[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
https://blog.csdn.net/u010089444/article/details/76725843
这篇博客格式不好直接粘贴,就不附原文了。
有几个点可以注意下,原文没有写的很清楚:
优化方法的作用是什么?
可以说,没有优化方法,机器学习模型一般一样可以执行,所以说它并不是必须的。但是优化方法可以动态调整学习率以及影响迭代中参数调整的方向和幅度,可以加速收敛,是对原方法的一种优化。
Momentum:
Momentum方法一般用来辅助SGD,从下图也能看出来:
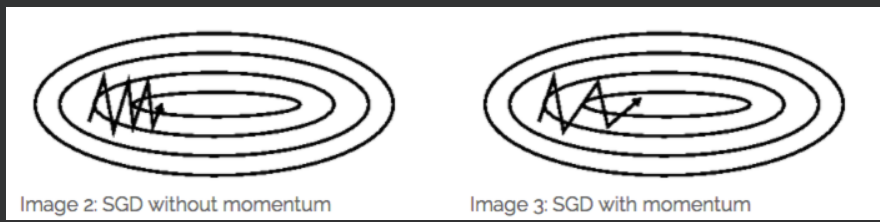
它的作用是加速SGD,并且抑制震荡。
另外,从原理上来说,它应用在BGD上也没有什么问题。
Nesterov Momentum方法是Momentum方法的一种改进,思路也是和传统的思路比较类似的:传统思路中,在一次参数更新中,更新后面的参数如果要使用前面的参数,则使用本次更新中前面参数已经更新了的值可以加速收敛。这里是反过来了:先更新vt,后更新梯度。但是vt的计算中要用到梯度,这里就使用梯度更新后的值可以使得结果更加准确、收敛更快。但是这时更新值还没有计算出来,于是使用了”预测“值,J中的梯度计算取的是迭代公式中的线性部分。
什么是”矩估计“
来源:https://baike.baidu.com/item/%E7%9F%A9%E4%BC%B0%E8%AE%A1
矩估计,即矩估计法,也称“矩法估计”,就是利用样本矩来估计总体中相应的参数。首先推导涉及感兴趣的参数的总体矩(即所考虑的随机变量的幂的期望值)的方程。然后取出一个样本并从这个样本估计总体矩。接着使用样本矩取代(未知的)总体矩,解出感兴趣的参数。从而得到那些参数的估计。
其实就是用样本估计总体
在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果
[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 优化方法:SGD,Momentum,AdaGrad,RMSProp,Adam
参考: https://blog.csdn.net/u010089444/article/details/76725843 1. SGD Batch Gradient Descent 在每一轮的训练过 ...
- 机器学习优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)
SGD: 此处的SGD指mini-batch gradient descent,关于batch gradient descent, stochastic gradient descent, 以及 mi ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
- 5、Tensorflow基础(三)神经元函数及优化方法
1.激活函数 激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经网络.神经网络之所以能解决非线性问题(如语音.图像识别),本质上就是激 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- 各种优化方法总结比较(sgd/momentum/Nesterov/adagrad/adadelta)
前言 这里讨论的优化问题指的是,给定目标函数f(x),我们需要找到一组参数x,使得f(x)的值最小. 本文以下内容假设读者已经了解机器学习基本知识,和梯度下降的原理. Batch gradient d ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
- 优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam)
优化方法总结以及Adam存在的问题(SGD, Momentum, AdaDelta, Adam, AdamW,LazyAdam) 2019年05月29日 01:07:50 糖葫芦君 阅读数 455更多 ...
随机推荐
- databinding 填坑 绑定动作是延后生效
binding = FragmentNewsMainLayout750Binding.inflate(inflater); homePageViewModel = new HomePageViewMo ...
- 阶段5 3.微服务项目【学成在线】_day04 页面静态化_12-页面静态化-页面静态化流程
需要知道数据结构,然后去做模板标签.首先需要获取页面的数据模型.下面的每一条记录都代表一个页面. 比如这个轮播图.就需要提前给这个轮播图编写一个模板 有很多的页面如果知道每个页面的dataUrl.例如 ...
- zip炸弹
故障系统有人提了zip炸弹的故障,了解了一些关于zip炸弹的常识. 42.zip 是很有名的zip炸弹.一个42KB的文件,解压完其实是个4.5PB的“炸弹”. 更有甚者,一个叫做 droste.zi ...
- SQL 里ESCAPE的用法
TABLES:makt. SELECT SINGLE * FROM makt AND maktx LIKE '%/_' ESCAPE '/' . SQL中escape的用法使用 ESCAPE 关键字定 ...
- React Native清除缓存实现
清除缓存使用的第三方:react-native-http-cache Github: https://github.com/reactnativecn/react-native-http-cach ...
- mysql一条语句实现插入或更新的操作
,),(,) ON DUPLICATE KEY UPDATE c=VALUES(c); 或者 INSERT INTO table (id,a,b,c) select id,a,b,c from xxx ...
- Vue学习笔记(三)组件间如何通信传递参数
一:父组件向子组件传递参数 <template > <div id="app"> <h1 v-text="title">&l ...
- iOS-XMPP(转)
IM的实现原理 在我最初学习编程的时候,曾经用JAVA实现了一个最简单版的IM通讯,即通过Socket建立两台电脑之间的连接,然后发送IO流来进行即时通讯,我们现在所使用的IM软件尽管看上去非常 ...
- python 操作mysql数据库(mac)包括如何处理安装MySQL-python
一.数据库的安装,https://www.jianshu.com/p/fd3aae701db9 https://jingyan.baidu.com/article/fa4125ac0e3c2 ...
- C语言双指针之盛最多水的容器
题目描述 给定 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) .在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0).找出其中 ...