Hadoop分布式系统的安装部署
1、关于虚拟机的复制
新建一台虚拟机,系统为CentOS7,再克隆两台,组成一个三台机器的小集群。正常情况下一般需要五台机器(一个Name节点,一个SecondName节点,三个Data节点。)
此外,为了使网络生效,需要注意以下几点:
1> 编辑网络配置文件
/etc/sysconfig/network-scripts/ifcfg-eno16777736
先前的版本需要删除mac地址行,注意不是uuid,而是hwaddr,这一点新的CentOS不再需要
2> 删除网卡和mac地址绑定文件
rm -rf /etc/udev/rules.d/-persistent-net.rules
3> 重启动系统
此外,mapreduce在运行的时候可能会随机开放端口,在CentOS7中,可以使用下面的命令将防火墙关闭
systemctl stop firewalld
或者使用下面的命令,使在集群中的机器可以不受限制的互相访问
#把一个源地址加入白名单,以便允许来自这个源地址的所有连接
firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.1.215" accept' --permanent
firewall-cmd --reload
2、将IP地址设置为静态
准备了三个IP地址
192.168.1.215
192.168.1.218
192.168.1.219
在CentOS7下,修改ip地址的文件为/etc/sysconfig/network-scripts/ifcfg-eno16777736
主要作如下设置,其他的不需要变
# none或static表示静态
OOTPROTO=static
# 是否随网络服务启动
ONBOOT=yes
IPADDR=192.168.1.215
# 子网掩码
NETMASK=255.255.255.0
# 网关,设置自己的
GATEWAY=192.168.0.1
# dns
DNS1=202.106.0.20
3、修改hostname与hosts文件
这两个文件均处于系统根目录的etc文件夹之中
下图显示了映射后的机器名称以及对应的ip地址(#localhost.localdomain这一行多余,仅master刚刚好)
主节点master,两个数据节点data1,data2

4、添加用户与组
需要为Hadoop软件系统设置单独的用户和组,本例中新添加的用户和所属组的名称均为hadoop
adduser hadoop
passwd hadoop
5、利用ssh实现免密码登录
注意,目的是使Hadoop系统的所属用户在集群之间实现免密码登录,而不是root用户(除非Hadoop系统的所有者root,但一般不建议这么做)。这一点非常重要。
在本例中,软件所有者是上面新建的hadoop用户,密钥也要由hadoop用户来生成。
1> 更改配置文件
需要对sshd_config文件进行修改,主要是以下三项,取消注释即可
vim /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
之后,执行以下命令重启sshd服务
service sshd restart
2> 生成密钥并分发相关文件
简单的方法,密钥生成后,使用直接使用 ssh-copy-id 命令把密钥追加到远程主机的 .ssh/authorized_key 上,如下:
# 生成密钥
ssh-keygen -t rsa
# 密钥追加到远程主机
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.1.218
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@data2
复杂的方法,不再推荐,具体实现步骤如下:
a> 将三台计算机(master、data1、data2)分别切换到hadoop用户下,并分别cd到hadoop用户的家目录,然后执行 ssh-keygen -t rsa 命令,这样的结果,是在各自家目录的.ssh文件夹中生成了对应的id_rsa.pub 与id_rsa 密钥对。
b> 将data1(192.168.1.218),data2(192.168.1.219)两台计算机中的公钥文件复制到master(192.168.1.215)中,并重命名为id_rsa.pub218,id_rsa.pub219,置于hadoop用户家目录下的.ssh文件夹下。命令参考如下:
scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub218
scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub219
hadoop@master表示用master中的hadoop用户登录master
这样以来,master主机hadoop用户的.ssh文件夹就有了以下三个公钥文件:
d_rsa.pub、d_rsa.pub218、d_rsa.pub218
c> 在master中,将以上三个文件以追加的形式写入authorized_keys文件,这些文件均位于hadoop用户.ssh文件夹中。
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub218 >> authorized_keys
cat id_rsa.pub219 >> authorized_keys
d> 更改 authorized_keys 文件的权限。这一步也可在分发后单独进行。
chmod authorized_keys
e> 分发authorized_keys 文件到data1,data2中hadoop用户的.ssh文件中,并再次检查权限。
scp authorized_keys hadoop@data1:~/.ssh/authorized_keys
scp authorized_keys hadoop@data2:~/.ssh/authorized_keys
之后就可以在小集群中使用hadoop用户实现免密码登录了。
注意的是,如果使用的linux登录用户不是root用户,需要修改以下.ssh文件夹以及authorized_key文件的权限,否则是无法实现免密码登录的
chmod .ssh
cd .ssh/
chmod authorized_keys
6、安装jdk
先在master中安装,之后分发,这里使用的是jdk-8u112-linux-x64.tar.gz
1> 解压安装
首先需要切换到root用户
su root
cd /usr
mkdir java
tar -zxvf jdk-8u112-linux-x64.tar.gz ./java
ln -s jdk1..0_112/ jdk
2> 分发
scp -r /usr/java root@data2:/usr/
scp -r /usr/java root@data2:/usr/
3> 设置环境变量,三台都要设置
vim /etc/profile
export JAVA_HOME=/usr/java/jdk
export JRE_HOME=/usr/java/jdk/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile

7、安装hadoop
先在master下安装,再分发
安装的版本为2.6.5解压安装到/usr/Apache/目录下,并建立软连接
Hadoop所有配置文件的目录位于/usr/Apache/hadoop-2.6.5/etc/hadoop下,由于建立了一个软连接,所以/usr/Apache/hadoop/etc/hadoop是一样的
在hadoop软件目录的dfs文件夹中创建三个子文件夹name、data、tmp,下面属性的设置会用到,注意其所有者和所属组。
以下是配置文件的设置:
1> hdfs.site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/Apache/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/Apache/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2> mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
3> yarn-site.xml
设置如下:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
4> slaves配置文件
master
data1
data2
注:本例将master也作为了一个数据节点
5> hadoop-env.sh和yarn-env.sh
这是两个相当重要的环境变量配置文件,由于目前仅安装Hadoop,所以仅设置jdk即可,其他默认。
export JAVA_HOME=/usr/java/jdk
6> core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/Apache/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
7> 将Apache文件夹分发到data1,data2对应的目录下
# 分发
scp -r ./Apache root@data1:/usr/
scp -r ./Apache root@data2:/usr/ # 这里使用了root用户,记得分发后要改所有者与所属组
chown -R hadoop:hadoop Apache/
注意jdk是不需要改所有者与所属组的,因为通用
8> 三台机器分别配置hadoop用户的.bashrc文件,设置环境变量
su hadoop
vim ~/.bashrc
export $HADOOP_HOME=/usr/Apache/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
8、开启与结束
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
yarn-daemon.sh start historyserver
#####
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
yarn-daemon.sh stop historyserver
9、运行结果
相关进程


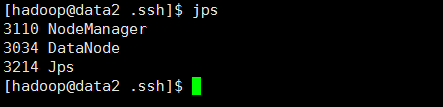
All Applications
http://192.168.1.215:8088
JobHistory
http://192.168.1.215:19888
Master
http://192.168.1.215:50070

Hadoop分布式系统的安装部署的更多相关文章
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- hadoop 2.5 安装部署
hadoop 下载地址:http://mirrors.cnnic.cn/apache/hadoop/common/ 单机伪分布 配置文件: /hadoop-2.5.1/etc/hadoop/ hado ...
- hadoop HA架构安装部署(QJM HA)
###################HDFS High Availability Using the Quorum Journal Manager########################## ...
- hadoop完全分布式安装部署-笔记
规划: [hadoop@db01 ~]$ cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4 ...
- Hadoop+Hbas完全分布式安装部署
Hadoop安装部署基本步骤: 1.安装jdk,配置环境变量. jdk可以去网上自行下载,环境变量如下: 编辑 vim /etc/profile 文件,添加如下内容: export JAVA_HO ...
- 初学者值得拥有【Hadoop伪分布式模式安装部署】
目录 1.了解单机模式与伪分布模式有何区别 2.安装好单机模式的Hadoop 3.修改Hadoop配置文件---五个核心配置文件 (1)hadoop-env.sh 1.到hadoop目录中 2.修 ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- hadoop入门(3)——hadoop2.0理论基础:安装部署方法
一.hadoop2.0安装部署流程 1.自动安装部署:Ambari.Minos(小米).Cloudera Manager(收费) 2.使用RPM包安装部署:Apache ...
随机推荐
- SQL Server 服务器磁盘测试之SQLIO篇(二)
上次放出了一篇文章,针对磁盘卷簇大小默认4KB和自定义64KB进行了测试,测试内容为随机和顺序读写,大小为8KB和64KB,有人觉得这并没有照顾到SQL Server所有的IO使用情景.这篇测试文章, ...
- Javascript之匿名函数
分析: 1.所谓匿名函数,从字面意思理解,就是没有名字的函数,js 用()来代替(注意,是英文状态下的括号) 2.定义形式: function (){ //to add codes that you ...
- Java发送Http请求并获取状态码
通过Java发送url请求,查看该url是否有效,这时我们可以通过获取状态码来判断. try { URL u = new URL("http://10.1.2.8:8080/fqz/page ...
- Java发展历史
1991年1月 Sun公司成立了Green项目小组,专攻智能家电的嵌入式控制系统 1991年2月 放弃C++,开发新语言,命名为"Oak" 1991年6月 JamesGosling ...
- PHP MVC 架构
PHP高级程序设计 学习笔记 2014.06.18 MVC (Model-View-Controller,模型-视图-控制器)是一种可以简化应用程序开发和维护的非常常用的设计模式.它从逻辑上把应用程序 ...
- Tcl internal variables
Tcl internal variables eryar@163.com 在Tcl中内置了一些变量,并赋予了一定的功能.内置变量列表如下: 变量名称 功能描述 argc 指命令行参数的个数. argv ...
- Android总结之Gzip/Zip压缩
前言: 做过Android网络开发的都知道,在网络传输中我们一般都会开启GZIP压缩,但是出于刨根问底的天性仅仅知道如何开启就不能满足俺的好奇心的,所以想着写个demo测试一下比较常用的两个数据压缩方 ...
- Cocoa深入学习:NSOperationQueue、NSRunLoop和线程安全 (转)
目前在 iOS 和 OS X 中有两套先进的同步 API 可供我们使用:NSOperation 和 GCD .其中 GCD 是基于 C 的底层的 API ,而 NSOperation 则是 GCD 实 ...
- ASP.NET Core 中文文档 第二章 指南(4.5)使用 SQL Server LocalDB
原文:Working with SQL Server LocalDB 作者:Rick Anderson 翻译: 魏美娟(初见) 校对: 孟帅洋(书缘).张硕(Apple).许登洋(Seay) Appl ...
- Windows Phone Toolkit 的 DatePicker 控件本地化的问题
用到 The Windows Phone Toolkit 里的 DatePicker 控件,但是多语言的时候出现了问题: 手机设置为中文,虽然月份跟星期有效,但是 Title 却还是默认的语言:CHO ...