Jmeter- 笔记8 - 分布式
分布式:
原因:在实际工作中,jmeter可能需要虚拟上千并发用户,而每台实际能虚拟的线程数时有限的,一般一台电脑小于2000个,1.5k - 2k可能就出现无法虚拟。
多台机器,一起虚拟并发用户数,从而实现更大的并发
分布式是 分摊机器自身的压力
分布式配置:
步骤1.保证一致性:分布式机器要在同一个局域网;jdk一致,jmeter版本一致,jmeter的插件一直(从本机把jdk,jmeter和 待运行脚本 一起打包给助攻机器)
步骤2.在助攻机器修改jmeter的配置文件 jmeter.properties 下面三个地方
1.server_port = 1213
2.server.rmi.port = 1213 --- 认证的端口
3.server.rmi.ssl.disable = true --- 不开启加密认证
步骤3.启动助攻机器:在jmeter bin文件夹运行cmd输入命令:jmeter-server.bat -Djava.rmi.server.hostname=助攻机器IP
步骤4.主控机器修改配置文件 jmeter.properties
1.remote_hosts=助攻机器IP:端口 ---- 多台助攻机器,用逗号隔开
2.server.rmi.ssl.disable = true
3.mode=standard
步骤5.重启主控机的jmeter
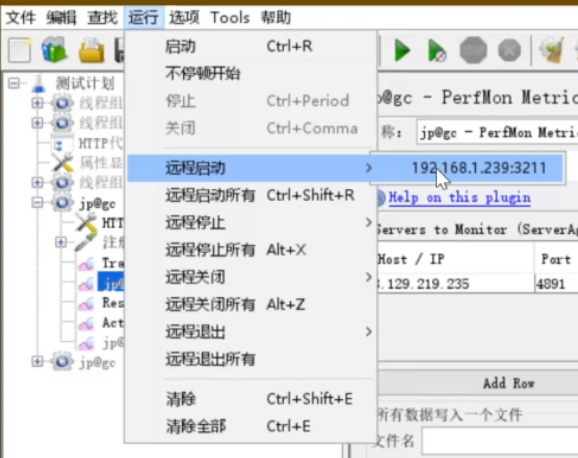
步骤6.在jmeter -> 运行 -> 远程启动 找到配置的助攻机器IP,(若有多台,会有多个IP和端口显示)如下图,选择某个助攻IP为运行那台机器的脚本,选择 远程启动所有,会一起运行所有配置好的助攻机器的脚本
另,把主控机配置设置同助攻机器一样,可以当成助攻机一样运行
番外
在主控机修改脚本,然后运行助攻机器,助攻机器运行都是按照主控机的最新脚本来运行。
Jmeter- 笔记8 - 分布式的更多相关文章
- JMeter学习-022-JMeter 分布式测试(性能测试大并发、远程启动解决方案)
在使用 JMeter 进行性能测试时,难免遇到要求并发请求数比较的场景,此时单台测试机的配置(CPU.内存.带宽等)可能无法支持此性能测试场景.因而,此时 JMeter 提供的分布式测试功能就有了用武 ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Jmeter工具使用-分布式架构和服务器性能监控解决方案
在对项目做大并发性能测试时,常会碰到并发数比较大(比如需要支持10000并发),单台电脑的配置(CPU和内存)可能无法支持,这时可以使用Jmeter提供的分布式测试的功能来搭建分布式并发环境. 一.J ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- JMeter学习-026-JMeter 分布式(远程)参数化测试实例
以前文所述对文章详情的HTTP请求进行性能测试为例.日常实际场景中,不可能所有的人都在同时访问一篇文章,而是多人访问不同的文章,因而需要对文章编号进行参数化,以更好的模拟日常的性能测试场景.同时,因文 ...
- jmeter笔记5
性能测试是任何分布式或Web应用程序测试计划的重要组成部分.在计划和开发周期中进行性能评价,可以保证交付给客户的应用程序满足客户对于高负载.可用性和可伸缩性的要求.提前确定软件的负载限制可以为适当地进 ...
- jmeter笔记1
使用 JMeter 分布式性能测试 作为一个纯 JAVA 的GUI应用,JMeter 对于CPU和内存的消耗还是很惊人的, 所以当需要模拟数以千计的并发用户时,使用单台机器模拟所有的并发用 ...
- jmeter笔记(9)--JDBC Request的使用
JDBC Request可以向数据库发送一个JDBC(Java Data Base Connectivity)请求(sql语句),获取返回的数据库数据进行操作.它需要和JDBC Connection ...
- Jmeter性能测试之分布式(五)
Jmeter是纯Java开发的开源性能测试工具, Java程序是很吃内存的, 有时候一台负载机给服务器的压力是不够的, 需要很多台同时负载, 这个时候就需要用到分布式了. 1. 组网图大概就是这样的 ...
- JMeter压测分布式部署
监控JMeter压力机的性能
随机推荐
- hdu4810
题意: 给你n个数,让你输出n个数,没一次输出的是在这n个数里面取i个数异或的和(所有情况<C n中取i>). 思路: 首先把所有的数都拆成二进制,然后把他们在某一位上 ...
- Linux配置NTP时间服务器(date、hwclock、NTP服务器的配置)
目录 date命令 hwclock命令 NTP服务的部署 服务端 客户端 date命令 date 命令的作用是查看和设置Linux中的系统日期时间 date ...
- Python中面向对象和类
目录 面向对象 类的定义 类的访问 类的属性和方法 继承和多态 面向对象 Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的. 面向对象: 类(C ...
- html个人笔记
HTML 1.1常用编辑器 dreamweaver.sublime.webstorm.Hbuilder.vscode 1.2 浏览器内核 分为渲染引擎和JS引擎 渲染引擎:它负责取得网页的内容(HTM ...
- 【flutter学习】基础知识(一)
今天开始学习一下flutter 学习思路:首先由一个简单的例子引出每次学习的对象,一点一点加入元素,针对于代码去了解学习详细知识. 看完本篇博客能够快速的读懂flutter简单代码. flutter ...
- vue的快速入门【IDEA版本】
和vscode相比,使用IDEA进行前端开发并没有那么容易,需要先进行配置 . 安装vue插件,重启idea 鼠标右键添加vue component 点击 file 打开设置 settings,展开 ...
- Docker搭建开发环境(Nginx+MySQL+PHP)
注意事项 1.像MySQL配置文件.Nginx配置文件.网站根目录这种比较经常操作的需要先使用 docker cp 将文件从容器里复制到主机目录,docker run的时候直接挂载目录就可以了 2.d ...
- InnoDB存储引擎简介
前言: 存储引擎是数据库的核心,对于 MySQL 来说,存储引擎是以插件的形式运行的.虽然 MySQL 支持种类繁多的存储引擎,但最常用的当属 InnoDB 了,本篇文章将主要介绍 InnoDB 存储 ...
- 如何更好理解Peterson算法?
如何更好理解Peterson算法? 1 Peterson算法提出的背景 在我们讲述Peterson算法之间,我们先了解一下Peterson算法提出前的背景(即:在这个算法提出之前,前人们都做了哪些工作 ...
- [bug] Unable to create initial connections of pool.
原因1 pom中mysql依赖的版本不对,导致无法连接mysql 原因2 SSL设置问题 参考 https://blog.csdn.net/qq_26346457/article/details/79 ...