第1节 flume:12、flume的load_balance实现机制
1.5、flume的负载均衡load balancer
负载均衡是用于解决一台机器(一个进程)无法解决所有请求而产生的一种算法。Load balancing Sink Processor 能够实现 load balance 功能,如下图Agent1 是一个路由节点,负责将 Channel 暂存的 Event 均衡到对应的多个 Sink组件上,而每个 Sink 组件分别连接到一个独立的 Agent 上,示例配置,如下所示:
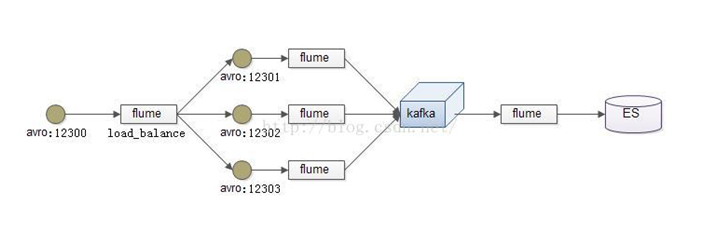
在此处我们通过三台机器来进行模拟flume的负载均衡
三台机器规划如下:
node01:采集数据,发送到node02和node03机器上去
node02:接收node01的部分数据
node03:接收node01的部分数据
第一步:开发node01服务器的flume配置
node01服务器配置:
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_balancer_client.conf
#agent name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 k2
#set gruop
a1.sinkgroups = g1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
# set sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node02
a1.sinks.k1.port = 52020
# set sink2
a1.sinks.k2.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node03
a1.sinks.k2.port = 52020
#set sink group
a1.sinkgroups.g1.sinks = k1 k2
#set failover
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
第二步:开发node02服务器的flume配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:开发node03服务器flume配置
node03服务器配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第四步:准备启动flume服务
启动node03的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node02的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node01的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_client.conf -Dflume.root.logger=DEBUG,console
第五步:node01服务器运行脚本产生数据
cd /export/servers/shells
sh tail-file.sh
第1节 flume:12、flume的load_balance实现机制的更多相关文章
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- 12.Flume的安装
先把flume包上传并解压 给flume创建一个软链接 给flume配置环境变量 #flume export FLUME_HOME=/opt/modules/flume export PATH=$PA ...
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
- Flume学习——Flume的架构
Flume有三个组件:Source.Channel 和 Sink.在源码中对应同名的三个接口. When a Flume source receives an event, it stores it ...
- 【Flume】flume于transactionCapacity和batchSize进行详细的分析和质疑的概念
我不知道你用flume读者熟悉无论这两个概念 一开始我是有点困惑,? 没感觉到transactionCapacity的作用啊? batchSize又是干啥的啊? -- -- 带着这些问题,我们深入源代 ...
随机推荐
- ai技术体系
- ue4 动态增删查改 actor,bp
ue4.17 增 特殊说明:创建bp时,如果bp上随手绑一个cube,那么生成到场景的actor只执行构造不执行beginPlay,原因未知 ATPlayerPawn是c++类 直接动态创建actor ...
- ue4 杂记
c++获取GameMode if(GetWorld()) { auto gamemode = (ASomeGameMode*)GetWorld()->GetAuthGameMode(); } 或 ...
- 加权并查集(银河英雄传说,Cube Stacking)
洛谷P1196 银河英雄传说 题目描述 公元五八○一年,地球居民迁移至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展.宇宙历七九九年,银河系的两大军事集团在 ...
- Python读写Excel表格
最近在做一些数据处理和计算的工作,因为数据是以.CSV格式保存的,因此刚开始直接用Excel来处理. 但是做着做着发现重复的劳动,其实并没有多大的意义,于是就想着写个小工具帮着处理. 以前正好在一本书 ...
- EOS Bios Boot Sequence
EOS version:v1.0.5 Date:2018-06-19 Host: Centos 7 Reference :https://github.com/EOSIO/eos/wiki/Tutor ...
- Java获取路径
"./" 代表当前目录,"../"代表上级目录 后续更新!!!
- 微服务的.NET Core示例框架
eShopOnContainers 是一个基于微服务的.NET Core示例框架 https://www.cnblogs.com/fengqingyangNo1/p/9438428.html 找到一个 ...
- 每天学点Linux命令之grep 和 wc命令 --- !管道命令!
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expr ession Print,表示全局正则表 ...
- Win10+VirtualBox+Openstack Mitaka
首先VirtualBox安装的话,没有什么可演示的,去官网(https://www.virtualbox.org/wiki/Downloads)下载,或者可以去(https://www.virtual ...