[Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程
本课主题
- 打通 Spark 系统运行内幕机制循环流程
引言
通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是從后往前划分的,执行的时候是從前往后执行的,每个 Stage 内部有一系列任務,前面有分享過,任务是并行计算啦,这是并行计算的逻辑是完全相同的,只不过是处理的数据不同而已,DAGScheduler 会以 TaskSet 的方式把我们一个 DAG 构造的 Stage 中的所有任务提交给底层的调度器 TaskScheduler,TaskScheduler 是一个接口,它作为接口的好处就是更具体的任务调到器藉耦合,这就 Spark 就可以运行在不同的调度模式上,包括可以让它运行在 Standalone、Yarn、Mesos。希望这篇文章能为读者带出以下的启发:
- 了解 Spark 系统运行内幕机制循环流程
Spark 系统运行内幕机制循环流程
DAGScheduler 在提交 TaskSet 给底层的调度器的时候是面向接口 TaskScheduler的,这符合面向对象中依赖抽象而不依赖具体的原则,带来底层资源调度器的可插拔性。导致 Spark 可以运行在众多的资源调度器的模式上,例如 Standalone 、Yarn、Mesos、Local、EC2、其它自定义的资源调度器;在 Standalone 的模式下,我们聚焦于 TaskSchedulerImpl。它會通過 TaskSet Manager 來管理我們這個具体的任务。
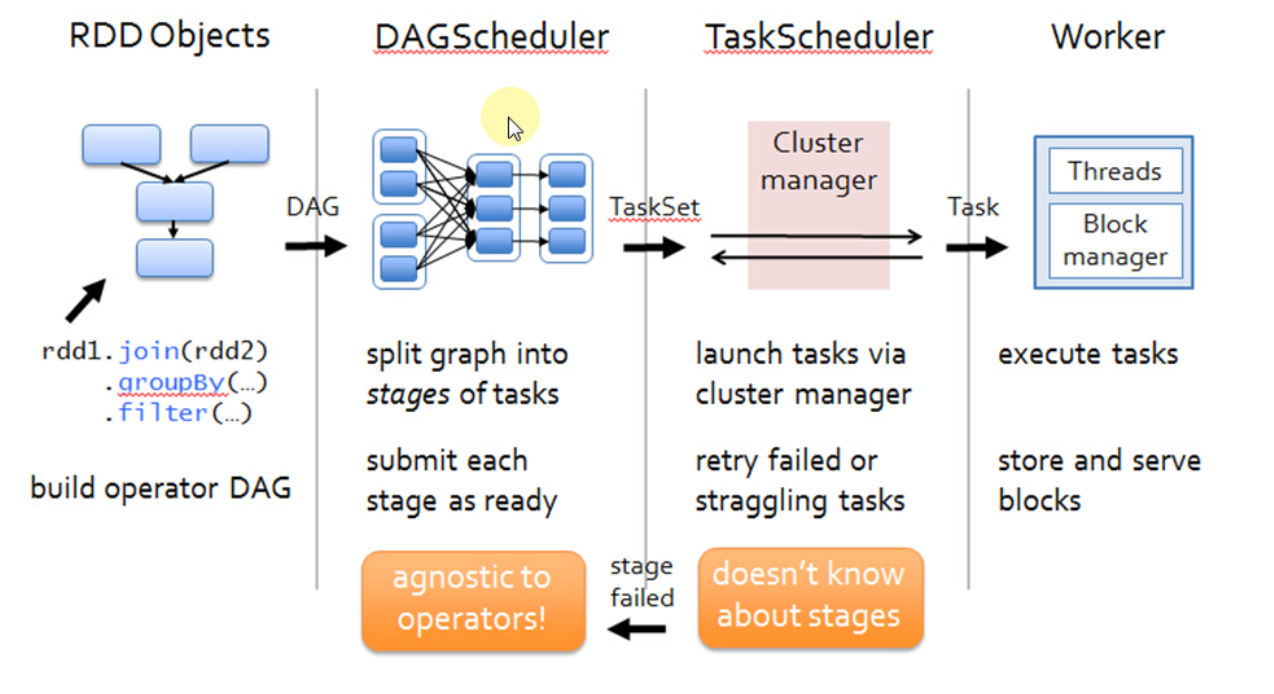
TaskScheduler 的核心任务是提交 TaskSet 到集群运算并汇报结果
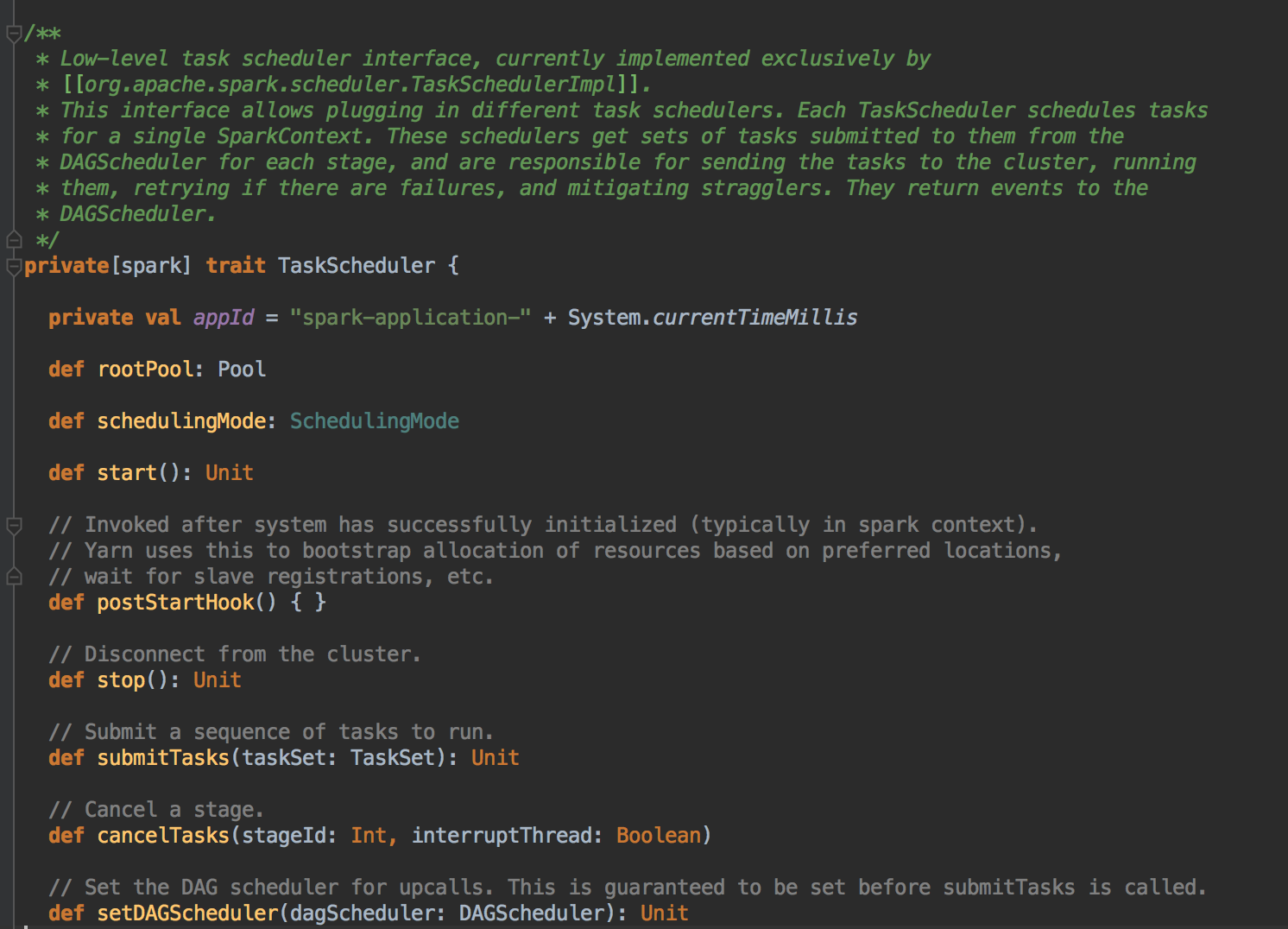
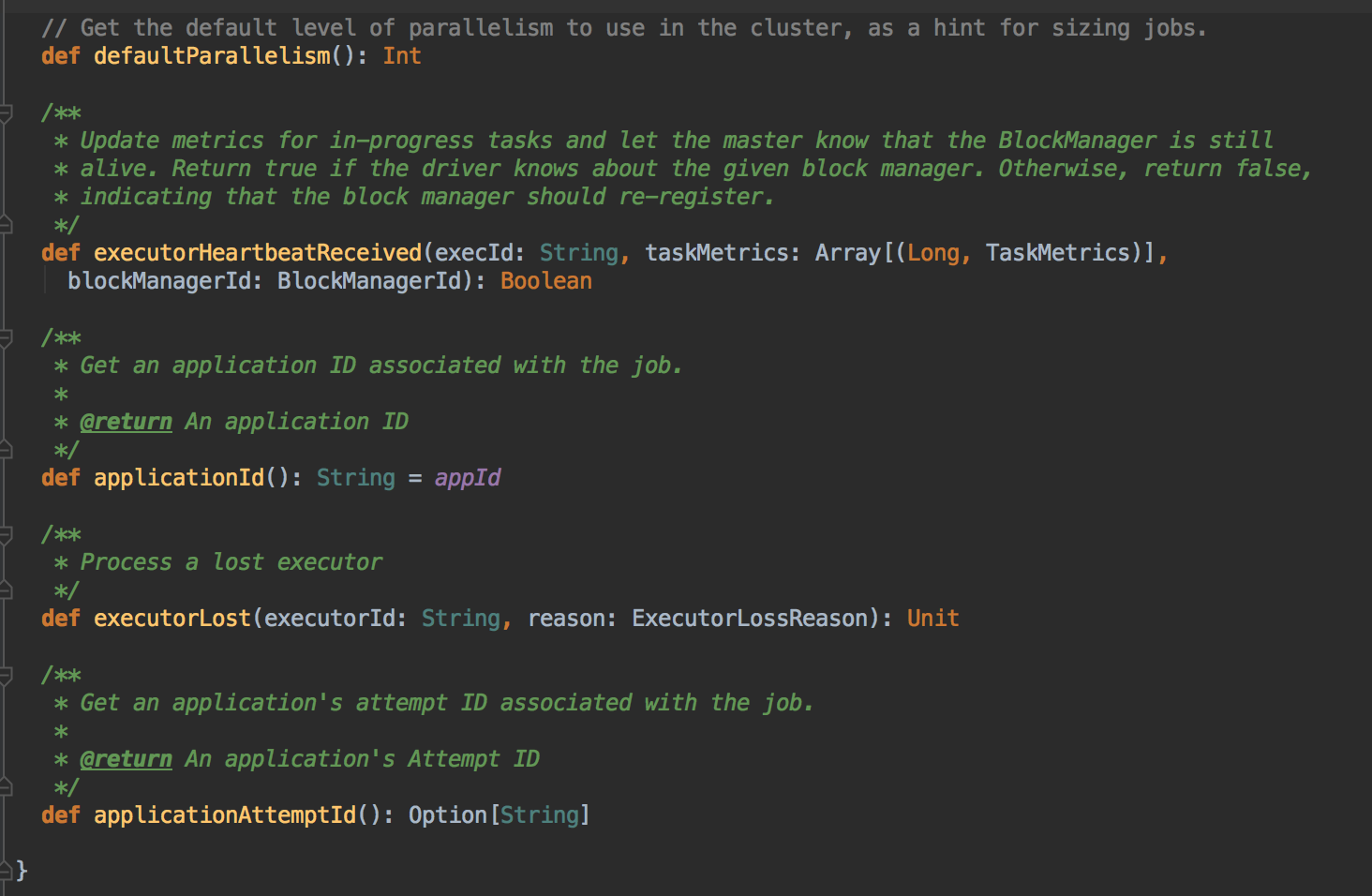
为 TaskSet 创建和维护一个 TaskSetManager 并追踪任务的本地性以及错误信息;遇到 Struggle 任务的时候会放到其他的节点进行重试;TaskScheduler 必须向 DAGScheduler 汇报执行情况,包括在 Shuffle 输出 lost 的时候报告 fetch failed 错误等信息;TaskScheduler 内部会握有 SchedulerBackend,它主要是负责管理 Executor 资源的,从 Standalone 的模式来讲具体实现是 SparkDeploySchedulerBackend; 下图是 SchedulerBackend 的源码
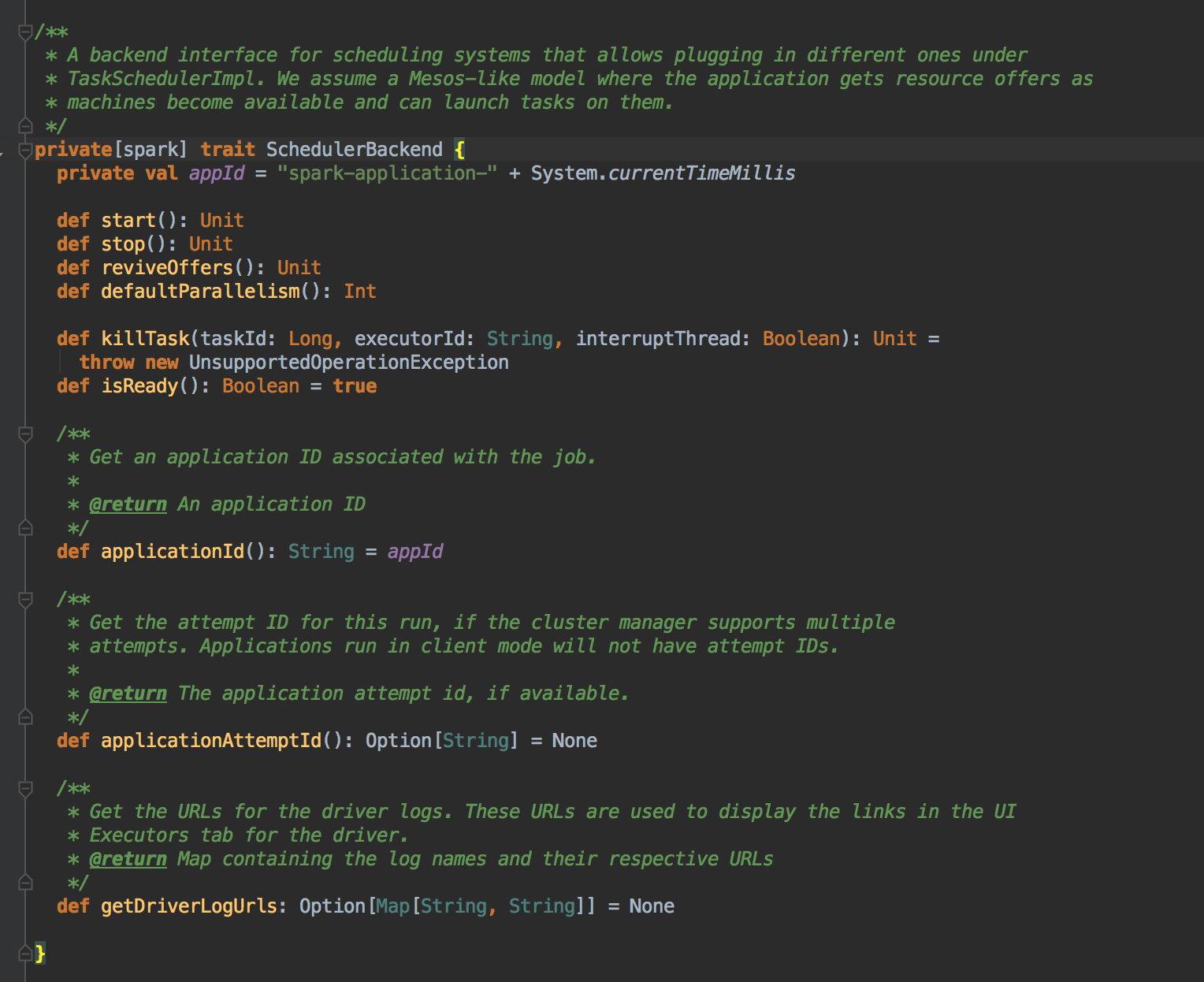
SparkDeploySchedulerBackend 专门收集 Worker 上的资源信息的。它会接受 Worker 向 Driver 注册的信息,而这个注册的时候其实就是 ExecutorBackend 启动的时候为我们当前应用程序准备的计算资源,但它是以进程为单位的。SparkDeploySchedulerBackend 在启动的时候构造 AppClient 实例并在该实例 start 的时候启动了 ClientEndpoint 这个消息循环体,ClientEndpoint 在启动的时候会向 Master 注册当前程序。
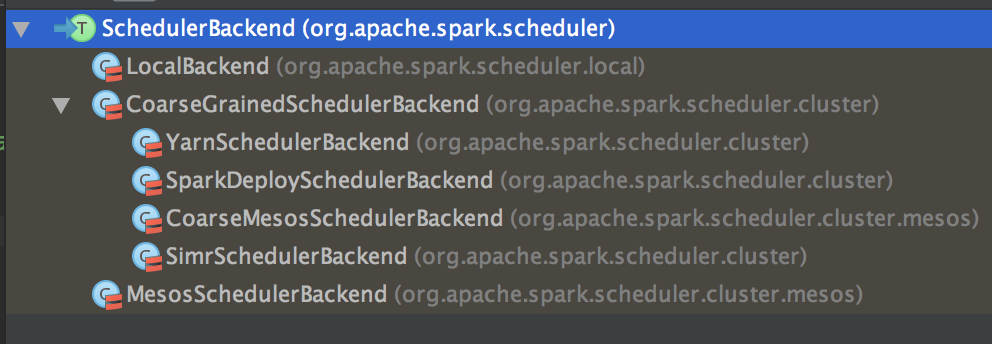
而 SparkDeploySchedulerBackend 的父类 CoraseGraninedExecutorBackend 在 start 的时候会实例化类型为 DriverEndpoint (这就是我们程序运行时候的经典的对象Driver,所以的Executor 启动时都需要向它注册) 的消息循环体,当 ExecutorBackend 启动的时候会发送 RegisterExecutor 信息向 DriverEndpoint 注册,此时 SparkDeploySchedulerBackend 就掌握了当前应用程序的计算资源,TaskScheduler 就是通过 SparkDeploySchedulerBackend 的计算资源来具体运行 Task。(SparkDeploySchedulerBackend 在整个应用程序起动一次就行啦)
SparkContext、DAGScheduler、TaskSchedulerImpl、SparkDeploySchedulerBackend 在应用程序起动的时候只实例化一次,应用程序存在期间始终存在这些对象;应用程序的总管是 DAGScheduler 和 TaskScheduler,SparkDeploySchedulerBackend 是帮助应用程序的 Task 获取具体的计算资源并把 Task 发送到集群中的。
总结
在SparkContext 实例化的时候调用 createTaskScheduler 来创建 TaskSchedulerImpl 和 SparkDeploySchedulerBackend 同时在 SparkContext 实例化的时候会调用TaskSchedulerImpl 的 start( )方法,在start( )方法中会调用 SparkDeploySchedulerBackend 的start( ),在该start( ) 方法中会创建AppClient 对象并调用AppClient 对象的start( ) 方法。在该 start( ) 方法中会创建 ClientEndpoint ,在创建 ClientEndpoint的时候会传入 Command 来指定具体为当前应用程序启动的 Executor 进程的入口类的名称为 CoraseGraninedExecutorBackend,然后ClientEndpoint 启动并通过 tryRegisterMaster 来注册当前的应用程序到 Master 中。 Master 接受到注册信息后如何可以运行程序,则会为该程序生产JobID 并通过schedule 来分配计算资源,具体计算资源的分配是通过应用程序运行方式、Memory、cores 等配置来决定的,最后Master 会发送指令给Worker。 Worker 中为当前应用程序分配计算资源时会首先分配 ExecutorRunner,ExecutorRunner 内部会通过 Thread 的方式构成 ProcessBuilder 来启动另外一个 JVM 进程。 这个 JVM 进程启动时候会加载的 main 方法 所在的类的名称就是在创建 ClientEndpoint 时传入的 Command 来指定具体名称为 CoraseGraninedExecutorBackend 的类 。 此时JVM 在通过ProcessBuilder 启动的时候获得CoraseGraninedExecutorBackend 后加载并调用其中的main 方法,在main 方法中会实例化 CoraseGraninedExecutorBackend 本身这个消息循环体,而CoraseGraninedExecutorBackend 在实例化的时候会通过回调onStart( ) 向DriverEndpoint 发送 RegisterExecutor 来注册当前的CoraseGraninedExecutorBackend,此时DriverEndpiont 收到该注册信息并保存了SparkDeploySchedulerBackend 实例的内存的数据结构中,这样Driver 就获得了计算资源!(具体的代码流程可以参考第28课:Spark天堂之门解密的博客)
參考資料
资料来源来至 DT大数据梦工厂 大数据传奇行动 第35课:打通Spark系统运行内幕机制循环流程
Spark源码图片取自于 Spark 1.6.3版本
[Spark内核] 第35课:打通 Spark 系统运行内幕机制循环流程的更多相关文章
- 打通 Spark 系统运行内幕机制循环流程
本课主题 打通 Spark 系统运行内幕机制循环流程 引言 通过 DAGScheduelr 面向整个 Job,然后划分成不同的 Stage,Stage 是从后往前划分的,执行的时候是從前往后执行的,每 ...
- 35.Spark系统运行内幕机制循环流程
一:TaskScheduler原理解密 1, DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler的,这符合面向对象中依赖抽象而不依赖的原则,带来底层资 ...
- [Spark内核] 第28课:Spark天堂之门解密
本課主題 什么是 Spark 的天堂之门 Spark 天堂之门到底在那里 Spark 天堂之门源码鉴赏 引言 我说的 Spark 天堂之门就是SparkContext,这篇文章会从 SparkCont ...
- [Spark内核] 第32课:Spark Worker原理和源码剖析解密:Worker工作流程图、Worker启动Driver源码解密、Worker启动Executor源码解密等
本課主題 Spark Worker 原理 Worker 启动 Driver 源码鉴赏 Worker 启动 Executor 源码鉴赏 Worker 与 Master 的交互关系 [引言部份:你希望读者 ...
- [Spark内核] 第31课:Spark资源调度分配内幕天机彻底解密:Driver在Cluster模式下的启动、两种不同的资源调度方式源码彻底解析、资源调度内幕总结
本課主題 Master 资源调度的源码鉴赏 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... 资源调度管理 任务调度与资源是通过 DAGScheduler.Ta ...
- [Spark内核] 第33课:Spark Executor内幕彻底解密:Executor工作原理图、ExecutorBackend注册源码解密、Executor实例化内幕、Executor具体工作内幕
本課主題 Spark Executor 工作原理图 ExecutorBackend 注册源码鉴赏和 Executor 实例化内幕 Executor 具体是如何工作的 [引言部份:你希望读者看完这篇博客 ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- [Spark内核] 第29课:Master HA彻底解密
本课主题 Master HA 解析 Master HA 解析源码分享 [引言部份:你希望读者看完这篇博客后有那些启发.学到什么样的知识点] 更新中...... Master HA 解析 生产环境下一般 ...
- [Spark内核] 第30课:Master的注册机制和状态管理解密
本課主題 Master 接收 Worker, Driver, Application Master 处理 Driver 狀态变换 Master 处理 Executor 狀态变换 [引言部份:你希望读者 ...
随机推荐
- Spring的Bean内部方法调用无法使用AOP切面(CacheAble注解失效)
Spring的Bean内部方法调用无法使用AOP切面(CacheAble注解失效) 前言 今天在使用Spring cache的Cacheable注解的过程中遇见了一个Cacheable注解失效的问题, ...
- SharePoint Online Add-in 开发简介
作者:陈希章 发表于 2017年12月22日 在 再谈SharePoint大局观 中我提到了SharePoint开发的一些新的变化,这一篇文章我将讲解SharePoint Add-in开发.其实早在2 ...
- kafak集群安装-转
前言 最近在利用Spark streaming和Kafka构建一个实时的数据分析系统,对图书阅读数据进行分析,做实时推荐.Spark Streaming 模块是对于 Spark Core 的一个扩展, ...
- iOS_应用程序的生命周期
每个iPhone程序都包括唯一一个UIApplication对象,它管理整个程序的生命周期,从载入第一个显示界面開始,而且监听系统事件.程序事件调度整个程序的运行. int main(int argc ...
- 使用Myeclipse为数据表创建hibernate实体对象
hibernate是orm框架的一种,orm即Object Relational Mapping,对象映射关系,其主要作用是将数据库(mysql,mssql,oracle)的对象转换为具体编程语言(如 ...
- 如何解决更新被拒绝,因为远程版本库包含您本地尚不存在的提交。这通常是因为另外 提示:一个版本库已向该引用进行了推送。再次推送前,您可能需要先整合远程变更 提示:(如 'git pull ...')。
不要通过网页提交,通过网页提交一次,然后在终端再次push的时候,会认为网上代码仓库已经被其他地方提交过一次代码,此时会拒绝终端push 这个时候只能是pull,然后才能再次在终端提交. 也就是说,避 ...
- Python:list 和 array的对比以及转换时的注意事项
Python:list 和 array的对比以及转换时的注意事项 zoerywzhou@163.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2017-6-4 ...
- android 网络请求Volley的简单使用
下载到本地jar包或者在线导入,jar地址:链接:http://pan.baidu.com/s/1gf3VZAb 密码:mmye //定义变量 private RequestQueue mQueue= ...
- 【Jenkins】通过ANT构建JMeter任务时提示找不到jtl文件时的解决方法
- Swift tableview自带的刷新控件
import UIKit class ViewController: UIViewController,UITableViewDelegate,UITableViewDataSource { let ...