【集合框架】JDK1.8源码分析之LinkedHashMap(二)
一、前言
前面我们已经分析了HashMap的源码,已经知道了HashMap可以用在哪种场合,如果这样一种情形,我们需要按照元素插入的顺序来访问元素,此时,LinkedHashMap就派上用场了,它保存着元素插入的顺序,并且可以按照我们插入的顺序进行访问。
二、LinkedHashMap用法
import java.util.Map;
import java.util.LinkedHashMap; public class Test {
public static void main(String[] args) {
Map<String, String> maps = new LinkedHashMap<String, String>();
maps.put("aa", "aa");
maps.put("bb", "bb");
maps.put("cc", "cc"); for (Map.Entry entry : maps.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
}
}
说明:以上是展示LInkedHashMap简单用法的一个示例,可以看到它确实按照元素插入的顺序进行访问,保持了元素的插入顺序。更具体的用户可以去参照API。
三、LinkedHashMap数据结构
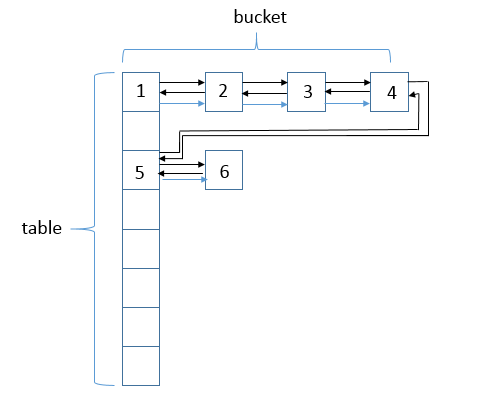
说明:LinkedHashMap会将元素串起来,形成一个双链表结构。可以看到,其结构在HashMap结构上增加了链表结构。数据结构为(数组 + 单链表 + 红黑树 + 双链表),图中的标号是结点插入的顺序。
四、LinkedHashMap源码分析
其实,在分析了HashMap的源码之后,我们来分析LinkedHashMap的源码就会容易很多,因为LinkedHashMap是在HashMap基础上进行了扩展,我们需要注意的就是两者不同的地方。
4.1 类的继承关系
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
说明:LinkedHashMap继承了HashMap,所以HashMap的一些方法或者属性也会被继承;同时也实现了Map结构,关于HashMap类与Map接口,我们之前已经分析过,不再累赘。
4.2 类的属性
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 版本序列号
private static final long serialVersionUID = 3801124242820219131L;
// 链表头结点
transient LinkedHashMap.Entry<K,V> head;
// 链表尾结点
transient LinkedHashMap.Entry<K,V> tail;
// 访问顺序
final boolean accessOrder;
}
说明:由于继承HashMap,所以HashMap中的非private方法和字段,都可以在LinkedHashMap直接中访问。
4.3 类的构造函数
1. LinkedHashMap(int, float)型构造函数
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
说明:总是会在构造函数的第一行调用父类构造函数,使用super关键字,accessOrder默认为false,access为true表示之后访问顺序按照元素的访问顺序进行,即不按照之前的插入顺序了,access为false表示按照插入顺序访问。
2. LinkedHashMap(int)型构造函数
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
3. LinkedHashMap()型构造函数
public LinkedHashMap() {
super();
accessOrder = false;
}
4. LinkedHashMap(Map<? extends K, ? extends V>)型构造函数
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
说明:putMapEntries是调用到父类HashMap的函数
5. LinkedHashMap(int, float, boolean)型构造函数
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
说明:可以指定accessOrder的值,从而控制访问顺序。
4.4 类的重要函数分析
1. newNode函数
// 当桶中结点类型为HashMap.Node类型时,调用此函数
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 生成Node结点
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将该结点插入双链表末尾
linkNodeLast(p);
return p;
}
说明:此函数在HashMap类中也有实现,LinkedHashMap重写了该函数,所以当实际对象为LinkedHashMap,桶中结点类型为Node时,我们调用的是LinkedHashMap的newNode函数,而非HashMap的函数,newNode函数会在调用put函数时被调用。可以看到,除了新建一个结点之外,还把这个结点链接到双链表的末尾了,这个操作维护了插入顺序。
其中LinkedHashMap.Entry继承自HashMap.Node
static class Entry<K,V> extends HashMap.Node<K,V> {
// 前后指针
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
说明:在HashMap.Node基础上增加了前后两个指针域,注意,HashMap.Node中的next域也存在。
2. newTreeNode函数
// 当桶中结点类型为HashMap.TreeNode时,调用此函数
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
// 生成TreeNode结点
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
// 将该结点插入双链表末尾
linkNodeLast(p);
return p;
}
说明:当桶中结点类型为TreeNode时候,插入结点时调用的此函数,也会链接到末尾。
. afterNodeAccess函数
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 若访问顺序为true,且访问的对象不是尾结点
if (accessOrder && (last = tail) != e) {
// 向下转型,记录p的前后结点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// p的后结点为空
p.after = null;
// 如果p的前结点为空
if (b == null)
// a为头结点
head = a;
else // p的前结点不为空
// b的后结点为a
b.after = a;
// p的后结点不为空
if (a != null)
// a的前结点为b
a.before = b;
else // p的后结点为空
// 后结点为最后一个结点
last = b;
// 若最后一个结点为空
if (last == null)
// 头结点为p
head = p;
else { // p链入最后一个结点后面
p.before = last;
last.after = p;
}
// 尾结点为p
tail = p;
// 增加结构性修改数量
++modCount;
}
}
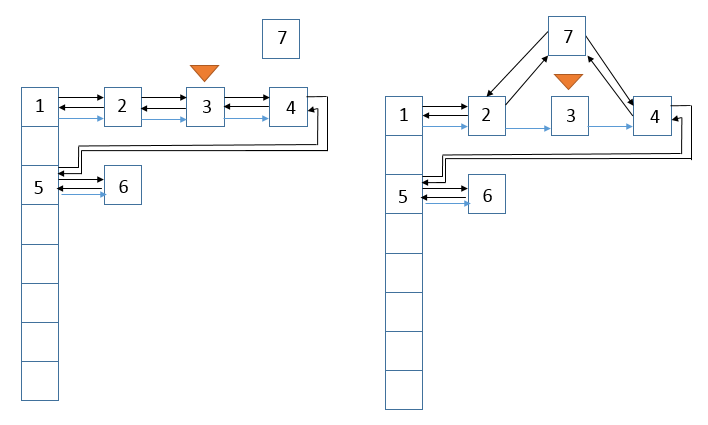
说明:此函数在很多函数(如put)中都会被回调,LinkedHashMap重写了HashMap中的此函数。若访问顺序为true,且访问的对象不是尾结点,则下面的图展示了访问前和访问后的状态,假设访问的结点为结点3

说明:从图中可以看到,结点3链接到了尾结点后面。
4. transferLinks函数
// 用dst替换src
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
说明:此函数用dst结点替换结点,示意图如下
说明:其中只考虑了before与after域,并没有考虑next域,next会在调用tranferLinks函数中进行设定。
5. containsValue函数
public boolean containsValue(Object value) {
// 使用双链表结构进行遍历查找
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
说明:containsValue函数根据双链表结构来查找是否包含value,是按照插入顺序进行查找的,与HashMap中的此函数查找方式不同,HashMap是使用按照桶遍历,没有考虑插入顺序。
五、总结
在HashMap的基础上分析LinkedHashMap会容易很多,读源码好处多多,有时间的话,园友们也可以读读源码,感受一下来自java设计者的智慧。谢谢观看~
【集合框架】JDK1.8源码分析之LinkedHashMap(二)的更多相关文章
- 【集合框架】JDK1.8源码分析HashSet && LinkedHashSet(八)
一.前言 分析完了List的两个主要类之后,我们来分析Set接口下的类,HashSet和LinkedHashSet,其实,在分析完HashMap与LinkedHashMap之后,再来分析HashSet ...
- 【集合框架】JDK1.8源码分析之HashMap(一) 转载
[集合框架]JDK1.8源码分析之HashMap(一) 一.前言 在分析jdk1.8后的HashMap源码时,发现网上好多分析都是基于之前的jdk,而Java8的HashMap对之前做了较大的优化 ...
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- 【集合框架】JDK1.8源码分析之Collections && Arrays(十)
一.前言 整个集合框架的常用类我们已经分析完成了,但是还有两个工具类我们还没有进行分析.可以说,这两个工具类对于我们操作集合时相当有用,下面进行分析. 二.Collections源码分析 2.1 类的 ...
- 集合之TreeSet(含JDK1.8源码分析)
一.前言 前面分析了Set接口下的hashSet和linkedHashSet,下面接着来看treeSet,treeSet的底层实现是基于treeMap的. 四个关注点在treeSet上的答案 二.tr ...
- 集合之LinkedHashSet(含JDK1.8源码分析)
一.前言 上篇已经分析了Set接口下HashSet,我们发现其操作都是基于hashMap的,接下来看LinkedHashSet,其底层实现都是基于linkedHashMap的. 二.linkedHas ...
- 集合之HashSet(含JDK1.8源码分析)
一.前言 我们已经分析了List接口下的ArrayList和LinkedList,以及Map接口下的HashMap.LinkedHashMap.TreeMap,接下来看的是Set接口下HashSet和 ...
- 【JUC】JDK1.8源码分析之ArrayBlockingQueue(三)
一.前言 在完成Map下的并发集合后,现在来分析ArrayBlockingQueue,ArrayBlockingQueue可以用作一个阻塞型队列,支持多任务并发操作,有了之前看源码的积累,再看Arra ...
- DotNetty网络通信框架学习之源码分析
DotNetty网络通信框架学习之源码分析 有关DotNetty框架,网上的详细资料不是很多,有不多的几个博友做了简单的介绍,也没有做深入的探究,我也根据源码中提供的demo做一下记录,方便后期查阅. ...
随机推荐
- mysql自动加入添加时间列
`addtime` TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- Java中堆内存和栈内存详解
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间 ...
- myeclipse tomcat内存溢出解决方法
Tomcat直接启动正常,通过myeclipse启动tomcat内存溢出.MyEclipse启动Tomcat无视catalina.bat中设置内存大小的问题.在 tomcat的catalina.bat ...
- mongoose 和 mongoDB
第三方学习地址:http://blog.csdn.net/foruok/article/details/47746057 下载mongoDB https://www.mongodb.com/downl ...
- iOS开发——post异步网络请求封装
IOS中有许多网络请求的函数,同步的,异步的,通过delegate异步回调的. 在做一个项目的时候,上网看了很多别人的例子,发现都没有一个简单的,方便的异步请求的封装例子.我这里要给出的封装代码,是异 ...
- mysql之触发器trigger
触发器(trigger):监视某种情况,并触发某种操作. 触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/befo ...
- java开发中JDBC连接数据库代码和步骤
JDBC连接数据库 •创建一个以JDBC连接数据库的程序,包含7个步骤: 1.加载JDBC驱动程序: 在连接数据库之前,首先要加载想要连接的数据库的驱动到JVM(Java虚拟机), 这通过java.l ...
- 反向传播(BP)算法
著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处.作者:刘皮皮链接:https://www.zhihu.com/question/24827633/answer/29120394来源 ...
- 让Ajax更简单
之前写了一篇 ASP.NET中一种超简单的Ajax解决方案 最近把他拿出来更新了下,把demo也搞的更详细了一点 加入了blqw.Json,所以支持更多类型参数和返回值 优化了对exception的处 ...
- Worktile协同特色之二:任务看板管理
什么是看板 看板是一种使用可视化管理的方式,跟踪任务在整个价值流中流经的不同阶段,通常我们会用带贴纸的白板,或是电子卡片墙.具备如下几个特征:1. 流程可视化 把工作拆分成小块,一张卡片写一件任务,再 ...