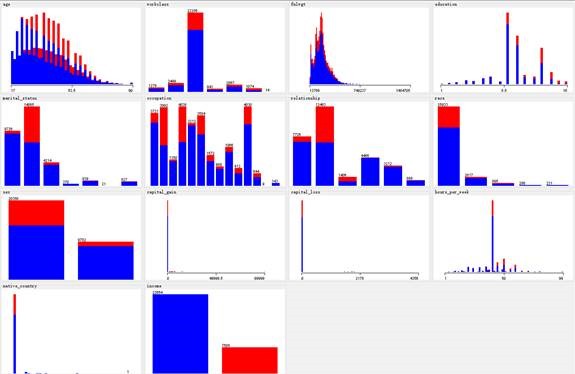
图1.1 所有特征值的统计结果
其中蓝色表示的是年收入小于等于50K,红色表示是年收入大于50K。由上图可以看出很多特征中数据的分布很不平衡。在native_country属性中,绝大多数的人都集中在美国,这是由于该统计数据主要是在美国范围内进行调查的,所以大多数人的初始国籍都是美国,因而该属性对于最终的分析的影响不大。同时观察captital_gain和capital_loss的分布,可以发现大多数都处于0。在workclass中大多数的属性都是private,而relationship和sex之间也必然存在相关联系,例如relationship中的husband一定对应的是sex中的male,这些属性间的相关关系在之后的分析中都需要加以关注。
2.数据预处理
2.1降维、缺失项处理
本数据集14个属性分别为age、workclass、fnlwgt、education、education_num、marital_status、occupation、relationship、race、sex、capital_gain、capital_loss、hours_per_week、native_country,在这14个属性中,必然存在两者相关的属性。
首先可以分析education和education_num之间的相互关系,如下图2.1所示:
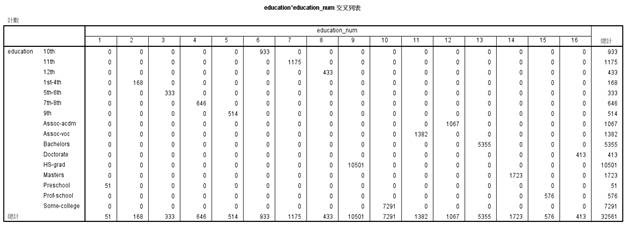
图2.1 education和education_num交叉列表
由此可以看出一个教育程度对应一个教育年限,因而在之后的分析之中,将教育程度和教育年限合并为一个变量即教育水平,用原教育年限的数值来表示该变量。
整个数据集中包含了缺失项,首先对缺失项进行统计,存在缺失值的属性主要是工作阶层、职业以及来自国家,缺失率分别为5.6%,5.7%,1.8%,具体的缺失情况如下图2.2所示:
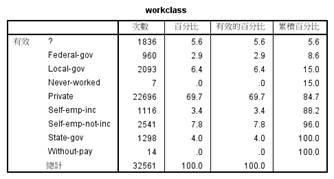
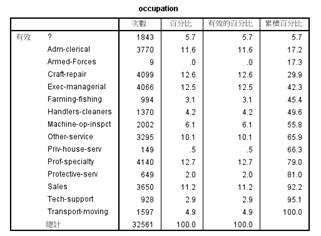
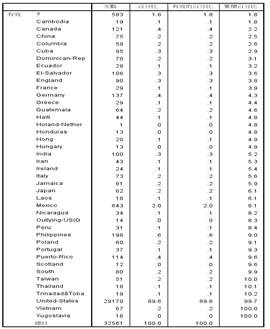
图2.2 数据缺失情况
对工作阶层和职业的相互关系进行分析,如下图2.3所示:
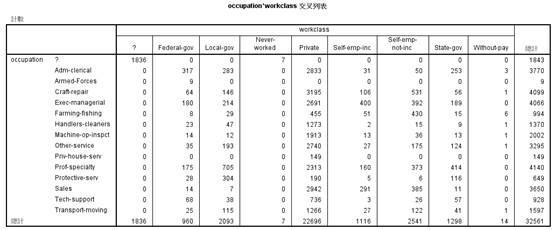
图2.3 职业和工作阶层相互关系
有图2.3可以看出,所有工作阶层的缺失值,其对应的职业也是缺失的,而职业缺失的另外一部分为从来没有工作的那一部分即有7个案例满足条件,而这些人的收入必然是小于50k的,因而可以将这些案例删除。而再进一步对所有工作阶层缺失的1836个案例的收入进行分析,可以得到如下关系:
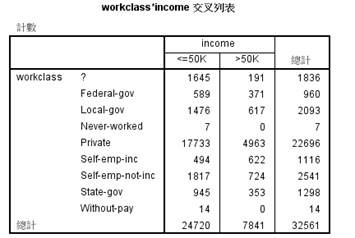
图2.4 工作阶层和收入的相互关系
从上图中可以看出,未知工作阶层中10%左右的人的年收入是大于50K的,为了避免之后的数据处理出现偏差,在初步分析中将这些有缺失数据的案例删除。
采用同样的处理策略,将所有来自国家有缺失的案例也同样删除,这样一共得到30162条数据,13个属性变量。
2.2 数据编码
在上述13个属性当中,workclass、marital_status、occupation、relationship、race、native_country均是categorical类型的数据,因而为了保证之后进行分类时候的准确性,需要对着几个变量进行重新编码。由于这些categorical类型的数据,不存在相互的远近关系,所以需要保证同一个属性中两个不同值之间的距离都相同,同时考虑到数据维度过大对计算机处理能力要求等问题,并且根据上述分析occupation和workclass之间存在一定的关系,同时native_country中绝大部分都是United States,考虑到这对最终的结果影响不大,所以本实验中只对workclass,marital_status,race和sex进行编码,分别为0000001-1000000,0000001-1000000,00001-10000以及0-1。
3.数据分类
3.1 SVM
本文首先利用SVM进行分类,SVM是一种训练机器学习的算法,可以用于解决分类和回归问题,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。SVM不仅可以进行线性分类,对于线性不可分的数据集也可以基于kernel进行非线性分类。非线性SVM意味着该算法计算的边界没有必要是一条直线,这样做的好处在于,可以捕获更多数据点集之间的复杂关系,而无需靠用户自己来执行困难的转换。其缺点就是由于更多的运算量,训练的时间要长很多。
基于上述分析,整个数据集有30162条数据,一共有26维,利用matlab自带的svm训练器,选取其中70%的数据作为训练集,剩余的30%数据作为测试集,同时由于整个数据集的排列顺序是随机的,因而选择排在前70%的数据作为训练集,后30%的数据作为测试集,则得到的训练集有21113条,测试集为9049条。
同时为了保证每个属性值都得到平等对待,因而对数据集进行归一化,将所有属性值的取值范围限制在[0,1]之间。同时考虑到数据集的情况较为复杂,属于线性不可分的问题,因而选用kernel方法对数据进行非线性分类,选取高斯作为kernel函数,具体的操作步骤如下图所示:
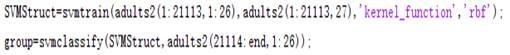
图3.1 Matlab处理过程
由于所有的数据排列顺序都是随机的,因而选择前21113条数据作为训练样本,而后9049条数据作为测试样本,在通过上述Matlab操作步骤得到group标号以后与后9049条数据的标号进行比较,在本次操作过程中得到准确率为71.54%。
由于本数据集中有些性质考虑到计算机的处理能力问题,所以将变量过多的属性去掉了,而这些属性必然会对最终的结果产生影响,会影响最终的准确率。
之后再利用weka的libsvm分类器对数据进行分类,在此过程中将所有变量纳入考虑范围,采用交叉验证的方式,得到的结果如下图所示:
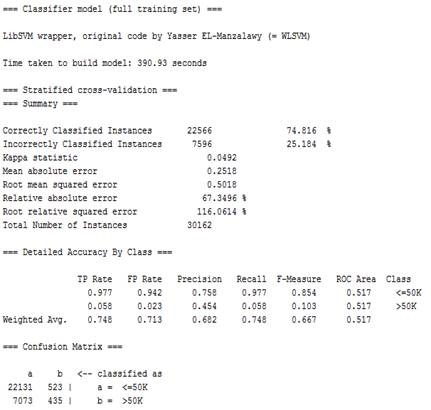
图3.2 libSVM分类结果(weka)
由此可以看出分类的准确率在74.82%左右,比之前利用部分数据属性进行分析得到的准确率略微提高了3%左右。其中,小于50K对的准确率为0.758,召回率为0.977,而>50K的准确率只有0.454,召回率为0.058,因而在>50K的准确率更高。同时用时为390.93秒,训练过程较为复杂,因而所用时间较长。
3.2 神经网络
神经网络是神经系统运转方式的简单模型。其基本单元是神经元,通常将其组织到层
中,如下面的图所示:
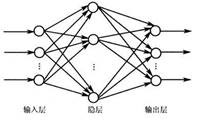
图3.3神经网络模型
神经网络,有时称为多层感知器,本质上是人类大脑处理信息的方式的简化模型。此模
型通过模拟大量类似于神经元的抽象形式的互连简单处理单元而运行。这些处理单元都位于层中。通常在神经网络中有三个部分:一个输入层,其中的单元表示输入字段;一个或多个隐藏层;一个输出层,带有一个或多个表示输出字段的单元。这些单元通过可变的连接强度(或权重)连接。输入数据显示在第一层,其值从每个神经元传播到下一层的每个神经元。最终从输出层中输出结果。该网络可通过以下过程进行学习,即检查单个记录,然后为每个记录生成预测,并且当生成的预测不正确时,对权重进行调整。在满足一个或多个停止标准之前,此过程会不断重复,而网络会持续提高其预测准确度。最初,所有的权重都是随机生成的,并且从网络输出的结果很可能没有意义的。网络可通过训练来学习。向该网络重复应用已知道结果的示例,并将网络给出的结果与已知的结果进行比较。从此比较中得出的信息会传递回网络,并逐渐改变权重。随着训练的进行,该网络对已知结果的复制会变得越来越准确。一旦训练完毕,就可以将网络应用到未知结果的未来案例中。
同样,我们用70%的训练样本训练神经网络模型得到如下模型:
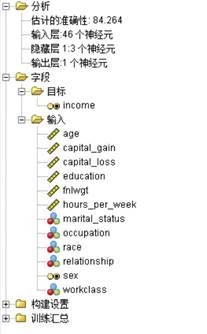
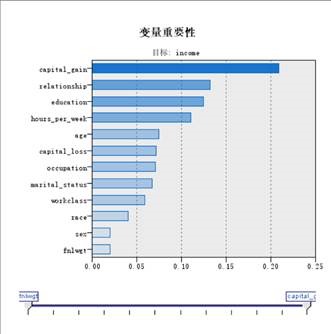
a) b)
图3.4 a)神经网络结构 b)变量重要性(clementine)
左侧是神经网络的结构,右侧是神经网络模型给出的各个变量的重要性,依次是capital_gain
(股票红利基金等)、relationship、eduction、hours_per_week、age等,这是容易理解的。下面是用这个神经网络模型测试30%样本的预测结果:

图3.5 神经网络模型测试结果(clementine)
3.3 决策树
决策树(Decisiontree)一般都是自上而下的来生成的。每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分支画成图形很像一棵树的枝干,故称决策树。
优点:
1) 可以生成可以理解的规则;
2) 计算量相对来说不是很大;
3) 可以处理连续和种类字段;
4) 决策树可以清晰的显示哪些字段比较重要。
缺点:
1) 对连续性的字段比较难预测;
2) 对有时间顺序的数据,需要很多预处理的工作;
3) 当类别太多时,错误可能就会增加的比较快;
4) 一般的算法分类的时候,只是根据一个字段来分类。
基于树的分析的一般用法以下为一些基于树的分析的若干用法:
分段。识别出可能成为特定 分类成员的人员。
分层。将案例归入若干 类别中的一种,如高、中和低风险组。
预测。创建规则并用其预测未来事件。预测还 意味着尝试将预测属性与连续变量值建立联系。
数据缩减和变量筛选。从大型变量集中选择有用的预测变量子集以构建正式的参数模型。
交互识别。识别仅与 特定子组相关的关系,并在正式的参数模型中指定这些关系。
类别合并带状化连续变量。对组预测变量 类别和连续变量以信息丢失最少的方式进行
重编码。
3.3.1随机森林
利用随机森林,对数据进行分类。随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。对于很多种资料,它可以产生高准确度的分类器,可以处理大量的输入变量,同时对于不平衡的分类资料集来说,它可以平衡误差,并且学习过程快速。但是对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的,同时随机森林也被证明在某些噪音较大的分类或回归问题上会产生过拟合的问题。
本次分类试验中,同样选取数据集中70%即21113条案例作为训练案例,剩余的案例作为测试案例,得到如下结果:
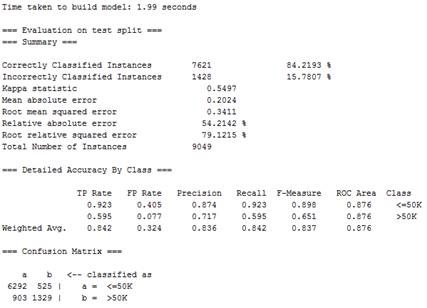
图3.6 随机森林处理结果(weka)
由此可以看出通过随机森林进行分类达到的准确率为84.22%,比利用SVM的准确率提高了10%左右。在<=50K类的准确率为0.874,召回率为0.923,>50K类的准确率为0.717,召回率为0.595。同时整个过程用时为1.99s,处理速度相对于SVM也大规模提升。
3.3.2 C&R算法
分类和回归(C&R)树节点生成可用于预测和分类未来观测值的决策树。该方法通过在每个步骤最大限度降低不纯洁度,使用递归分区来将训练记录分割为组。如果节点中100%的观测值都属于目标字段的一个特定类别,则该节点将被认定为“纯洁”。目标和预测变量字段可以是范围字段,也可以是分类字段;所有分割均为二元分割(即分割为两组)
分类回归树优点:
(1) 可自动忽略对目标变量没有贡献的属性变量,也为判断属性变量的重要性,减少变量数据提供参考;
(2) 在面对诸如存在缺失值、变量数多等问题时C&RT 显得非常稳健(robust);
(3) 估计模型通常不用花费很长的训练时间;
(4) 推理过程完全依据属性变量的取值特点(与C5.0不同,C&RT的输出字段既可以是数值型,也可以是分类型)
(5) 比其他模型更易于理解——从模型中得到的规则能得到非常直观的解释,决策推理过程可以表示成IF…THEN的形式
(6) 目标是定类变量为分类树,若目标变量是定距变量,则为回归树;
(7) 通过检测输入字段,通过度量各个划分产生的异质性的减小程度,找到最佳的一个划分。
(8) 非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成本复杂性剪枝来得到归纳性更强的树。
我们70%的数据做为训练样本训练模型。得到如下决策树:
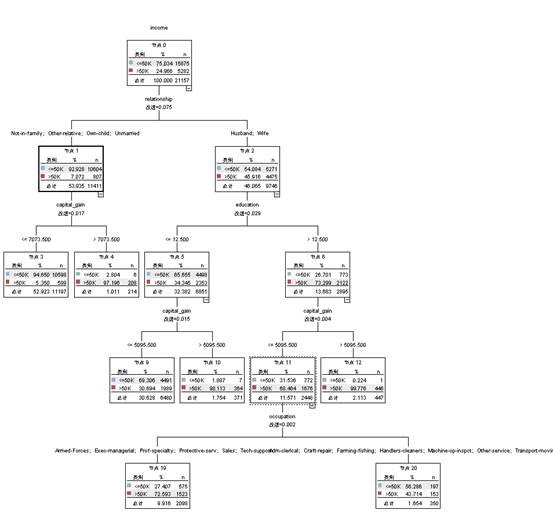
图3.7决策树模型(clementine)
将训练好的C&R模型用来测试30%的测试集,可得到如下的分析结果:
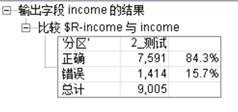
图3.8决策树模型测试结果(clementine)
可见模型预测的income是否大于50k的值和实际值的准确率为84.3%。
3.3.3 C5.0算法
C5.0算法构建决策树或规则集。该模型的工作原理是基于产生最大信息增益的字段逐级分割样本。目标字段必须为分类字段。允许进行多次多于两个子组的分割。C5.0模型的工作原理是根据提供最大信息增益的字段分割样本。然后通常会根据不同的字段再次分割由第一次分割定义的每个子样本,且此过程会重复下去直到无法继续分割子样本。最后,将重新检查最底层分割,并删除或修剪对模型值没有显著贡献的分割。
决策树是对由算法建立的分割的简单描述。每个终端(或“叶”)节点可描述训练数据的特定子集,而训练数据中的每个观测值都完全属于树中的某个终端节点。换句话说,对于在决策树中显示的任何特定数据记录,仅可能有一个预测。反过来,规则集则是尝试对单个记录进行预测的一组规则。规则集源自决策树,并且在某种程度上表示在决策树中建立的经简化或提取的信息版本。通常,规则集可保留完整的决策树中的大部分重要信息,但其使用的模型比较简单。由于规则集的这种工作方式,其属性与决策树的属性不同。最重要的区别是,使用规则集时,可以为任意特定记录应用多个规则,也可以不应用任何规则。如果应用多个规则,则每个规则将根据与此规则关联的置信度获得一个加权“投票”,并通过组合应用到所讨论记录的所有规则的加权投票来确定最终的预测。如果没有规则可应用,则会将默认预测分配到该记录。
同样用70%的训练集样本训练模型,然后再用30%的样本测试样本测试得到如下分析结果:
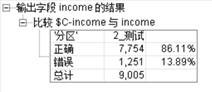
图3.9 C5.0算法测试结果(clementine)
可见,C5.0算法对预测样本达到了86.11%的准确度,超出了上面其他算法。
3.4 朴素贝叶斯
朴素贝叶斯分类器发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,朴素贝叶斯分类器模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,朴素贝叶斯分类器模型与其他分类方法相比具有最小的误差率,但是朴素贝叶斯分类器假设所有特征值都互相独立,这在实际案例中很少成立,因而会对最终的分类结果产生印象。
在利用朴素贝叶斯分类器进行分类时,和上述分类方式一样,同样选择数据集中70%作为训练样本,即一共有21113条案例作为训练样本,而剩余的30%的数据作为测试样本,得到的结果如下图所示:
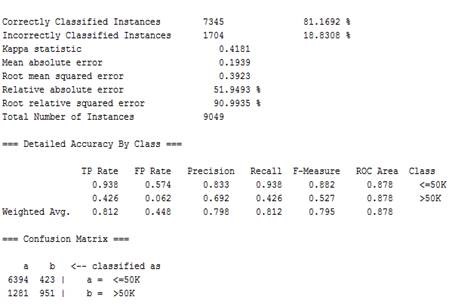
图3.10 朴素贝叶斯分类结果(weka)
由此可以看出准确率为81.17%,在<=50K类的准确率为0.833,召回率为0.938,>50K类的准确率为0.692,召回率为0.426。由于朴素贝叶斯分类器模型假设属性之间相互独立,但是这个假设很多情况下往往是不成立的,这给朴素贝叶斯分类器模型的正确分类带来了一定影响,而在本次分类计算中,这些参数之间必然存在相互依赖关系,所以会对最终的分类效果产生影响。
3.5 Logistic回归
Logistic回归(也称为名义回归)是一种用于依据输入字段的值对记录进行分类的统计技术。这种技术与线性回归类似,但用分类目标字段代替了数值字段。同时支持二项模型(用于具有两种离散类别的目标)和多项模型(用于具有两种以上类别的目标)。Logistic回归的工作原理是构建一组方程式,使输入字段值与每个输入字段类别所关联的概率相关。生成模型后,便可以用它来估计新数据的概率。对于每条记录,将计算每种可能输出类别的归属概率。具有最高概率的目标类别将被指定为该记录的预测输出值。
同样的我们用70%的训练样本建立回归方程:



图3.11 Logistic回归方程(clementine)
上面是用70%的Logistic回归建立的回归方程,我们将它用于测试30%的测试样本得到如下结果:

图3.12 Logistic回归测试结果(clementine)
3.6 分类总结
我们将样本分成70%的训练集和30%的测试集,训练样本进行模型训练,测试样本对训练好的模型进行检验。我们用了多种方法进行了建模,支持向量机、神经网络、决策树、朴素贝叶斯、Logistic回归等,我们对他们的性能进行了如下图的综合比较:
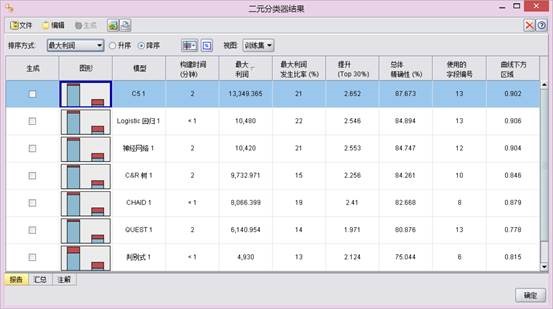
图3.13 各模型综合比较(clementine)
由上图可见C5决策树算法最高达到了87%的准确度,其次是Logistic回归和神经网络。可以看到每种方法都有其优点,神经网络很好的给出了变量重要性,Logistic回归给出了预测模型的显式表达。在不同的数据集中应采用恰当的适用的方法对其进行数据分析。
4.关联规则
关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。对特征值之间相互关系的分析,可以更好的了解数据集,更能理解上述影响上述分类结果的条件因素。
4.1、Apriori算法
利用Apriori对数据进行分析,Apriori算法是一种挖掘关联规则的频繁项集算法,其核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集。而且算法已经被广泛的应用到商业、网络安全等各个领域。本实验过程中利用Apriori算法,对属性间存在的相关关系进行挖掘,得到属性间的相互关系,从而更好地了解数据集特点。基于上述分析考虑,在进行关联规则分析时,只考虑workclass,fnlwgt,marital status,occupation,sex,hours per week,income。设置Apriori的相关参数如下图所示:

图4.1 Apriori参数设置
从而得到相应的最佳十条关联结果如下图4.2所示:

图4.2 Apriori结果
从上述结果中可以发现大多数单身即从未结过婚的年收入都会小于等于50K,因而可以考虑到婚姻状况和年收入之间存在一定关联因素,同时从事Craft-repair工作的和男性性别也有一定的相关性,从事Other service职业的收入一般会小于50K,收入相对较少。根据上述分析,结合实际生活规律,可以考虑到人们选择结婚对象时收入是一个重要因素,或者是稳定的婚姻状况可以帮助人们在事业上获得更好的待遇。
根据图1.1所示的情况,也可以看出教育程度对于最终的收入也会产生一定影响,当教育程度非常高时达到master,即教育年限达到14年以上绝大多数的人的收入都超过了50K,良好的教育会在一定程度提高收入水平。
4.2、广义规则归纳(GRI)算法
GRI规则的形式:If Y=y then X=x with probability p,其中X和Y是两个指标,x和y是两个指标的值,then前面的是条件,后面的是结果。符合条件的规则将按一定顺序选入规则集表中。
实例(Instances):条件为真的记录数。
支持度(support):实例占总记录数的比例,衡量规则的重要性。
可信度:或叫置信度。条件和结果都为真的记录数,占实例的比例,衡量规则的准确度。
作用度(lift):条件概率与无条件概率的比值。作用度越大,实际意义越好。
规则的选取:
(1)只有真值才能被选入,条件和结果含有假的规则都不能被选入。
(2)只有规则的支持度和可信度超过特定的阈值,才能被选入规则表中。
(3)条件的记录数不能超过特定值,否则也不能被选入规则。
(4)被选入规则表中的规则数是有限的。
我们用GRI规则对样本进行关联建模,得到如下结果:
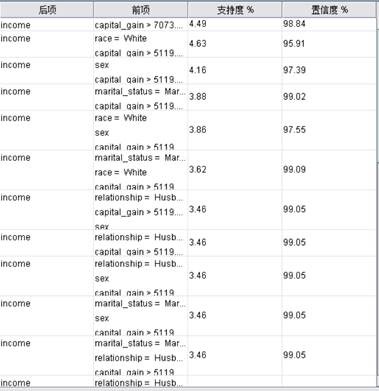
图4.3 GRI结果(clementine)
上面的结果显式是可以理解的,当某人的capital_gain比较大时,说明此人的资本增值如股票收益、基金、分红等比较高,那么他的年收入大于50k是很有可能的,我们将capital_gain这一项去掉分析其他的有可能对收入影响的因素,得到如下结果:
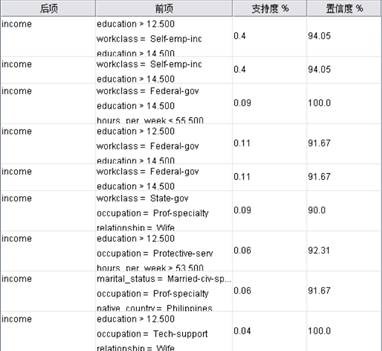
图4.4 capital以外其他输入GRI预测结果(clementine)
可见education比较高的都很大的可能收入比较高,另外self-emp-inc(自由股份公司参与者)和federal-gov联邦政府工作的人员年收入大于50k的可能性比较高,这也是可以理解的。
利用weka和clementine数据挖掘举例的更多相关文章
- data Mining with Weka: Trailer More Data Mining with Weka 用weka 进行数据挖掘 Weka 用weka 进行更多数据挖掘
https://www.youtube.com/user/WekaMOOC 大学公开课 视频教程 weka 入门教程 data Mining with Weka: Trailer More Dat ...
- 第一周-调用weka算法进行数据挖掘
第一周-调用weka算法进行数据挖掘 简单数据集data.txt @relation weather @attribute outlook {sunny, overcast, rainy} @attr ...
- ELK学习笔记之F5利用EELK进行应用数据挖掘系列(2)-DNS
0x00 概述 很多客户使用GTM/DNS为企业业务提供动态智能解析,解决应用就近性访问.优选问题.对于已经实施多数据中心双活的客户,则会使用GSLB提供双活流量调度.DNS作为企业业务访问的指路者, ...
- SPSS Clementine 数据挖掘入门3
转摘:http://www.cnblogs.com/dekevin/archive/2012/04/27/2473683.html 了解SPSS Clementine的基本应用后,再对比微软的SSAS ...
- SPSS Clementine 数据挖掘入门1
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具.在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS.SAS获得了最高ability to e ...
- ELK学习笔记之F5利用ELK进行应用数据挖掘系列(1)-HTTP
0x00 概述 F5 BIGIP从应用角度位于网络结构的关键咽喉位置,可获取所有应用的流量,针对流量执行L7层处理,即便是TLS加密的流量也可以通过F5进行SSL offload.通过F5可以统一获取 ...
- SPSS Clementine 数据挖掘入门2
下面使用Adventure Works数据库中的Target Mail作例子,通过建立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入. Target Mail数据在SQL ...
- 利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I ...
- 【数据挖掘】朴素贝叶斯算法计算ROC曲线的面积
题记: 近来关于数据挖掘学习过程中,学习到朴素贝叶斯运算ROC曲线.也是本节实验课题,roc曲线的计算原理以及如果统计TP.FP.TN.FN.TPR.FPR.ROC面积等等.往往运用 ...
随机推荐
- Flex 调用webService
今天手头没事,就学习下 Flex 调用webService的方法.本地测试OK 和大家分享下. ——————————————————————————————————————————————————— ...
- BZOJ 1710: [Usaco2007 Open]Cheappal 廉价回文
Description 为了跟踪所有的牛,农夫JOHN在农场上装了一套自动系统. 他给了每一个头牛一个电子牌号 当牛走过这个系统时,牛的名字将被自动读入. 每一头牛的电子名字是一个长度为M (1 &l ...
- PDF、WORD、PPT、TXT转换方法
- WPF MultiDataTrigger
huhu <Style x:Key="Cell" TargetType="{x:Type Button}"> <Setter Property ...
- setTimeout浅析
刚学习javascript的时候,感觉setTimeout很好理解,不就是过n(传入的毫秒数)毫秒,执行以下传入的函数吗?这个理解伴随了我挺长的一段时间,才对setTimeout有了新的认识,请先看下 ...
- uva 10940
数学 打了个表 找一下规律.... #include <cstdio> int a[30]; void init() { a[1]=2;a[2]=4;a[3]=8;a[4]=16;a[5] ...
- 【leetcode】Longest Substring Without Repeating Characters (middle)
Given a string, find the length of the longest substring without repeating characters. For example, ...
- linux ubuntu 11.04 samba 服务器设置
安装 SAMBA 组件 sudo apt-get install samba smbfs smbclient 配置相关参数 sudo gedit /etc/samba/smb.conf 文件中相关 ...
- java String.split方法是用注意点(转)
转自:http://www.blogjava.net/fanyingjie/archive/2010/08/05/328059.html 在java.lang包中有String.split()方法,返 ...
- ASP.net 判断上传文件类型的三种方法
一. 安全性比较低,把文本文件1.txt改成1.jpg照样可以上传,但其实现方法容易理解,实现也简单,所以网上很多还是采取这种方法. Boolean fileOk = false; string pa ...