scrapy框架之shell
scrapy shell
scrapy shell是一个交互式shell,您可以在其中快速调试 scrape 代码,而不必运行spider。它本来是用来测试数据提取代码的,但实际上您可以使用它来测试任何类型的代码,因为它也是一个常规的Python shell。
shell用于测试xpath或css表达式,并查看它们是如何工作的,以及它们从您试图抓取的网页中提取的数据。它允许您在编写spider时交互地测试表达式,而不必运行spider来测试每个更改。
一旦你熟悉了 Scrapy Shell,你就会发现它是开发和调试蜘蛛的宝贵工具。
配置shell
如果你有 IPython 安装后,scrapy shell将使用它(而不是标准的python控制台)。这个 IPython 控制台功能更强大,提供智能自动完成和彩色输出等功能。
通过Scrapy的设置,您可以将其配置为使用 ipython , bpython 或标准 python shell,无论安装了什么。这是通过设置 SCRAPY_PYTHON_SHELL 环境变量;或通过在 scrapy.cfg ;
[settings]
shell = bpython
启动shell
使用 shell 命令如下:
scrapy shell <url> # <url>是要抓取的url
shell 也适用于本地文件。如果你想玩一个网页的本地副本,这很方便。 shell 了解本地文件的以下语法:
# UNIX-style
scrapy shell ./path/to/file.html
scrapy shell ../other/path/to/file.html
scrapy shell /absolute/path/to/file.html # File URI
scrapy shell file:///absolute/path/to/file.html
使用相对文件路径时,请使用 ./ (或) ../ 表示文件存储的路径
scrapy shell ./index.html

使用shell
scrappyshell只是一个普通的python控制台(或者 IPython 控制台,如果你有它的话),它提供一些额外的快捷功能,以方便。
可用的快捷方式
shelp() -打印有关可用对象和快捷方式列表的帮助 fetch(url[, redirect=True]) - 从给定URL获取一个新的响应,并相应地更新所有相关对象。您可以选择请求HTTP 3xx重定向,以避免传递 fetch(request) -从给定的请求中获取新的响应,并相应地更新所有相关对象。 view(response) -在本地Web浏览器中打开给定的响应以进行检查。这将增加一个 <base> tag 到响应主体,以便外部链接(如图像和样式表)正确显示。但是请注意,这将在您的计算机中创建一个临时文件,该文件不会自动删除。
可用的srapy对象
Scrapy Shell自动从下载的页面创建一些方便的对象,例如 Response 对象与 Selector 对象(用于HTML和XML内容)。
这些对象是:
Shell会话示例
下面是一个典型的shell会话的例子,我们从抓取https://scrappy.org页面开始,然后继续抓取https://reddit.com页面。最后,我们修改(reddit)请求方法来发布和重新获取它,得到一个错误。我们通过在Windows中键入ctrl-d(在UNIX系统中)或ctrl-z来结束会话。
请记住,在这里提取的数据在您尝试时可能不相同,因为这些页面不是静态的,在您测试时可能已经更改了。这个例子的唯一目的是让您熟悉下脚料外壳的工作原理。
首先,我们发射炮弹:
C:\Users\admin>scrapy shell www.scrapy.org --nolog
然后,shell获取URL(使用scrapy下载器)并打印可用对象和有用快捷方式的列表(您会注意到这些行都以 [s] 前缀):
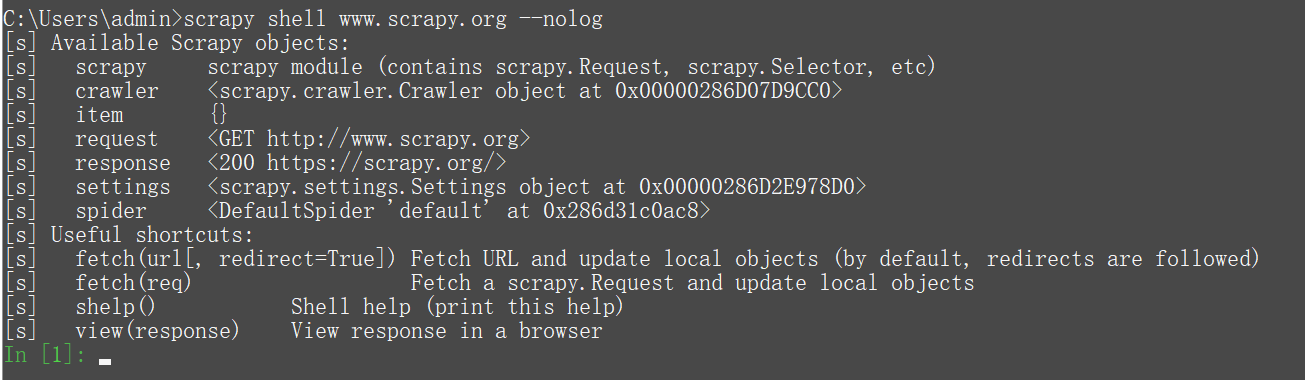
之后我们开始使用对象:
In [1]: response.xpath('//title/text()').get() # 获取网页title
Out[1]: 'Scrapy | A Fast and Powerful Scraping and Web Crawling Framework'
In [5]: fetch('https://www.osgeo.cn/scrapy/topics/shell.html') # 切换网址
In [6]: response.xpath('//title//text()').get() # 获取网页title
Out[6]: 'Scrapy shell — Scrapy 1.7.0 文档'
In [7]: request = request.replace(method='post') # 改变request的请求方式为post
In [8]: fetch(request) # 从新请求上面的网址
In [9]: response.status # 响应状态码
Out[9]: 405
In [10]: from pprint import pprint # 导入模块pprint
In [11]: pprint(response.headers) # 打印请求头
{b'Content-Type': [b'text/html'],
b'Date': [b'Sat, 10 Aug 2019 04:08:19 GMT'],
b'Server': [b'nginx/1.10.3']}
In [12]: pprint(type(response.headers)) # 打印类型
<class 'scrapy.http.headers.Headers'>
从spiders调用shell来检查响应
有时,您希望检查在您的蜘蛛的某个点上正在处理的响应,如果只是检查您期望的响应是否到达那里的话。
这可以通过使用 scrapy.shell.inspect_response 功能。
下面是一个例子,说明如何从您的蜘蛛中命名它:
import scrapy class MySpider(scrapy.Spider):
name = "myspider"
start_urls = [
"http://example.com",
"http://example.org",
"http://example.net",
] def parse(self, response):
# We want to inspect one specific response.
if ".org" in response.url:
from scrapy.shell import inspect_response
inspect_response(response, self) # Rest of parsing code.
当你运行蜘蛛时,你会得到类似的东西:
2014-01-23 17:48:31-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.com> (referer: None)
2014-01-23 17:48:31-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.org> (referer: None)
[s] Available Scrapy objects:
[s] crawler <scrapy.crawler.Crawler object at 0x1e16b50>
... >>> response.url
'http://example.org'
然后,您可以检查提取代码是否工作:
>>> response.xpath('//h1[@class="fn"]')
[]
不,不是这样的。所以您可以在Web浏览器中打开响应,看看它是否是您期望的响应:
>>> view(response)
True
最后,单击ctrl-d(或在Windows中单击ctrl-z)退出shell并继续爬网:
>>> ^D
2014-01-23 17:50:03-0400 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://example.net> (referer: None)
...
请注意,您不能使用 fetch 这里的快捷方式,因为报废的引擎被shell挡住了。然而,当你离开shell后,蜘蛛会继续在它停止的地方爬行,如上图所示。
示例:
# -*- coding: utf-8 -*-
import scrapy class DowloadTaobaoSpider(scrapy.Spider):
name = 'dowload_taobao'
allowed_domains = ['www.taobao.com']
start_urls = ['http://www.taobao.com/'] def parse(self, response):
if '.com' in response.url:
from scrapy.shell import inspect_response
inspect_response(response,self)
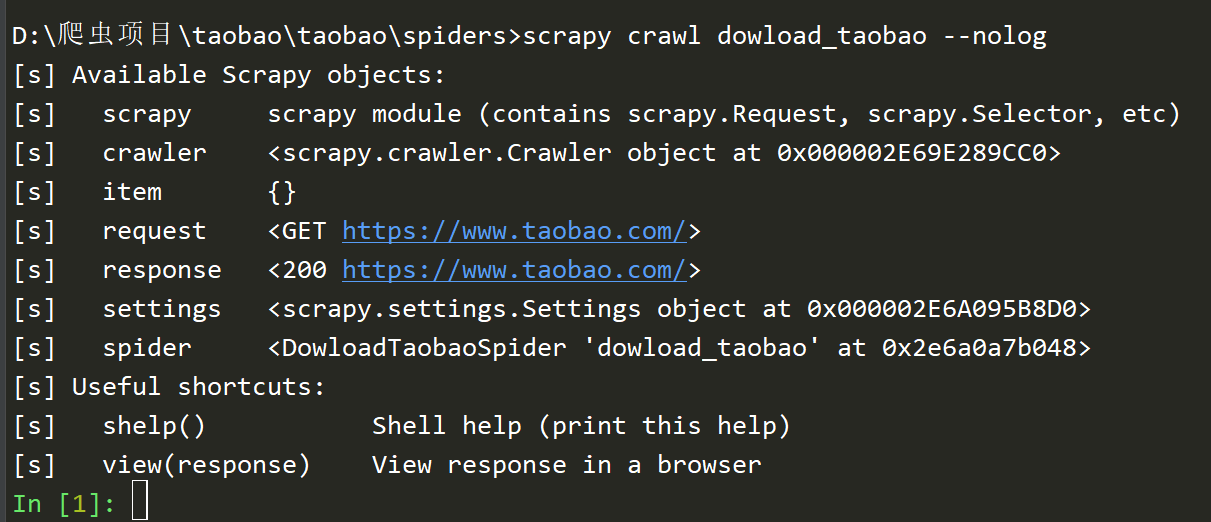

scrapy框架之shell的更多相关文章
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- python scrapy框架爬虫遇到301
1.什么是状态码301 301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一.如果可能,拥有链接编 ...
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- Scrapy 框架简介
Scrapy 框架 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的 ...
- 爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序 下面我们尝试爬取全书网中网游动漫类小说的书籍信息. 一.准备阶段 明确一下爬虫页面分析的思路: 对于书籍列表页:我们需要知道打开单本书籍 ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- 解读Scrapy框架
Scrapy框架基础:Twsited Scrapy内部基于事件循环的机制实现爬虫的并发.原来: url_list = ['http://www.baidu.com','http://www.baidu ...
随机推荐
- codeforce 839d.winter is here
题意:如果一个子序列的GCD为1,那么这个子序列的价值为0,否则子序列价值为子序列长度*子序列GCD 给出n个数,求这n个数所有子序列的价值和 题解:首先得想到去处理量比较少的数据的贡献,这里处理每个 ...
- 【转载】springboot启动报错(Unable to start web server; nested exception is org.springframework.context.ApplicationContextException: Unable to start ServletWebServerApplicationContext due to missing ServletWe)
SpringBoot启动时的异常信息如下: 1 "C:\Program Files\Java\jdk1.8.0_161\bin\java" ......... com.fangxi ...
- win10 amd显卡开机黑屏很久
转载自:https://jingyan.baidu.com/article/3c48dd34844e0ce10ae35865.html 升级win10后,使用a卡的小伙伴应该会大为恼火,开机竟然需要黑 ...
- Bminer
Bminer https://www.bminer.me/zh/ Bminer: When Crypto-mining Made Fast¶ Bminer是一款为NVIDIA和AMD GPU深度优化的 ...
- 美化linux客户端zsh和oh-my-zsh
linuxbashzshoh-my-zsh 一.安装zsh 二.安装oh-my-zsh 一.安装zsh 安装 zsh yum -y install zsh 替换默认shell chsh -s /bin ...
- 关于BOM的一些基本知识以及表格的操作
首先先了解什么是BOM? BOM:英文全称Browser Object Model,即浏览器对象模型.浏览器页面初始化时,会在内存创建一个全局对象,用来描述当前窗口的属性和状态,这个全局对象被称为浏览 ...
- DOM树节点关系
DOM是JS中专门操作HTML页面内容的 他的三种基本使用方法是: 1. document.getElementById(''): ——>选取html页面中带有Id的属性名: 2.docum ...
- 阿里P7浅谈Java的Spring Bean
1.简单java 类,实现 Serializable 接口 package com.curtis.bean;import java.io.Serializable;@SuppressWarnings( ...
- go语言的局部变量在堆上还是栈上?
在讨论之前,先看如下代码: type treeNode struct { value int left, right *treeNode } func createNode(value int) *t ...
- Windows工作原理
Windows工作原理中心思想 Windows工作原理的中心思想就是“动态链接”概念.Windows自身带有一大套函数,应用程序就是通过调用这些函数来实现它的用户界面和在屏幕上显示文本与图形的.这些函 ...