python scrapy框架爬虫遇到301
1.什么是状态码301
301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
比如,我们访问 http://www.baidu.com 会跳转到 https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
注意: 301请求是可以缓存的, 即通过看status code,可以发现后面写着from cache。
或者你把你的网页的名称从php修改为了html,这个过程中,也会发生永久重定向。
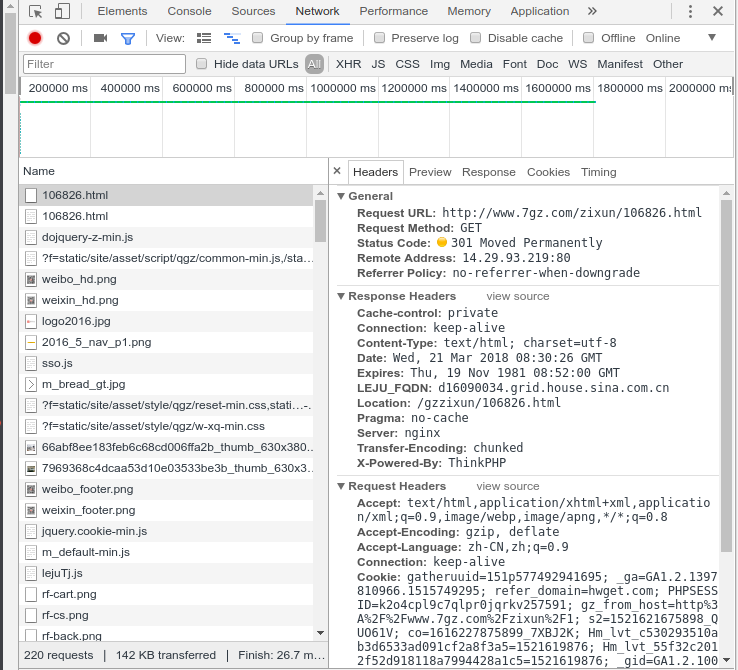
2.如何处理
首先我们可以使用scrapy框架中的 scrapy shell 进行测试
跳转前后的url如果是一致的,我们在终端命令行输入 :
scrapy shell http://www.7gz.com/gzzixun/106826.html
观察到log中信息包含:
[scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.7gz.com/gzzixun/106826.html> (referer: None)
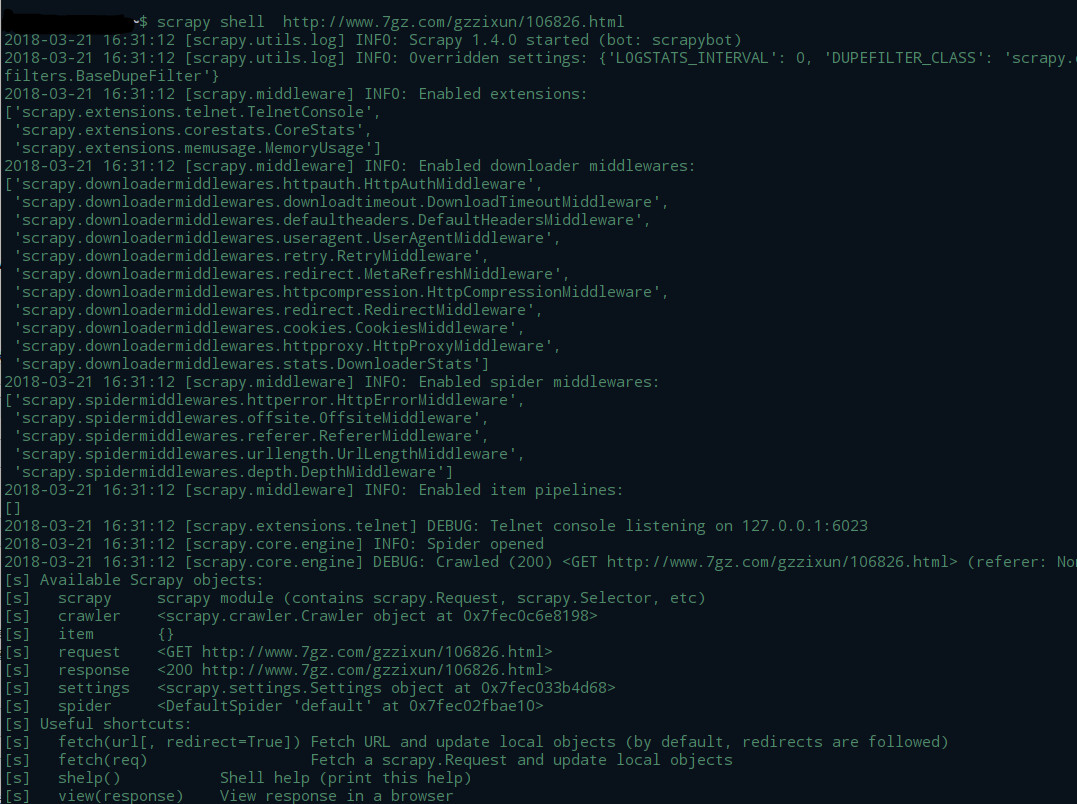
说明我们可以正常访问这个网址,只是跳转网址未改变,状态码是301。
这个时候我们需要在scrapy框架中的 settings.py 文件里添加
HTTPERROR_ALLOWED_CODES = [301]
这样再运行就不会产生301的log信息了,爬虫可以正常运行。
python scrapy框架爬虫遇到301的更多相关文章
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Scrapy框架-----爬虫
说明:文章是本人读了崔庆才的Python3---网络爬虫开发实战,做的简单整理,希望能帮助正在学习的小伙伴~~ 1. 准备工作: 安装Scrapy框架.MongoDB和PyMongo库,如果没有安装, ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- Python scrapy框架
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
随机推荐
- js中的回调函数的理解
一,常见的但是不是特别注意的回调方法. 1.1,ajax $.ajax({ url:"test.json", type: "GET", data: {usern ...
- thinkphp5源码解析(2)控制器
入口文件index.php: // 定义应用目录 define('APP_PATH', __DIR__ . '/../application/'); // 加载框架引导文件 require __DIR ...
- SpringBean基础装配
首先,让我们先对Bean进行理解:什么是Bean,为什么要有Bean,如何装配Bean: 1,什么是Bean? Bean你可以看成是一个组件,在 ...
- POJ - 2828
题意 输入队伍长度n 接下来n行,a,b 表示b插在队伍的a处 求队伍最后的情况 题解 刚开始并不知道要用线段树,经大佬点悟,发现最后插入的位置就是对应的a.所以可以从后往前依次插入,每次的位置pos ...
- [BZOJ1003] [ZJOI2006] 物流运输trans (最短路 & dp)
Description 物流公司要把一批货物从码头A运到码头B.由于货物量比较大,需要n天才能运完.货物运输过程中一般要转停好几个码头.物流公司通常会设计一条固定的运输路线,以便对整个运输过程实施严格 ...
- Java求最大公约数和最小公倍数
最大公约数(Greatest Common Divisor(GCD)) 基本概念 最大公因数,也称最大公约数.最大公因子,指两个或多个整数共有约数中最大的一个.a,b的最大公约数记为(a,b),同样的 ...
- 初识 .net core和vs code
定义:什么是.net core? .net core是一个跨各个不同操作系统运行的平台.时至今日,windows上.net framework已经发展成熟,可以用来开发windows平台下的几乎所有应 ...
- MinGW安装和使用
P.S.安装MinGW主要是code blocks 编译出现了这个问题: ERROR: You need to specify a debugger program in the debuggers' ...
- nodejs辅助前台开发系列(1) 搭建简单HTML开发环境
搭建简单的html开发环境一般需要解决两个问题: 文本编辑器 WebServer集成 在文本编辑器选择上,VS Code 无疑是一匹黑马,谁用谁知道.WebServer集成nodejs对前端来说最为友 ...
- java接口----继承(实现)方法
文中"实现"一词特指接口的继承. 一个类实现多个接口时,不能出现同名的默认方法. 一个类既要实现接口又要继承抽象类,先继承后实现. 一个抽象类可以继承多个接口(implements ...