深入学习Heritrix---解析CrawlController(转)
当我们以Web UI方式使用Heritrix时,点击任务开始(start)按钮时,Heritrix就开始了它的爬取工作.但它的内部
执行流程是怎样的呢?别急,下面将慢慢道来.
(一)CrawlJobHandler
当点击任务开始(start)按钮时,将执行它的startCrawler()方法:
if(sAction.equalsIgnoreCase("start"))
{
// Tell handler to start crawl job
handler.startCrawler();
}
再来看看startCrawler()方法的执行:
public class CrawlJobHandler implements CrawlStatusListener {
public void startCrawler() {
running = true;
if (pendingCrawlJobs.size() > 0 && isCrawling() == false) {
// Ok, can just start the next job
startNextJob();
}
}
protected final void startNextJob() {
synchronized (this) {
if(startingNextJob != null) {
try {
startingNextJob.join();
} catch (InterruptedException e) {
e.printStackTrace();
return;
}
}
startingNextJob = new Thread(new Runnable() {
public void run() {
startNextJobInternal();
}
}, "StartNextJob");
//当前任务线程开始执行
startingNextJob.start();
}
}
protected void startNextJobInternal() {
if (pendingCrawlJobs.size() == 0 || isCrawling()) {
// No job ready or already crawling.
return;
}
//从待处理的任务列表取出一个任务
this.currentJob = (CrawlJob)pendingCrawlJobs.first();
assert pendingCrawlJobs.contains(currentJob) :
"pendingCrawlJobs is in an illegal state";
//从待处理列表中删除
pendingCrawlJobs.remove(currentJob);
try {
this.currentJob.setupForCrawlStart();
// This is ugly but needed so I can clear the currentJob
// reference in the crawlEnding and update the list of completed
// jobs. Also, crawlEnded can startup next job.
this.currentJob.getController().addCrawlStatusListener(this);
// now, actually start
//控制器真正开始执行的地方
this.currentJob.getController().requestCrawlStart();
} catch (InitializationException e) {
loadJob(getStateJobFile(this.currentJob.getDirectory()));
this.currentJob = null;
startNextJobInternal(); // Load the next job if there is one.
}
}
}
由以上代码不难发现整个流程如下:
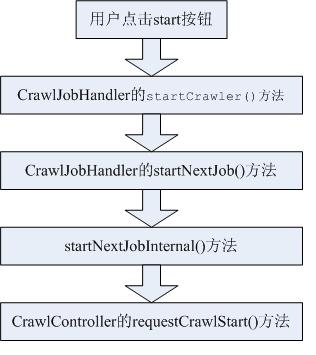
可以看出,最终将启动CrawlController的requestCrawlStart()方法.
(二)CrawlController
该类是一次抓取任务中的核心组件。它将决定整个抓取任务的开始和结束.
先看看它的源代码:
package org.archive.crawler.framework;
public class CrawlController implements Serializable, Reporter {
// key subcomponents which define and implement a crawl in progress
private transient CrawlOrder order;
private transient CrawlScope scope;
private transient ProcessorChainList processorChains;
private transient Frontier frontier;
private transient ToePool toePool;
private transient ServerCache serverCache;
// This gets passed into the initialize method.
private transient SettingsHandler settingsHandler;
}
CrawlOrder:它保存了对该次抓取任务中order.xml的属性配置。
CrawlScope:决定当前抓取范围的一个组件。
ProcessorChainList:从名称上可知,其表示处理器链。
Frontier:它是一个URL的处理器,决定下一个要被处理的URL是什么。
ToePool:它表示一个线程池,管理了所有该抓取任务所创建的子线程。
ServerCache:它表示一个缓冲池,保存了所有在当前任务中,抓取过的Host名称和Server名称。
在构造 CrawlController实例,需要先做以下工作:
(1)首先构造一个XMLSettingsHandler对象,将order.xml内的属性信息装入,并调用它的initialize方法进行初始化。
(2)调用CrawlController构造函数,构造一个CrawlController实例
(3)调用CrawlController的initilize(SettingsHandler)方法,初始化CrawlController实例。其中,传入的参数就是
在第一步里构造的XMLSettingsHandler实例。
(4 )当上述3步完成后,CrawlController就具备了运行的条件。此时,只需调用它的requestCrawlStart()方法,就
可以启动线程池和Frontier,然后开始不断的抓取网页。
先来看看initilize(SettingsHandler)方法:
public void initialize(SettingsHandler sH)
throws InitializationException {
sendCrawlStateChangeEvent(PREPARING, CrawlJob.STATUS_PREPARING); this.singleThreadLock = new ReentrantLock();
this.settingsHandler = sH; //从XMLSettingsHandler中取出Order
this.order = settingsHandler.getOrder(); this.order.setController(this);
this.bigmaps = new Hashtable<String,CachedBdbMap<?,?>>();
sExit = "";
this.manifest = new StringBuffer();
String onFailMessage = "";
try {
onFailMessage = "You must set the User-Agent and From HTTP" +
" header values to acceptable strings. /n" +
" User-Agent: [software-name](+[info-url])[misc]/n" +
" From: [email-address]/n"; //检查了用户设定的UserAgent等信息,看是否符合格式
order.checkUserAgentAndFrom(); onFailMessage = "Unable to setup disk";
if (disk == null) {
setupDisk(); //设定了开始抓取后保存文件信息的目录结构
} onFailMessage = "Unable to create log file(s)";
//初始化了日志信息的记录工具
setupLogs(); onFailMessage = "Unable to test/run checkpoint recover";
this.checkpointRecover = getCheckpointRecover();
if (this.checkpointRecover == null) {
this.checkpointer =
new Checkpointer(this, this.checkpointsDisk);
} else {
setupCheckpointRecover();
}
onFailMessage = "Unable to setup bdb environment."; //初始化使用Berkley DB的一些工具
setupBdb();
onFailMessage = "Unable to setup statistics";
setupStatTracking();
onFailMessage = "Unable to setup crawl modules";
//初始化了Scope、Frontier以及ProcessorChain
setupCrawlModules();
} catch (Exception e) {
String tmp = "On crawl: "
+ settingsHandler.getSettingsObject(null).getName() + " " +
onFailMessage;
LOGGER.log(Level.SEVERE, tmp, e);
throw new InitializationException(tmp, e);
}
Lookup.getDefaultCache(DClass.IN).setMaxEntries(1);
//dns.getRecords("localhost", Type.A, DClass.IN); //实例化线程池
setupToePool();
setThresholds();
reserveMemory = new LinkedList<char[]>();
for(int i = 1; i < RESERVE_BLOCKS; i++) {
reserveMemory.add(new char[RESERVE_BLOCK_SIZE]);
}
}
可以看出在initilize()方法中主要做一些初始化工作,但这些对于Heritrix的运行是必需的.
再来看看CrawlController的核心,requestCrawlStart()方法:
public void requestCrawlStart() {
//初始化处理器链
runProcessorInitialTasks();
sendCrawlStateChangeEvent(STARTED, CrawlJob.STATUS_PENDING);
String jobState;
state = RUNNING;
jobState = CrawlJob.STATUS_RUNNING;
sendCrawlStateChangeEvent(this.state, jobState);
// A proper exit will change this value.
this.sExit = CrawlJob.STATUS_FINISHED_ABNORMAL;
Thread statLogger = new Thread(statistics);
statLogger.setName("StatLogger");
//开始日志线程
statLogger.start();
//启运Frontier,抓取工作开始
frontier.start();
}
可以看出,做了那么多工作,最终将启动Frontier的start方法,而Frontier将为线程池的线程提供URI,真正开始
抓取任务.至此,抓取任务开始.
主要参考:开发自己的搜索引擎—Lucene 2.0+Heritrix
深入学习Heritrix---解析CrawlController(转)的更多相关文章
- Delphi之通过代码示例学习XML解析、StringReplace的用法(异常控制 good)
*Delphi之通过代码示例学习XML解析.StringReplace的用法 这个程序可以用于解析任何合法的XML字符串. 首先是看一下程序的运行效果: 以解析这样一个XML的字符串为例: <? ...
- 深入学习Python解析并解密PDF文件内容的方法
前面学习了解析PDF文档,并写入文档的知识,那篇文章的名字为深入学习Python解析并读取PDF文件内容的方法. 链接如下:https://www.cnblogs.com/wj-1314/p/9429 ...
- 分布式深度学习DDL解析
分布式深度学习DDL解析 一.概述 给一个庞大的GPU集群,在实际的应用中,现有的大数据调度器会导致长队列延迟和低的性能,该文章提出了Tiresias,即一个GPU集群的调度器,专门适应分布式深度学习 ...
- python学习(解析python官网会议安排)
在学习python的过程中,做练习,解析https://www.python.org/events/python-events/ HTML文件,输出Python官网发布的会议时间.名称和地点. 对ht ...
- JavaScript自我学习之解析与执行
如果想要学好JavaScript那么我们首先必须要知道浏览器JavaScript引擎是如何解释执行JavaScript代码的,作为一名菜鸟,从自己学习JavaScript的过程来说,真心觉得不了解这些 ...
- 深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应 ...
- React.js深入学习详细解析
今天,继续深入学习react.js. 目录: 一.JSX介绍 二.React组件生命周期详解 三.属性.状态的含义和用法 四.React中事件的用法 五.组件的协同使用 六.React中的双向绑定 ...
- Delphi之通过代码示例学习XML解析、StringReplace的用法
这个程序可以用于解析任何合法的XML字符串. 首先是看一下程序的运行效果: 以解析这样一个XML的字符串为例: <?xml version="1.0" encoding=&q ...
- 【javaweb学习】解析XML
XML解析方式有两种 dom:Document Object Model文档对象模型,是w3c组织推荐的解析方式 sax:Simple Api XML不是官方标准,但它是XML社区实际上的标准,几乎所 ...
随机推荐
- mvc5 _ViewStart.cshtml 模板页如何定义
1._Viewstart.cshtml是一个在呈现View文件的时候的启动文件,会在所有View(.cshtml)被执行之前执行,主要用于一些不方便或不能在母版(_Layout.cshtml)中进行的 ...
- Hadoop InputFormat OutputFormat
InputFormat有两个抽象方法: getSplits createRecordReader InputSplits 将数据按照Split进行切分,一个Split分给一个task执行. ...
- web.xml中servlet初始化参数的设置
<context-param><param-name>param1</param-name><param-value>value1</param- ...
- iOS开发--CoreGraphics简单绘图
一.导入coreGraphics.framework 二.绘制图形 1.绘制矩形 ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // 绘制矩形 - (v ...
- wordpress可视化编辑器的开启/关闭
这个可视化编辑器还真是有些难找,在后台菜单“用户”->"我的个人资料" 对以下勾选即可
- css 射线实现方法
一个斜的四边形 .top_ad_out::before { content: ''; position: absolute; z-index: -1; width: 336px; height: 25 ...
- javaScript初学者易错点
大家好,这是我在博客园写的第一篇博文.作为一名前端开发初学者,由于经验不足,水平有限,在做项目的过程中总会遇到这样或那样的问题,每每这时候,我都比较喜欢到博客园这里来寻求解决方案,结果也总是能找到满意 ...
- HttpClient 4.x 执行网站登录并抓取网页的代码
HttpClient 4.x 的 API 变化还是很大,这段代码可用来执行登录过程,并抓取网页. HttpClient API 文档(4.0.x), HttpCore API 文档(4.1) pack ...
- box-sizing的学习和认识
先上自己写的DEMO代码 <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> ...
- Python学习之类
class Person: def __init__(self, name): self.name = name def sayHi(self): print('Hello, my name is'+ ...