pytorch笔记
Tensor create
#创建特定shape value为random值的tensor
input = torch.rand((64,64,3))
Tensor slice
- 以[2,3]矩阵为例,slice后可以得到任意shape的矩阵,并不是说一定会小于2行3列.
import torch
truths=torch.Tensor([[1,2,3],[4,5,6]])
#代表新生成一个[3,]的矩阵,行位置分别取原先矩阵的第1,第0,第1行.
print(truths[[1,0,1],:])
print(truths[[1,0,1]]) #等同于truths[[1,0,1],:]
#代表新生成一个[,4]的矩阵,列位置分别取原先矩阵的第2,第2,第2,第2列
print(truths[:,[2,2,2,2]])
输出

- 用bool型的tensor去切片
import torch
x = torch.tensor([[1,2,3],[4,5,6]])
index = x>2
print(index.type())
x[index]

tensor扩展

Expanding a tensor does not allocate new memory, but only creates a new view on the existing tensor where a dimension of size one is expanded to a larger size by setting the stride to 0. Any dimension of size 1 can be expanded to an arbitrary value without allocating new memory.
并不分配新内存. 只是改变了已有tensor的view. size为1的维度被扩展为更大的size.
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
gather
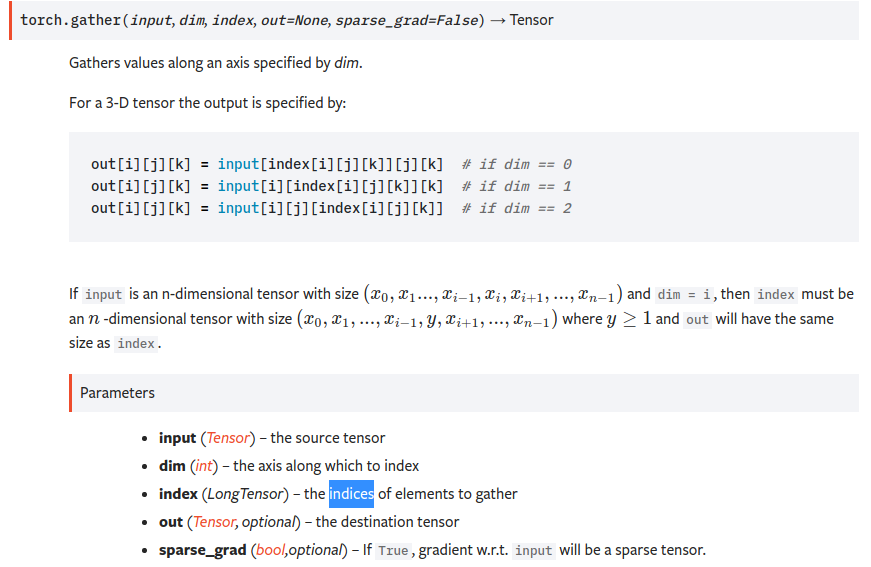
torch.gather(input, dim, index, out=None, sparse_grad=False) → Tensor
即dim维度的下标由index替换.input是n维的,index也得是n维的,tensor在第dim维度上的size可以和input不一致. 最终的output和index的shape是一致的.
即对dim维度的数据按照index来索引.
比如
import torch
t = torch.tensor([[1,2],[3,4]])
index=torch.tensor([[0,0],[1,0]])
torch.gather(t,1,index)
输出
tensor([[1, 1],
[4, 3]])
gather(t,1,index)替换第1维度的数据(即列方向),替换成哪些列的值呢?[[0,0],[1,0]],对第一行,分别为第0列,第0列,对第二行,分别为第1列,第0列.
从而得到tensor([[1, 1],[4, 3]])
sum

沿着第n维度,求和.keepdim表示是否保持维度数目不变.
import torch
t = torch.tensor([[1,2],[3,4]])
a=torch.sum(t,0)
b=torch.sum(t,1,keepdim=True)
print(a.shape,b.shape)
print(a)
print(b)

sort
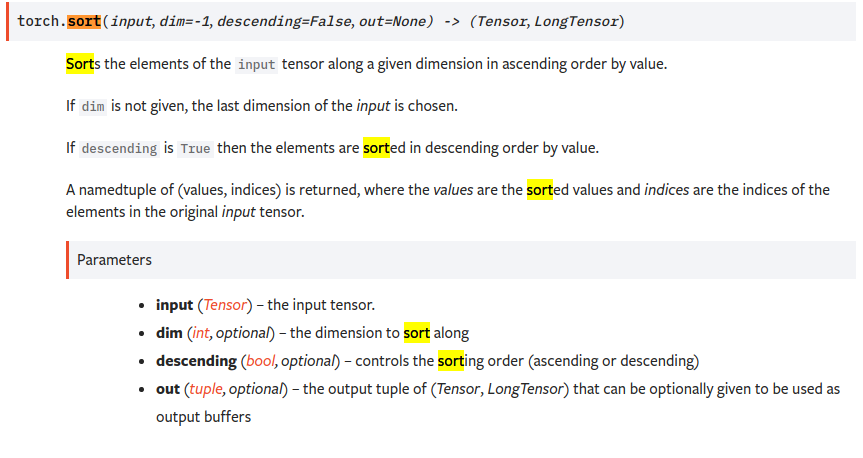
沿着第n个维度的方向排序
import torch
t = torch.tensor([[1,9,7],[8,5,6]])
_sorted,_index = t.sort(1)
print(_sorted)
print(_index)
_sorted,_index = t.sort(0)
print(_sorted)
print(_index)

clamp
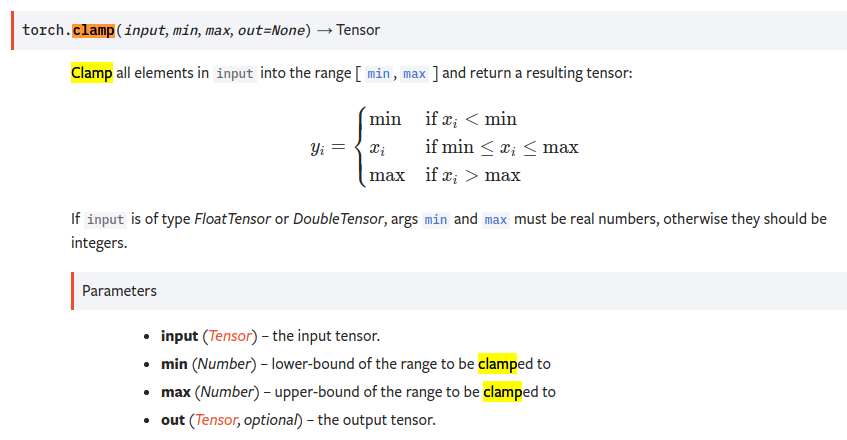
import torch
print()
t = torch.tensor([[1,2,7],[3,4,8]])
res = t.clamp(3,7) #<3的变为3,>7的变为7 中间范围的不变
print(res)
res2 = torch.clamp(t,max=5) #所有大于5的都改为5
print(res2)

各种损失函数
https://blog.csdn.net/zhangxb35/article/details/72464152
有用link:
pytorch笔记的更多相关文章
- [Pytorch] pytorch笔记 <三>
pytorch笔记 optimizer.zero_grad() 将梯度变为0,用于每个batch最开始,因为梯度在不同batch之间不是累加的,所以必须在每个batch开始的时候初始化累计梯度,重置为 ...
- [Pytorch] pytorch笔记 <二>
pytorch笔记2 用到的关于plt的总结 plt.scatter scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, ...
- [Pytorch] pytorch笔记 <一>
pytorch笔记 - torchvision.utils.make_grid torchvision.utils.make_grid torchvision.utils.make_grid(tens ...
- 【转载】 pytorch笔记:06)requires_grad和volatile
原文地址: https://blog.csdn.net/jiangpeng59/article/details/80667335 作者:PJ-Javis 来源:CSDN --------------- ...
- pytorch笔记:09)Attention机制
刚从图像处理的hole中攀爬出来,刚走一步竟掉到了另一个hole(fire in the hole*▽*) 1.RNN中的attentionpytorch官方教程:https://pytorch.or ...
- [pytorch笔记] 调整网络学习率
1. 为网络的不同部分指定不同的学习率 class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self ...
- [pytorch笔记] torch.nn vs torch.nn.functional; model.eval() vs torch.no_grad(); nn.Sequential() vs nn.moduleList
1. torch.nn与torch.nn.functional之间的区别和联系 https://blog.csdn.net/GZHermit/article/details/78730856 nn和n ...
- Pytorch笔记 (3) 科学计算1
一.张量 标量 可以看作是 零维张量 向量 可以看作是 一维张量 矩阵 可以看作是 二维张量 继续扩展数据的维度,可以得到更高维度的张量 ————> 张量又称 多维数组 给定一个张量数据 ...
- Pytorch笔记 (2) 初识Pytorch
一.人工神经网络库 Pytorch ———— 让计算机 确定神经网络的结构 + 实现人工神经元 + 搭建人工神经网络 + 选择合适的权重 (1)确定人工神经网络的 结构: 只需要告诉Pytorc ...
- PyTorch笔记之 Dataset 和 Dataloader
一.简介 在 PyTorch 中,我们的数据集往往会用一个类去表示,在训练时用 Dataloader 产生一个 batch 的数据 https://pytorch.org/tutorials/begi ...
随机推荐
- java教程系列二:Java JDK,JRE和JVM分别是什么?
多情只有春庭月,犹为离人照落花. 概述 本章主要了解JDK,JRE和JVM之间的区别.JVM是如何工作的?什么是类加载器,解释器和JIT编译器.还有一些面试问题. Java程序执行过程 在深入了解Ja ...
- 记一次 JavaScript 浮点型数字误差引发的问题
需求 车间的工人在生产出来产品后,需要完成初步的自检,并通过手机上报.在实际生产中,用户(工人)不方便进行数值的输入,因而表单中的一些项设计成 picker 模式以供选取数值.数值的取值范围,根据允许 ...
- C#控件及常用属性
1.窗体(Form) 1.常用属性 (1)Name 属性:用来获取或设置窗体的名称,在应用程序中可通过Name 属性来引用窗体. (2) WindowState 属性: 用来获取或设置窗体的窗口状态. ...
- SpringBootSecurity学习(09)网页版登录配置Session共享
场景 当后台项目由部署在一台改为部署在多台以后,解决session共享问题最常用的办法就是把session存储在redis等缓存中.关于session和cookie概念这里就不再赘述了,在spring ...
- python-字符编码、字符串格式化、进制转化、数据类型、列表、元组、字典总结
目录: 一.字符编码 二.字符串格式化 三.进制转换 四.数据类型及其操作 五.字符串转换 六.列表 七.元组 八.字典 一.字符编码: 计算机由美国人发明,最早的字符编码为ASCII,只规定了英文字 ...
- 如何让谷歌浏览器支持小于12px的字体
CSS3有个新的属性transform,而我们用到的就是transform:scale() 书写一段代码 <body> <p>我是一个小于12PX的字体</p> & ...
- 详解PHP魔术函数、魔术常量、预定义常量
一.魔术函数(13个) 1.__construct() 实例化对象时被调用, 当__construct和以类名为函数名的函数同时存在时,__construct将被调用,另一个不被调用. 2.__des ...
- 使用真机导致Androidstudio打印不出log
针对真机打印不出log这个问题,我具体的解决方案是这样: 1.你要确保你的Android studio中的菜单栏 ,Tools → Android → Enable ADB Integration这个 ...
- Linux简单检查服务运行脚本
脚本内容如下: 此脚本含义:检查服务是否运行,在运行则记录日志,不在运行则记录日志并将服务启动 #!/bin/bash svrnm="tomcat" //设置服务名称time=`d ...
- openpyxl中遇到TypeError: 'generator' object is not subscriptable的问题和解决方案
今天在搭建驱动数据框架用到了一个叫 openpyxl的包用来解析excel数据 随后就出现了TypeError: 'generator' object is not subscriptable的bug ...