Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要
02 内容回顾和补充:scrapy
03 内容回顾和补充:网络和并发编程
04 Scrapy爬虫框架:pipeline做持久化(一)
05 Scrapy爬虫框架:pipeline做持久化(二)
06 Scrapy爬虫框架:dupefilter做去重(一)
07 Scrapy爬虫框架:dupefilter做去重(二)
08 Scrapy爬虫框架:depth深度控制
09 Scrapy爬虫框架:手动处理cookie
01 今日内容概要
1.1 围绕Scrapy框架;
1.1.1 pipeline和items实现持久化;
1.1.2 去重规则;
1.1.3 cookie;
1.1.4 下载中间件middleware;
1.1.5 Scrapy的结构图;
1.1.6 深度(优先级);
02 内容回顾和补充:scrapy
2.1 Scrapy框架;
2.1.1 依赖Twisted,帮助我们下载页面,内部基于事件循环的机制,实现爬虫的并发;
2.1.2
''' '''
'''
非阻塞,不等待;
异步,回调;
事件循环;
##############基于事件循环的异步非阻塞模块;##############################
一个线程同时可以向多个目标发起http请求;
import socket
sk = socket.socket()
sk.setblocking(False)
sk.connect((1.1.1.1:80)) sk = socket.socket()
sk.setblocking(False)
sk.connect((1.1.1.1:80)) sk = socket.socket()
sk.setblocking(False)
sk.connect((1.1.1.1:80)) sk = socket.socket()
sk.setblocking(False)
sk.connect((1.1.1.1:80))
'''
# 原来的你;
'''
import requests url_list = ['http://www.baidu.com', 'http://www.jd.com', 'http://www.mi.com', ] for item in url_list:
response = requests.get(
url=item
)
print(response.text)
'''
# 现在的你;
from twisted.web.client import getPage, defer
from twisted.internet import reactor # 第一部分,代理开始接收任务; def callback(contents):
print(contents) deferred_list = [] url_list = ['https://www.bing.com', 'https://segmentfault.com/', 'https://www.stackoverflow.com', ] for url in url_list:
deferred = getPage(bytes(url, encoding='utf8'))
deferred.addCallback(callback)
deferred_list.append(deferred)
# 第二部分:代理完成任务后,停止;
dlist = defer.DeferredList(deferred_list) def all_done(arg):
reactor.stop() dlist.addBoth(all_done)
# 第三部分,代理开始去处理吧;
reactor.run()
03 内容回顾和补充:网络和并发编程
3.1 OSI七层模型,或5层模型;
3.2 三次握手、四次挥手;
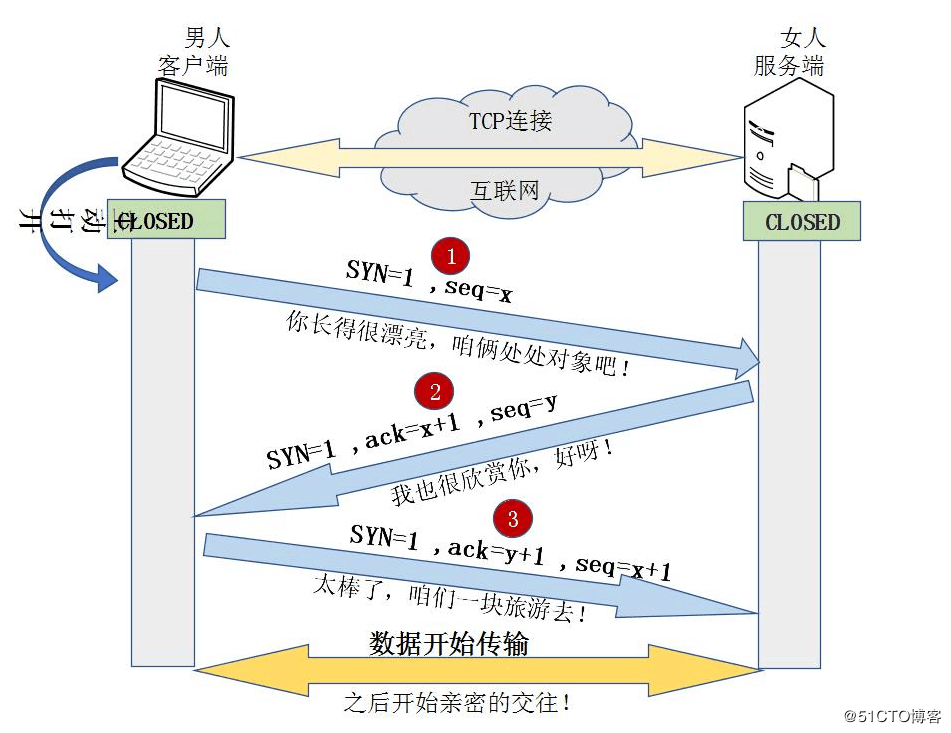
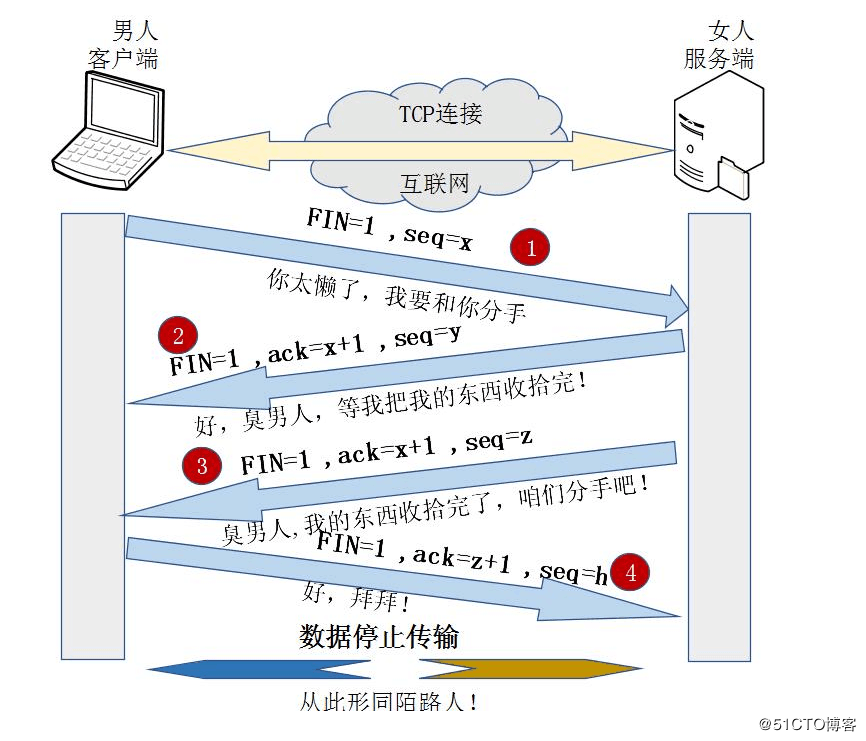
3.3 TCP和UDP的区别;
- TCP-打电话
- UDP-对讲机
3.4 路由器和交换机的区别;
- 交换机可以在局域网进行通信;
- 路由器跨局域网通信;
3.5 ARP协议——地址解析协议,解析IP和MAC地址的关系;联想DNS服务器;
3.6 HTTP与HTTPS——HTTPS = HTTP + SSL/TLS
3.7 进程、线程和协程的区别;
- 一个应用程序就是一个软件,一个软件中可以有多个进程;一个进程中可以有多个线程;
- CPU工作的最小单元是线程;
- 一个进程可以存在多个线程;
- 对于一个进程来说,共享一块内存;进程与进程之间的数据是隔离的;
- 协程就是微线程,协程不是真实存在的,是人为创建的;计算性任务不会快,有可能会慢,但IO和非阻塞是快的;
一、进程与线程 1.进程 我们电脑的应用程序,都是进程,假设我们用的电脑是单核的,cpu同时只能执行一个进程。当程序处于I/O阻塞的时候,CPU如果和程序一起等待,那就太浪费了,cpu会去执行其他的程序,此时就涉及到切换,切换前要保存上一个程序运行的状态,才能恢复,所以就需要有个东西来记录这个东西,就可以引出进程的概念了。 进程就是一个程序在一个数据集上的一次动态执行过程。进程由程序,数据集,进程控制块三部分组成。程序用来描述进程哪些功能以及如何完成;数据集是程序执行过程中所使用的资源;进程控制块用来保存程序运行的状态 2.线程 一个进程中可以开多个线程,为什么要有进程,而不做成线程呢?因为一个程序中,线程共享一套数据,如果都做成进程,每个进程独占一块内存,那这套数据就要复制好几份给每个程序,不合理,所以有了线程。 线程又叫轻量级进程,是一个基本的cpu执行单元,也是程序执行过程中的最小单元。一个进程最少也会有一个主线程,在主线程中通过threading模块,在开子线程 3.进程线程的关系 (1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程 (2)资源分配给进程,进程是程序的主体,同一进程的所有线程共享该进程的所有资源 (3)cpu分配给线程,即真正在cpu上运行的是线程 (4)线程是最小的执行单元,进程是最小的资源管理单元 4.并行和并发
并行处理是指计算机系统中能同时执行两个或多个任务的计算方法,并行处理可同时工作于同一程序的不同方面 并发处理是同一时间段内有几个程序都在一个cpu中处于运行状态,但任一时刻只有一个程序在cpu上运行。 并发的重点在于有处理多个任务的能力,不一定要同时;而并行的重点在于就是有同时处理多个任务的能力。并行是并发的子集
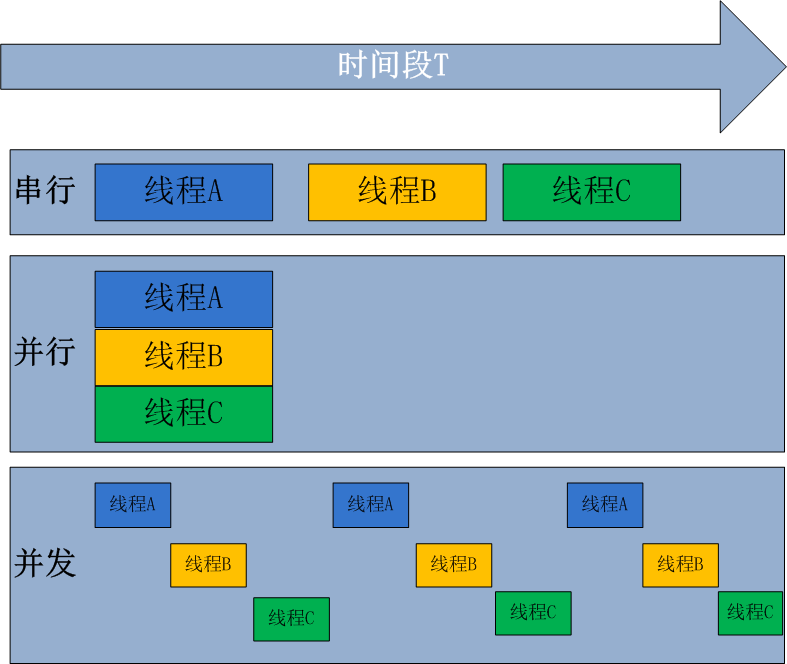
3.8 GIL锁(全局解释器锁),保证同一个进程在同一个时刻只有一个线程被CPU调用执行,只能一个程度上保证数据安全;
3.8.1 为了保证数据安全,自己加锁处理;
3.9 进程之间如何共享?
- queue
- pipe
- manager
04 Scrapy爬虫框架:pipeline做持久化(一)
4.1 pipeline/items
4.1.1 先写pipeline类;
4.1.2 写Item类;
4.1.3 settings.py中配置ITEM_PIPELINES;
4.1.4 爬虫yield 每执行一次,pipeline就执行一次;
4.2 pipeline是所有爬虫公用的,如果想要给某个爬虫定制需要使用spider参数进行处理;
05 Scrapy爬虫框架:pipeline做持久化(二)
5.1 去重规则
06 Scrapy爬虫框架:dupefilter做去重(一)
07 Scrapy爬虫框架:dupefilter做去重(二)
08 Scrapy爬虫框架:depth深度控制
09 Scrapy爬虫框架:手动处理cookie
Python-S9-Day126——Scrapy爬虫框架的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python的两个爬虫框架PySpider与Scrapy安装
Python的两个爬虫框架PySpider与Scrapy安装 win10安装pyspider: 最好以管理员身份运行CMD,不然可能会出现拒绝访问文件夹的情况! pyspider:pip instal ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- TP5.0:的安装与配置
在网址中输入:localhost/安装TP5的文件夹/public/ 入口文件位置:public/index.php: 最新版本中,新建的文件夹是没有模型和视图的,需要自行添加没有的文件: 添加前: ...
- CSS样式表优化
前几天公司要模仿一家客户的网站模板来为另一客户新建一个模板,说白了就是换个数据源,然后样式表再小修小改一下就行了.但通过浏览器控制台下载素材时,发现这个网站开发的挺专业的,单就样式表而言,代码工整,注 ...
- win10 U盘重装
之前用一键重装软件装系统后,D盘留下了一个PE系统,后来我装双系统装好Ubuntu后,打开Ubuntu结果出现了那个PE系统,最后没办法只好重装win10. 重装系统主要有三种方法,参见:链接 因为电 ...
- linux 命令——14 head (转)
head 与 tail 就像它的名字一样的浅显易懂,它是用来显示开头或结尾某个数量的文字区块,head 用来显示档案的开头至标准输出中,而 tail 想当然尔就是看档案的结尾. 1.命令格式: hea ...
- Android(java)学习笔记79:Android中SimpleAdapter,ArrayAdapter和BaseAdapter常见的适配器
1. SimpleAdapter(BaseAdapter子类扩展类): simpleAdapter的扩展性最好,可以定义各种各样的布局出来,可以放上ImageView(图片)等.可以显示比较复杂的列表 ...
- Problem K: 搜索基础之棋盘问题
Problem K: 搜索基础之棋盘问题 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 92 Solved: 53[Submit][Status][W ...
- oc不可变数组创建
//创建数组 //1.快速创建数组 @[] NSArray *week=@[@"MON",@"TUE",@"WED",@"THU ...
- 1048: [HAOI2007]分割矩阵
Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1184 Solved: 863[Submit][Status][Discuss] Descripti ...
- <%%>用法初步认识
<%%>是用于向客户端插入服务器代码所使用的一种标记 例如为了在HTML页面上展示由服务器提供的当前用户的某条信息或名字等便可使用 前台 <a href="home.asp ...
- goaccess 安装
今天尝试搭建goaccess,用于分析access.log文件,但安装并不顺利,小记一下自己遇到的问题及解决方法 系统环境:CentOS release 6.9 一.参照官网教程进行搭建 $ wget ...