机器学习——正则化方法Dropout
1 前言
- 2012年,Dropout的想法被首次提出,受人类繁衍后代时男女各一半基因进行组合产生下一代的启发,论文《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》 提出了Dropout,它的出现彻底改变了深度学习进度,之后深度学习方向(反馈模型)开始展现优势,传统的机器学习慢慢消声。
- 深度学习架构现在变得越来越深,dropout 作为一个防过拟合的手段,使用也越来越普遍。
2 Dropout具体实现
- Dropout的思路:在一次循环中先随机选择神经层中的一些单元并将其临时隐藏,然后再进行该次循环中神经网络的训练和优化过程,在下一次循环中,又将隐藏另外一些神经元,如此直至训练结束。这样每次都会有一种新的组合,假设某一层有 $N$ 个神经元,就有 $2^N$ 个组合,最后子网络的输出均值就是最终的结果。但如果同时训练这些子网络代价太大,而且测试时又要组合多个网络的输出结果,不可行。
- 在训练时,每个神经单元以概率 $p$ 被保留(dropout丢弃率为$1-p$);在测试阶段,每个神经单元都是存在的,权重参数 $w$ 要乘以 $p$,变成 $ pw$ 。测试时需要乘上 $p$ 的原因:考虑第一隐藏层的一个神经元在 dropout 之前的输出是 $x$,那么 dropout 之后的期望值是 $E=px+(1−p)0 $,在测试时该神经元总是激活,为了保持同样的输出期望值并使下一层也得到同样的结果,需要调整$x→px$. 其中 $p$ 是 Bernoulli 分布 $(0-1分布)$ 中值为 $1$ 的概率。

3 Dropout具体工作流程
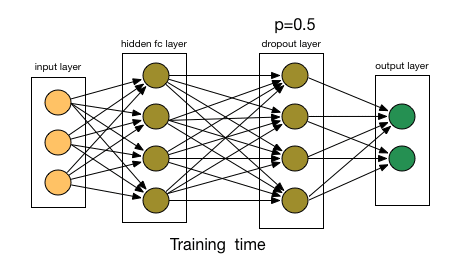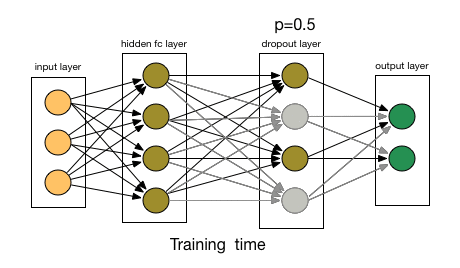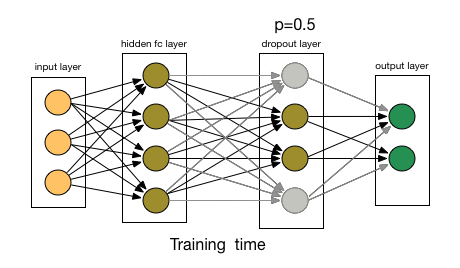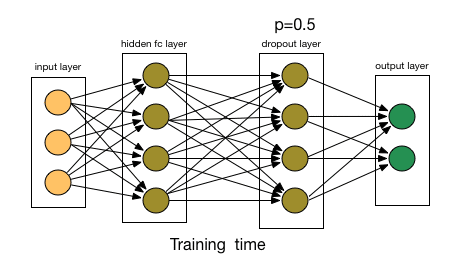
- 为了了解Dropout,假设我们的神经网络结构类似于以下所示:(这里图只有Hidden layer,Output layer)
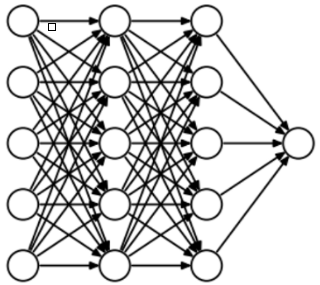
- 输入是 $x$ 输出是 $y$,正常的流程是:我们首先把 $x$ 通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
- (1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变。
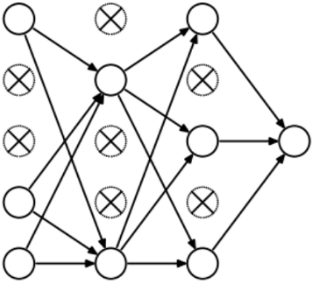
- (2)然后把输入 $x$ 通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数$(w,b)$。
- (3)然后继续重复这一过程:因此,每个迭代都有一组不同的节点,这会导致一组不同的输出。 也可以将其视为机器学习中的集成技术。
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小 $(ρ=0.5)$ 的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数 $(w,b)$ (没有被删除的那一部分参数得到更新,删除的神经元参数,保持被删除前的结果)。
- Dropout也比正常的神经网络模型表现更好。选择应该删除多少个节点的这种可能性是丢失函数的超参数。 如上图所示,Dropout既可以应用于隐藏层,也可以应用于输入层。
机器学习——正则化方法Dropout的更多相关文章
- TensorFlow之DNN(三):神经网络的正则化方法(Dropout、L2正则化、早停和数据增强)
这一篇博客整理用TensorFlow实现神经网络正则化的内容. 深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合.缓解神经网络的过拟 ...
- [机器学习]正则化方法 -- Regularization
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到. L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合( ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout(转)
ps:转的.当时主要是看到一个问题是L1 L2之间有何区别,当时对l1与l2的概念有些忘了,就百度了一下.看完这篇文章,看到那个对W减小,网络结构变得不那么复杂的解释之后,满脑子的6666------ ...
- 正则化方法L1 L2
转载:http://blog.csdn.net/u012162613/article/details/44261657(请移步原文) 正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者ov ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 模型正则化,dropout
正则化 在模型中加入正则项,防止训练过拟合,使测试集效果提升 Dropout 每次在网络中正向传播时,在每一层随机将一些神经元置零(相当于激活函数置零),一般在全连接层使用,在卷积层一般随机将整个通道 ...
- OpenCV3 Java 机器学习使用方法汇总
原文链接:OpenCV3 Java 机器学习使用方法汇总 前言 按道理来说,C++版本的OpenCV训练的版本XML文件,在java中可以无缝使用.但要注意OpenCV本身的版本问题.从2.4 到3 ...
- [转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam https://blog.csdn.net/u010089444/article/details/76 ...
随机推荐
- ES6与ES2015、ES2016以及ECMAScript的区别
1. ECMAScript 和 JavaScript 的关系 ECMAScript 和 JavaScript 的关系是,前者是后者的规格,后者是前者的一种实现. javascript是netscape ...
- OOP面向对象程序设计原则
OOP面向对象程序设计原则 开闭原则(Open Close Principle) 对扩展开放,对修改关闭 里氏代换原则(Liskov Substitution Principle) 继承必须确保超累所 ...
- AbstractRoutingDataSource -- Spring提供的轻量级数据源切换方式
AbstractRoutingDataSource 只支持单库事务,也就是说切换数据源要在开启事务之前执行. spring DataSourceTransactionManager进行事务管理,开启事 ...
- 过去,我买漫画看;现在,我用Python爬虫来看
原标题:运用Python多线程爬虫下载漫画 前言: 以前,我都是买漫画书看的,那个时候没有电脑.今天,我到网上看了一下,发现网上提供漫画看,但是时时需要网络啊!为什么不将它下载下来呢! 1.怎样实现 ...
- Java Lambda 表达式源码分析
基本概念 Lambda 表达式 函数式接口 方法引用 深入实现原理 字节码 为什么不使用匿名内部类? invokedynamic 总结 参考链接 GitHub 项目 Lambda 表达式是什么?JVM ...
- Lab: 2FA bypass using a brute-force attack:暴力破解双重验证靶场复盘(困难级别)
靶场内容: This lab's two-factor authentication is vulnerable to brute-forcing. You have already obtained ...
- 【XSS-labs】Level 11-15
Level 11 和level 10 差不多的页面,传参后查看页面源代码:依旧是第3个可以正常传参. 尝试level 10 的payload 发现 " 被实体化 可以打开控制台将第三个inp ...
- Vulnhub -- DC4靶机渗透
用nmap扫描ip和端口,发现只开启了22ssh端口和80http端口 打开网页只有一个登录界面 目录爆破没有发现什么有用的,尝试对登录进行弱口令爆破 一开始使用burpsuite,使用一个小字典进行 ...
- Windows Go 开发环境下载、安装并配置
前言 对于我们Windows用户而言,Go提供两种环境安装方式(源码安装除外): 1.MSI安装(MSI文件是Windows Installer的数据包,它实际上是一个数据库,包含安装一种产品所需要的 ...
- Jpa-操作mongodb
pom <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spr ...