Lasso回归的坐标下降法推导
目标函数
Lasso相当于带有L1正则化项的线性回归。先看下目标函数:RSS(w)+λ∥w∥1=∑Ni=0(yi−∑Dj=0wjhj(xi))2+λ∑Dj=0∣wj∣RSS(w)+λ∥w∥1=∑i=0N(yi−∑j=0Dwjhj(xi))2+λ∑j=0D∣wj∣ RSS(w)+\lambda \Vert w\Vert_1=\sum_{i=0}^{N}(y_i-\sum_{j=0}^D{w_jh_j(x_i)})^2+\lambda \sum_{j=0}^{D}|w_j| RSS(w)+λ∥w∥1=∑i=0N(yi−∑j=0Dwjhj(xi))2+λ∑j=0D∣wj∣
这个问题由于正则化项在零点处不可求导,所以使用非梯度下降法进行求解,如坐标下降法或最小角回归法。
坐标下降法
本文介绍坐标下降法。
坐标下降算法每次选择一个维度进行参数更新,维度的选择可以是随机的或者是按顺序。
当一轮更新结束后,更新步长的最大值少于预设阈值时,终止迭代。
下面分为两部求解
RSS偏导
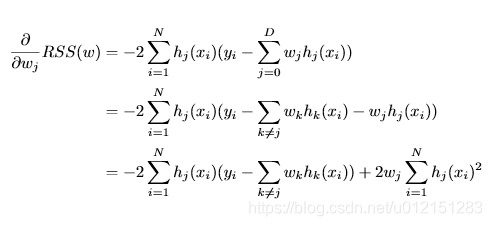
下面做一下标记化简
ρj=∑Ni=1hj(xi)(yi−∑k≠jwkhk(xi))ρj=∑i=1Nhj(xi)(yi−∑k≠jwkhk(xi)) \rho_j=\sum_{i=1}^Nh_j(x_i)(y_i-\sum_{k \neq j }w_kh_k(x_i))
ρj=∑i=1Nhj(xi)(yi−∑k̸=jwkhk(xi))
zj=∑Ni=1hj(xi)2zj=∑i=1Nhj(xi)2 z_j=\sum_{i=1}^N h_j(x_i)^2
zj=∑i=1Nhj(xi)2
上式化简为∂∂wjRSS(w)=−2ρj+2wjzj∂∂wjRSS(w)=−2ρj+2wjzj \frac{\partial}{\partial w_j}RSS(w)=-2\rho_j+2w_jz_j
∂wj∂RSS(w)=−2ρj+2wjzj
正则项偏导
次梯度方法(subgradient method)是传统的梯度下降方法的拓展,用来处理不可导的凸函数。
λ∂wj∣wj∣=⎧⎩⎨⎪⎪−λ[−λ,λ]λwj<0wj=0wj>0λ∂wj∣wj∣={−λwj<0[−λ,λ]wj=0λwj>0 \lambda \partial_{w_j}|w_j|=\begin{cases}-\lambda&w_j<0\\[-\lambda,\lambda]& w_j=0\\\lambda&w_j>0\end{cases}

λ∂wj∣wj∣=⎩⎪⎨⎪⎧−λ[−λ,λ]λwj<0wj=0wj>0
整体偏导数
λ∂wj[lasso cost]=2zjwj−2ρj+⎧⎩⎨⎪⎪−λ[−λ,λ]λwj<0wj=0wj>0=⎧⎩⎨⎪⎪2zjwj−2ρj−λ[−2ρj−λ,−2ρj+λ]2zjwj−2ρj+λwj<0wj=0wj>0λ∂wj[lasso cost]=2zjwj−2ρj+{−λwj<0[−λ,λ]wj=0λwj>0={2zjwj−2ρj−λwj<0[−2ρj−λ,−2ρj+λ]wj=02zjwj−2ρj+λwj>0 \lambda \partial_{w_j}\text{[lasso cost]}= 2z_jw_j-2\rho_j+\begin{cases}-\lambda&w_j<0\\[-\lambda,\lambda]& w_j=0\\\lambda&w_j>0\end{cases}\\=\begin{cases}2z_jw_j-2\rho_j-\lambda&w_j<0\\[-2\rho_j-\lambda,-2\rho_j+\lambda]& w_j=0\\2z_jw_j-2\rho_j+\lambda&w_j>0\end{cases}
λ∂wj[lasso cost]=2zjwj−2ρj+⎩⎪⎨⎪⎧−λ[−λ,λ]λwj<0wj=0wj>0=⎩⎪⎨⎪⎧2zjwj−2ρj−λ[−2ρj−λ,−2ρj+λ]2zjwj−2ρj+λwj<0wj=0wj>0
要想获得最有解,令
λ∂wj[lasso cost]=0λ∂wj[lasso cost]=0 \lambda \partial_{w_j}\text{[lasso cost]}=0
λ∂wj[lasso cost]=0。
解得,
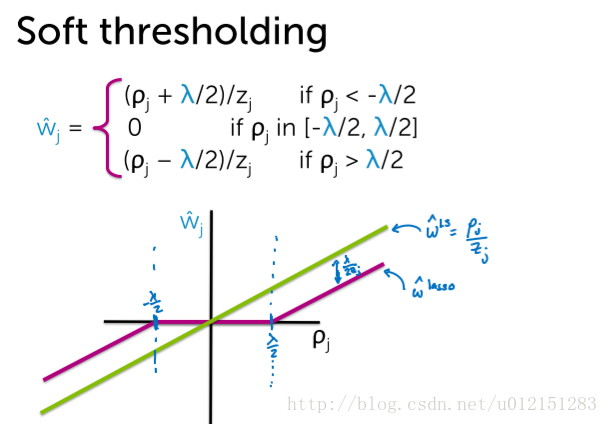
wˆj=⎧⎩⎨⎪⎪(ρj+λ/2)/zj0(ρj−λ/2)/zjρj<−λ/2ρj in [−λ/2,λ/2]ρj>λ/2w^j={(ρj+λ/2)/zjρj<−λ/20ρj in [−λ/2,λ/2](ρj−λ/2)/zjρj>λ/2 \hat w_j= \begin{cases}(\rho_j+\lambda/2)/z_j&\rho_j<-\lambda/2\\0& \rho_j\text{ in }[-\lambda/2,\lambda/2]\\(\rho_j-\lambda/2)/z_j&\rho_j>\lambda/2\end{cases}
w^j=⎩⎪⎨⎪⎧(ρj+λ/2)/zj0(ρj−λ/2)/zjρj<−λ/2ρj in [−λ/2,λ/2]ρj>λ/2
伪代码
预计算zj=∑Ni=1hj(xi)2zj=∑i=1Nhj(xi)2 z_j=\sum_{i=1}^N h_j(x_i)^2
zj=∑i=1Nhj(xi)2
初始化参数w(全0或随机)
循环直到收敛:
for j = 0,1,…D
$ \space \space\space\space\rho_j=\sum_{i=1}^Nh_j(x_i)(y_i-\sum_{k \neq j }w_kh_k(x_i))$
update wj update wj \space \space\space\space update\space w_jupdate wj
选择变化幅度最大的维度进行更新
概率解释
拉普拉斯分布
随机变量X∼Laplace(μ,b)X∼Laplace(μ,b) X\sim Laplace(\mu,b)
X∼Laplace(μ,b),其中μμ \mu
μ是位置参数,b>0b>0 b>0
b>0是尺度参数。
概率密度函数为
f(x∣μ,b)=12bexp(−∣x−μ∣b)f(x∣μ,b)=12bexp(−∣x−μ∣b) f(x|\mu,b)=\frac{1}{2b}exp(-\frac{|x-\mu|}{b})
f(x∣μ,b)=2b1exp(−b∣x−μ∣)
MAP推导
假设ϵi∼N(0,σ2)ϵi∼N(0,σ2) \epsilon_i\sim N(0,\sigma^2)
ϵi∼N(0,σ2),wi∼Laplace(0,1λ)wi∼Laplace(0,1λ) w_i\sim Laplace(0,\frac{1}{\lambda})
wi∼Laplace(0,λ1)
等价于
Lasso回归的坐标下降法推导的更多相关文章
- 坐标下降法(coordinate descent method)求解LASSO的推导
坐标下降法(coordinate descent method)求解LASSO推导 LASSO在尖点是singular的,因此传统的梯度下降法.牛顿法等无法使用.常用的求解算法有最小角回归法.coor ...
- Lasso回归算法: 坐标轴下降法与最小角回归法小结
前面的文章对线性回归做了一个小结,文章在这: 线性回归原理小结.里面对线程回归的正则化也做了一个初步的介绍.提到了线程回归的L2正则化-Ridge回归,以及线程回归的L1正则化-Lasso回归.但是对 ...
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- 通俗易懂--岭回归(L2)、lasso回归(L1)、ElasticNet讲解(算法+案例)
1.L2正则化(岭回归) 1.1问题 想要理解什么是正则化,首先我们先来了解上图的方程式.当训练的特征和数据很少时,往往会造成欠拟合的情况,对应的是左边的坐标:而我们想要达到的目的往往是中间的坐标,适 ...
- 岭回归和lasso回归(转)
回归和分类是机器学习算法所要解决的两个主要问题.分类大家都知道,模型的输出值是离散值,对应着相应的类别,通常的简单分类问题模型输出值是二值的,也就是二分类问题.但是回归就稍微复杂一些,回归模型的输出值 ...
- Lasso回归
Lasso 是一个线性模型,它给出的模型具有稀疏的系数(sparse coefficients).它在一些场景中是很有用的,因为它倾向于使用较少参数的情况,能够有效减少给定解决方案所依赖变量的个数.因 ...
- 【机器学习】正则化的线性回归 —— 岭回归与Lasso回归
注:正则化是用来防止过拟合的方法.在最开始学习机器学习的课程时,只是觉得这个方法就像某种魔法一样非常神奇的改变了模型的参数.但是一直也无法对其基本原理有一个透彻.直观的理解.直到最近再次接触到这个概念 ...
- 岭回归&Lasso回归
转自:https://blog.csdn.net/dang_boy/article/details/78504258 https://www.cnblogs.com/Belter/p/8536939. ...
- 线性回归——lasso回归和岭回归(ridge regression)
目录 线性回归--最小二乘 Lasso回归和岭回归 为什么 lasso 更容易使部分权重变为 0 而 ridge 不行? References 线性回归很简单,用线性函数拟合数据,用 mean squ ...
随机推荐
- sql将查询结果的某个字段赋值给另一个字段
Update a set a.NickName=b.name FROM AccountsInfo a, TT b where a.UserID=b.userId 必须要有关联的两个表
- 云端的ABAP Restful服务开发
愉快的暑假结束了,今天是小朋友新学期开学后的第一个周日,不知道各位家长是否和小朋友们一起,已经适应了新学期的生活了么? Jerry从少的可怜的属于自己的周末时光挤了一小部分时间出来,写了这篇文章. J ...
- centos8 安装 mongodb 4.2 (使用yum)
1.制作 repo 文件 参考 mongodb 官方的安装文档,使用下面的脚本制作Yum库安装mongodb4.2,但安装过程提示 "Failed to synchronize cache ...
- YUSS Round 1
YUSS Round 1 A. 国庆快乐 签到题. #include<bits/stdc++.h> using namespace std; int main() { printf(&qu ...
- java基础(3)---Scanner键盘输入
1.使用scanner类: import java.util.Scanner; class ScannerTest{ public static void main( String[] args){ ...
- hihocoder 1931 最短管道距离
描述 在一张2D地图上有N座城市,坐标依次是(X1, Y1), (X2, Y2), ... (XN, YN). 现在H国要修建一条平行于X轴的天然气主管道.这条管道非常长,可以认为是一条平行于X轴的直 ...
- go mod使用
GO111MODULE 有三个值:off, on和auto(默认值) GO111MODULE=off,go命令行将不会支持module功能,寻找依赖包的方式将会沿用旧版本那种通过vendor目录或者G ...
- 0017SpringBoot注册Servlet三大组件(Servlet、Filter、Listener)
由于SpringBoot默认是以jar包的形式启动嵌入式servlet容器来启动SpringBoot的web应用,所以没有web.xml文件,那么如何配置Servlet.Filter.Listener ...
- 高性能集群(HPC
串行计算与并行计算1.串行计算串行计算是指在单个计算机(拥有单个中央独立单元) 上执行软件写操作.CPU 逐个使用一系列指令解决问题.为了加快处理速度,在原有的串行计算的基础上演变出并行计算2.并行计 ...
- Git---报错:git Please move or remove them before you can merge 解决方案
场景: 当前在本地仓库lucky,因修改了123.txt的文件内容,需要将lucky分支push到远程Git库,在push前有其他的同事已删除了远程Git库中的123.txt文件.因此这时就产生了远程 ...